 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSitLLM: Large Language Models for Sitting Posture Health Understanding via Pressure Sensor Data
Sep 16, 2025Poor sitting posture is a critical yet often overlooked factor contributing to long-term musculoskeletal disorders and physiological dysfunctions. Existing sitting posture monitoring systems, although leveraging visual, IMU, or pressure-based modalities, often suffer from coarse-grained recognition and lack the semantic expressiveness necessary for personalized feedback. In this paper, we propose \textbf{SitLLM}, a lightweight multimodal framework that integrates flexible pressure sensing with large language models (LLMs) to enable fine-grained posture understanding and personalized health-oriented response generation. SitLLM comprises three key components: (1) a \textit{Gaussian-Robust Sensor Embedding Module} that partitions pressure maps into spatial patches and injects local noise perturbations for robust feature extraction; (2) a \textit{Prompt-Driven Cross-Modal Alignment Module} that reprograms sensor embeddings into the LLM's semantic space via multi-head cross-attention using the pre-trained vocabulary embeddings; and (3) a \textit{Multi-Context Prompt Module} that fuses feature-level, structure-level, statistical-level, and semantic-level contextual information to guide instruction comprehension.
FaVChat: Unlocking Fine-Grained Facial Video Understanding with Multimodal Large Language Models
Mar 13, 2025



Video-based multimodal large language models (VMLLMs) have demonstrated remarkable potential in cross-modal video understanding. However, their abilities in fine-grained face comprehension remain largely underexplored. Given its pivotal role in human-centric intelligence, developing VMLLMs for facial understanding holds a fundamental problem. To address this gap, we propose FaVChat, the first VMLLM specifically designed for fine-grained facial video understanding. To facilitate its training, we construct a large-scale facial video dataset comprising over 60k videos, with the majority annotated with 83 fine-grained facial attributes. These attributes are incorporated to enrich GPT-4o-generated captions, yielding 60k high-quality video-summary pairs and an additional 170k fine-grained question-answering (QA) pairs. To effectively capture rich facial clues, we propose a hybrid model architecture composed of a general visual encoder, a dedicated facial encoder, and a mixture-of-experts-enhanced adapter for adaptive fusion of multi-source visual features. To mitigate information loss during feature transformation, we extract multi-granularity representations from the facial encoder and integrate them into the subsequent LLM. This design enhances the model's ability to comprehend and respond to questions involving diverse levels of visual details. We employ a progressive training paradigm, transitioning from video summarization to a high-quality subset of video QA, gradually increasing task complexity to enhance the model's fine-grained visual perception. We conduct extensive zero-shot evaluation on a couple of public benchmarks, demonstrating that FaVChat consistently surpasses existing VMLLMs across multiple tasks.
Soft Knowledge Distillation with Multi-Dimensional Cross-Net Attention for Image Restoration Models Compression
Jan 16, 2025Transformer-based encoder-decoder models have achieved remarkable success in image-to-image transfer tasks, particularly in image restoration. However, their high computational complexity-manifested in elevated FLOPs and parameter counts-limits their application in real-world scenarios. Existing knowledge distillation methods in image restoration typically employ lightweight student models that directly mimic the intermediate features and reconstruction results of the teacher, overlooking the implicit attention relationships between them. To address this, we propose a Soft Knowledge Distillation (SKD) strategy that incorporates a Multi-dimensional Cross-net Attention (MCA) mechanism for compressing image restoration models. This mechanism facilitates interaction between the student and teacher across both channel and spatial dimensions, enabling the student to implicitly learn the attention matrices. Additionally, we employ a Gaussian kernel function to measure the distance between student and teacher features in kernel space, ensuring stable and efficient feature learning. To further enhance the quality of reconstructed images, we replace the commonly used L1 or KL divergence loss with a contrastive learning loss at the image level. Experiments on three tasks-image deraining, deblurring, and denoising-demonstrate that our SKD strategy significantly reduces computational complexity while maintaining strong image restoration capabilities.
Knowledge Distillation for Image Restoration : Simultaneous Learning from Degraded and Clean Images
Jan 16, 2025Model compression through knowledge distillation has seen extensive application in classification and segmentation tasks. However, its potential in image-to-image translation, particularly in image restoration, remains underexplored. To address this gap, we propose a Simultaneous Learning Knowledge Distillation (SLKD) framework tailored for model compression in image restoration tasks. SLKD employs a dual-teacher, single-student architecture with two distinct learning strategies: Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL), simultaneously. In DRL, the student encoder learns from Teacher A to focus on removing degradation factors, guided by a novel BRISQUE extractor. In IRL, the student decoder learns from Teacher B to reconstruct clean images, with the assistance of a proposed PIQE extractor. These strategies enable the student to learn from degraded and clean images simultaneously, ensuring high-quality compression of image restoration models. Experimental results across five datasets and three tasks demonstrate that SLKD achieves substantial reductions in FLOPs and parameters, exceeding 80\%, while maintaining strong image restoration performance.
\textit{re}CSE: Portable Reshaping Features for Sentence Embedding in Self-supervised Contrastive Learning
Aug 09, 2024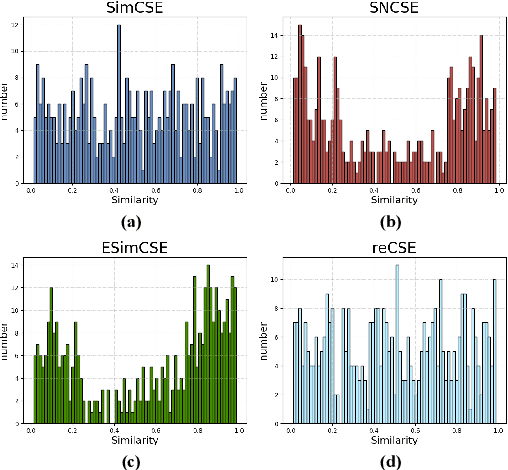



