 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
Mar 23, 2026Video--based world models have emerged along two dominant paradigms: video generation and 3D reconstruction. However, existing evaluation benchmarks either focus narrowly on visual fidelity and text--video alignment for generative models, or rely on static 3D reconstruction metrics that fundamentally neglect temporal dynamics. We argue that the future of world modeling lies in 4D generation, which jointly models spatial structure and temporal evolution. In this paradigm, the core capability is interactive response: the ability to faithfully reflect how interaction actions drive state transitions across space and time. Yet no existing benchmark systematically evaluates this critical dimension. To address this gap, we propose Omni--WorldBench, a comprehensive benchmark specifically designed to evaluate the interactive response capabilities of world models in 4D settings. Omni--WorldBench comprises two key components: Omni--WorldSuite, a systematic prompt suite spanning diverse interaction levels and scene types; and Omni--Metrics, an agent-based evaluation framework that quantifies world modeling capabilities by measuring the causal impact of interaction actions on both final outcomes and intermediate state evolution trajectories. We conduct extensive evaluations of 18 representative world models across multiple paradigms. Our analysis reveals critical limitations of current world models in interactive response, providing actionable insights for future research. Omni-WorldBench will be publicly released to foster progress in interactive 4D world modeling.
SitLLM: Large Language Models for Sitting Posture Health Understanding via Pressure Sensor Data
Sep 16, 2025Poor sitting posture is a critical yet often overlooked factor contributing to long-term musculoskeletal disorders and physiological dysfunctions. Existing sitting posture monitoring systems, although leveraging visual, IMU, or pressure-based modalities, often suffer from coarse-grained recognition and lack the semantic expressiveness necessary for personalized feedback. In this paper, we propose \textbf{SitLLM}, a lightweight multimodal framework that integrates flexible pressure sensing with large language models (LLMs) to enable fine-grained posture understanding and personalized health-oriented response generation. SitLLM comprises three key components: (1) a \textit{Gaussian-Robust Sensor Embedding Module} that partitions pressure maps into spatial patches and injects local noise perturbations for robust feature extraction; (2) a \textit{Prompt-Driven Cross-Modal Alignment Module} that reprograms sensor embeddings into the LLM's semantic space via multi-head cross-attention using the pre-trained vocabulary embeddings; and (3) a \textit{Multi-Context Prompt Module} that fuses feature-level, structure-level, statistical-level, and semantic-level contextual information to guide instruction comprehension.
FaVChat: Unlocking Fine-Grained Facial Video Understanding with Multimodal Large Language Models
Mar 13, 2025



Video-based multimodal large language models (VMLLMs) have demonstrated remarkable potential in cross-modal video understanding. However, their abilities in fine-grained face comprehension remain largely underexplored. Given its pivotal role in human-centric intelligence, developing VMLLMs for facial understanding holds a fundamental problem. To address this gap, we propose FaVChat, the first VMLLM specifically designed for fine-grained facial video understanding. To facilitate its training, we construct a large-scale facial video dataset comprising over 60k videos, with the majority annotated with 83 fine-grained facial attributes. These attributes are incorporated to enrich GPT-4o-generated captions, yielding 60k high-quality video-summary pairs and an additional 170k fine-grained question-answering (QA) pairs. To effectively capture rich facial clues, we propose a hybrid model architecture composed of a general visual encoder, a dedicated facial encoder, and a mixture-of-experts-enhanced adapter for adaptive fusion of multi-source visual features. To mitigate information loss during feature transformation, we extract multi-granularity representations from the facial encoder and integrate them into the subsequent LLM. This design enhances the model's ability to comprehend and respond to questions involving diverse levels of visual details. We employ a progressive training paradigm, transitioning from video summarization to a high-quality subset of video QA, gradually increasing task complexity to enhance the model's fine-grained visual perception. We conduct extensive zero-shot evaluation on a couple of public benchmarks, demonstrating that FaVChat consistently surpasses existing VMLLMs across multiple tasks.
\textit{re}CSE: Portable Reshaping Features for Sentence Embedding in Self-supervised Contrastive Learning
Aug 09, 2024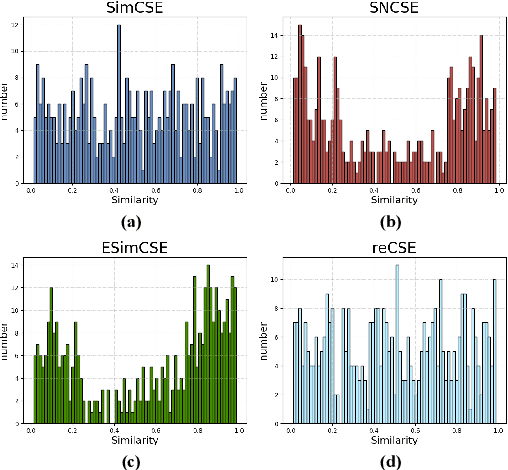



We propose \textit{re}CSE, a self supervised contrastive learning sentence representation framework based on feature reshaping. This framework is different from the current advanced models that use discrete data augmentation methods, but instead reshapes the input features of the original sentence, aggregates the global information of each token in the sentence, and alleviates the common problems of representation polarity and GPU memory consumption linear increase in current advanced models. In addition, our \textit{re}CSE has achieved competitive performance in semantic similarity tasks. And the experiment proves that our proposed feature reshaping method has strong universality, which can be transplanted to other self supervised contrastive learning frameworks and enhance their representation ability, even achieving state-of-the-art performance. Our code is available at https://github.com/heavenhellchen/reCSE.
SimCT: A Simple Consistency Test Protocol in LLMs Development Lifecycle
Jul 24, 2024In this work, we report our efforts to advance the standard operation procedure of developing Large Language Models (LLMs) or LLMs-based systems or services in industry. We introduce the concept of Large Language Model Development Lifecycle (LDLC) and then highlight the importance of consistency test in ensuring the delivery quality. The principled solution of consistency test, however, is usually overlooked by industrial practitioners and not urgent in academia, and current practical solutions are insufficiently rigours and labor-intensive. We thus propose a simple yet effective consistency test protocol, named SimCT. SimCT is mainly to proactively check the consistency across different development stages of "bare metal" LLMs or associated services without accessing the model artifacts, in an attempt to expedite the delivery by reducing the back-and-forth alignment communications among multiple teams involved in different development stages. Specifically, SimCT encompasses response-wise and model-wise tests. We implement the protocol with LightGBM and Student's t-test for two components respectively, and perform extensive experiments to substantiate the effectiveness of SimCT and the involved components.
Consistency Matters: Explore LLMs Consistency From a Black-Box Perspective
Mar 02, 2024



Nowadays both commercial and open-source academic LLM have become the mainstream models of NLP. However, there is still a lack of research on LLM consistency, meaning that throughout the various stages of LLM research and deployment, its internal parameters and capabilities should remain unchanged. This issue exists in both the industrial and academic sectors. The solution to this problem is often time-consuming and labor-intensive, and there is also an additional cost of secondary deployment, resulting in economic and time losses. To fill this gap, we build an LLM consistency task dataset and design several baselines. Additionally, we choose models of diverse scales for the main experiments. Specifically, in the LightGBM experiment, we used traditional NLG metrics (i.e., ROUGE, BLEU, METEOR) as the features needed for model training. The final result exceeds the manual evaluation and GPT3.5 as well as other models in the main experiment, achieving the best performance. In the end, we use the best performing LightGBM model as the base model to build the evaluation tool, which can effectively assist in the deployment of business models. Our code and tool demo are available at https://github.com/heavenhellchen/Consistency.git