 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Think with Images Efficiently! An Interleaved-Modal Chain-of-Thought Reasoning Framework with Dynamic and Precise Visual Thoughts
Mar 23, 2026Recently, Interleaved-modal Chain-of-Thought (ICoT) reasoning has achieved remarkable success by leveraging both multimodal inputs and outputs, attracting increasing attention. While achieving promising performance, current ICoT methods still suffer from two major limitations: (1) Static Visual Thought Positioning, which statically inserts visual information at fixed steps, resulting in inefficient and inflexible reasoning; and (2) Broken Visual Thought Representation, which involves discontinuous and semantically incoherent visual tokens. To address these limitations, we introduce Interleaved-modal Chain-of-Thought reasoning with Dynamic and Precise Visual Thoughts (DaP-ICoT), which incorporates two key components: (1) Dynamic Visual Thought Integration adaptively introduces visual inputs based on reasoning needs, reducing redundancy and improving efficiency. (2) Precise Visual Thought Guidance ensures visual semantically coherent and contextually aligned representations. Experiments across multiple benchmarks and models demonstrate that DaP-ICoT achieves state-of-the-art performance. In addition, DaP-ICoT significantly reduces the number of inserted images, leading to a 72.6% decrease in token consumption, enabling more efficient ICoT reasoning.
OMNIFLOW: A Physics-Grounded Multimodal Agent for Generalized Scientific Reasoning
Mar 16, 2026Large Language Models (LLMs) have demonstrated exceptional logical reasoning capabilities but frequently struggle with the continuous spatiotemporal dynamics governed by Partial Differential Equations (PDEs), often resulting in non-physical hallucinations. Existing approaches typically resort to costly, domain-specific fine-tuning, which severely limits cross-domain generalization and interpretability. To bridge this gap, we propose OMNIFLOW, a neuro-symbolic architecture designed to ground frozen multimodal LLMs in fundamental physical laws without requiring domain-specific parameter updates. OMNIFLOW introduces a novel \textit{Semantic-Symbolic Alignment} mechanism that projects high-dimensional flow tensors into topological linguistic descriptors, enabling the model to perceive physical structures rather than raw pixel values. Furthermore, we construct a Physics-Guided Chain-of-Thought (PG-CoT) workflow that orchestrates reasoning through dynamic constraint injection (e.g., mass conservation) and iterative reflexive verification. We evaluate OMNIFLOW on a comprehensive benchmark spanning microscopic turbulence, theoretical Navier-Stokes equations, and macroscopic global weather forecasting. Empirical results demonstrate that OMNIFLOW significantly outperforms traditional deep learning baselines in zero-shot generalization and few-shot adaptation tasks. Crucially, it offers transparent, physically consistent reasoning reports, marking a paradigm shift from black-box fitting to interpretable scientific reasoning.
CCHall: A Novel Benchmark for Joint Cross-Lingual and Cross-Modal Hallucinations Detection in Large Language Models
May 25, 2025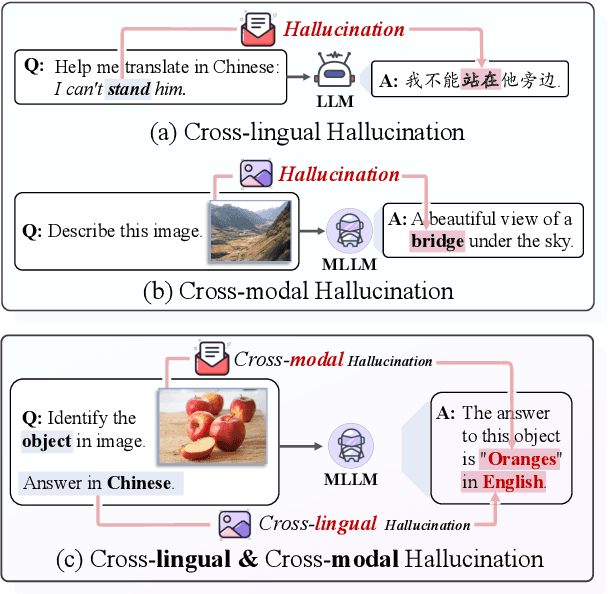

