 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Large Language Models Meet Law: Dual-Lens Taxonomy, Technical Advances, and Ethical Governance
Jul 10, 2025This paper establishes the first comprehensive review of Large Language Models (LLMs) applied within the legal domain. It pioneers an innovative dual lens taxonomy that integrates legal reasoning frameworks and professional ontologies to systematically unify historical research and contemporary breakthroughs. Transformer-based LLMs, which exhibit emergent capabilities such as contextual reasoning and generative argumentation, surmount traditional limitations by dynamically capturing legal semantics and unifying evidence reasoning. Significant progress is documented in task generalization, reasoning formalization, workflow integration, and addressing core challenges in text processing, knowledge integration, and evaluation rigor via technical innovations like sparse attention mechanisms and mixture-of-experts architectures. However, widespread adoption of LLM introduces critical challenges: hallucination, explainability deficits, jurisdictional adaptation difficulties, and ethical asymmetry. This review proposes a novel taxonomy that maps legal roles to NLP subtasks and computationally implements the Toulmin argumentation framework, thus systematizing advances in reasoning, retrieval, prediction, and dispute resolution. It identifies key frontiers including low-resource systems, multimodal evidence integration, and dynamic rebuttal handling. Ultimately, this work provides both a technical roadmap for researchers and a conceptual framework for practitioners navigating the algorithmic future, laying a robust foundation for the next era of legal artificial intelligence. We have created a GitHub repository to index the relevant papers: https://github.com/Kilimajaro/LLMs_Meet_Law.
FaVChat: Unlocking Fine-Grained Facial Video Understanding with Multimodal Large Language Models
Mar 13, 2025



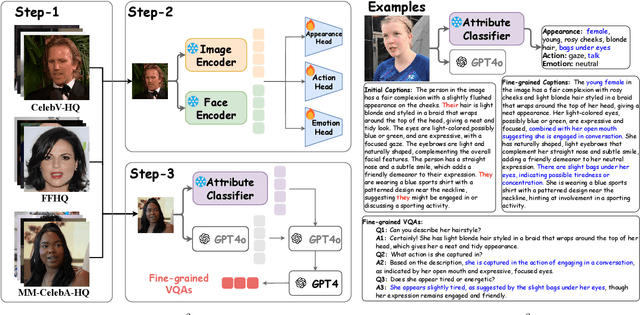
Video-based multimodal large language models (VMLLMs) have demonstrated remarkable potential in cross-modal video understanding. However, their abilities in fine-grained face comprehension remain largely underexplored. Given its pivotal role in human-centric intelligence, developing VMLLMs for facial understanding holds a fundamental problem. To address this gap, we propose FaVChat, the first VMLLM specifically designed for fine-grained facial video understanding. To facilitate its training, we construct a large-scale facial video dataset comprising over 60k videos, with the majority annotated with 83 fine-grained facial attributes. These attributes are incorporated to enrich GPT-4o-generated captions, yielding 60k high-quality video-summary pairs and an additional 170k fine-grained question-answering (QA) pairs. To effectively capture rich facial clues, we propose a hybrid model architecture composed of a general visual encoder, a dedicated facial encoder, and a mixture-of-experts-enhanced adapter for adaptive fusion of multi-source visual features. To mitigate information loss during feature transformation, we extract multi-granularity representations from the facial encoder and integrate them into the subsequent LLM. This design enhances the model's ability to comprehend and respond to questions involving diverse levels of visual details. We employ a progressive training paradigm, transitioning from video summarization to a high-quality subset of video QA, gradually increasing task complexity to enhance the model's fine-grained visual perception. We conduct extensive zero-shot evaluation on a couple of public benchmarks, demonstrating that FaVChat consistently surpasses existing VMLLMs across multiple tasks.
Uni$\textbf{F}^2$ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
Mar 11, 2025


Unified multimodal models (UMMs) have emerged as a powerful paradigm in foundational computer vision research, demonstrating significant potential in both image understanding and generation. However, existing research in the face domain primarily focuses on $\textbf{coarse}$ facial attribute understanding, with limited capacity to handle $\textbf{fine-grained}$ facial attributes and without addressing generation capabilities. To overcome these limitations, we propose Uni$\textbf{F}^2$ace, the first UMM tailored specifically for fine-grained face understanding and generation. In general, we train Uni$\textbf{F}^2$ace on a self-constructed, specialized dataset utilizing two mutually beneficial diffusion techniques and a two-level mixture-of-experts architecture. Specifically, we first build a large-scale facial dataset, Uni$\textbf{F}^2$ace-130K, which contains 130K image-text pairs with one million question-answering pairs that span a wide range of facial attributes. Second, we establish a theoretical connection between discrete diffusion score matching and masked generative models, optimizing both evidence lower bounds simultaneously, which significantly improves the model's ability to synthesize facial details. Finally, we introduce both token-level and sequence-level mixture-of-experts, enabling efficient fine-grained representation learning for both understanding and generation tasks. Extensive experiments on Uni$\textbf{F}^2$ace-130K demonstrate that Uni$\textbf{F}^2$ace outperforms existing UMMs and generative models, achieving superior performance across both understanding and generation tasks.
RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
Jun 18, 2024The remote sensing image intelligence understanding model is undergoing a new profound paradigm shift which has been promoted by multi-modal large language model (MLLM), i.e. from the paradigm learning a domain model (LaDM) shifts to paradigm learning a pre-trained general foundation model followed by an adaptive domain model (LaGD). Under the new LaGD paradigm, the old datasets, which have led to advances in RSI intelligence understanding in the last decade, are no longer suitable for fire-new tasks. We argued that a new dataset must be designed to lighten tasks with the following features: 1) Generalization: training model to learn shared knowledge among tasks and to adapt to different tasks; 2) Understanding complex scenes: training model to understand the fine-grained attribute of the objects of interest, and to be able to describe the scene with natural language; 3) Reasoning: training model to be able to realize high-level visual reasoning. In this paper, we designed a high-quality, diversified, and unified multimodal instruction-following dataset for RSI understanding produced by GPT-4V and existing datasets, which we called RS-GPT4V. To achieve generalization, we used a (Question, Answer) which was deduced from GPT-4V via instruction-following to unify the tasks such as captioning and localization; To achieve complex scene, we proposed a hierarchical instruction description with local strategy in which the fine-grained attributes of the objects and their spatial relationships are described and global strategy in which all the local information are integrated to yield detailed instruction descript; To achieve reasoning, we designed multiple-turn QA pair to provide the reasoning ability for a model. The empirical results show that the fine-tuned MLLMs by RS-GPT4V can describe fine-grained information. The dataset is available at: https://github.com/GeoX-Lab/RS-GPT4V.