We propose \textit{re}CSE, a self supervised contrastive learning sentence representation framework based on feature reshaping. This framework is different from the current advanced models that use discrete data augmentation methods, but instead reshapes the input features of the original sentence, aggregates the global information of each token in the sentence, and alleviates the common problems of representation polarity and GPU memory consumption linear increase in current advanced models. In addition, our \textit{re}CSE has achieved competitive performance in semantic similarity tasks. And the experiment proves that our proposed feature reshaping method has strong universality, which can be transplanted to other self supervised contrastive learning frameworks and enhance their representation ability, even achieving state-of-the-art performance. Our code is available at https://github.com/heavenhellchen/reCSE.
Uni-Removal: A Semi-Supervised Framework for Simultaneously Addressing Multiple Degradations in Real-World Images
Jul 11, 2023



Removing multiple degradations, such as haze, rain, and blur, from real-world images poses a challenging and illposed problem. Recently, unified models that can handle different degradations have been proposed and yield promising results. However, these approaches focus on synthetic images and experience a significant performance drop when applied to realworld images. In this paper, we introduce Uni-Removal, a twostage semi-supervised framework for addressing the removal of multiple degradations in real-world images using a unified model and parameters. In the knowledge transfer stage, Uni-Removal leverages a supervised multi-teacher and student architecture in the knowledge transfer stage to facilitate learning from pretrained teacher networks specialized in different degradation types. A multi-grained contrastive loss is introduced to enhance learning from feature and image spaces. In the domain adaptation stage, unsupervised fine-tuning is performed by incorporating an adversarial discriminator on real-world images. The integration of an extended multi-grained contrastive loss and generative adversarial loss enables the adaptation of the student network from synthetic to real-world domains. Extensive experiments on real-world degraded datasets demonstrate the effectiveness of our proposed method. We compare our Uni-Removal framework with state-of-the-art supervised and unsupervised methods, showcasing its promising results in real-world image dehazing, deraining, and deblurring simultaneously.