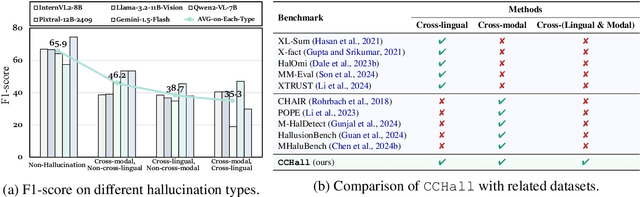

Investigating hallucination issues in large language models (LLMs) within cross-lingual and cross-modal scenarios can greatly advance the large-scale deployment in real-world applications. Nevertheless, the current studies are limited to a single scenario, either cross-lingual or cross-modal, leaving a gap in the exploration of hallucinations in the joint cross-lingual and cross-modal scenarios. Motivated by this, we introduce a novel joint Cross-lingual and Cross-modal Hallucinations benchmark (CCHall) to fill this gap. Specifically, CCHall simultaneously incorporates both cross-lingual and cross-modal hallucination scenarios, which can be used to assess the cross-lingual and cross-modal capabilities of LLMs. Furthermore, we conduct a comprehensive evaluation on CCHall, exploring both mainstream open-source and closed-source LLMs. The experimental results highlight that current LLMs still struggle with CCHall. We hope CCHall can serve as a valuable resource to assess LLMs in joint cross-lingual and cross-modal scenarios.
Soft Knowledge Distillation with Multi-Dimensional Cross-Net Attention for Image Restoration Models Compression
Jan 16, 2025Transformer-based encoder-decoder models have achieved remarkable success in image-to-image transfer tasks, particularly in image restoration. However, their high computational complexity-manifested in elevated FLOPs and parameter counts-limits their application in real-world scenarios. Existing knowledge distillation methods in image restoration typically employ lightweight student models that directly mimic the intermediate features and reconstruction results of the teacher, overlooking the implicit attention relationships between them. To address this, we propose a Soft Knowledge Distillation (SKD) strategy that incorporates a Multi-dimensional Cross-net Attention (MCA) mechanism for compressing image restoration models. This mechanism facilitates interaction between the student and teacher across both channel and spatial dimensions, enabling the student to implicitly learn the attention matrices. Additionally, we employ a Gaussian kernel function to measure the distance between student and teacher features in kernel space, ensuring stable and efficient feature learning. To further enhance the quality of reconstructed images, we replace the commonly used L1 or KL divergence loss with a contrastive learning loss at the image level. Experiments on three tasks-image deraining, deblurring, and denoising-demonstrate that our SKD strategy significantly reduces computational complexity while maintaining strong image restoration capabilities.
Knowledge Distillation for Image Restoration : Simultaneous Learning from Degraded and Clean Images
Jan 16, 2025Model compression through knowledge distillation has seen extensive application in classification and segmentation tasks. However, its potential in image-to-image translation, particularly in image restoration, remains underexplored. To address this gap, we propose a Simultaneous Learning Knowledge Distillation (SLKD) framework tailored for model compression in image restoration tasks. SLKD employs a dual-teacher, single-student architecture with two distinct learning strategies: Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL), simultaneously. In DRL, the student encoder learns from Teacher A to focus on removing degradation factors, guided by a novel BRISQUE extractor. In IRL, the student decoder learns from Teacher B to reconstruct clean images, with the assistance of a proposed PIQE extractor. These strategies enable the student to learn from degraded and clean images simultaneously, ensuring high-quality compression of image restoration models. Experimental results across five datasets and three tasks demonstrate that SLKD achieves substantial reductions in FLOPs and parameters, exceeding 80\%, while maintaining strong image restoration performance.
Wrong-of-Thought: An Integrated Reasoning Framework with Multi-Perspective Verification and Wrong Information
Oct 06, 2024



Chain-of-Thought (CoT) has become a vital technique for enhancing the performance of Large Language Models (LLMs), attracting increasing attention from researchers. One stream of approaches focuses on the iterative enhancement of LLMs by continuously verifying and refining their reasoning outputs for desired quality. Despite its impressive results, this paradigm faces two critical issues: (1) Simple verification methods: The current paradigm relies solely on a single verification method. (2) Wrong Information Ignorance: Traditional paradigms directly ignore wrong information during reasoning and refine the logic paths from scratch each time. To address these challenges, we propose Wrong-of-Thought (WoT), which includes two core modules: (1) Multi-Perspective Verification: A multi-perspective verification method for accurately refining the reasoning process and result, and (2) Wrong Information Utilization: Utilizing wrong information to alert LLMs and reduce the probability of LLMs making same mistakes. Experiments on 8 popular datasets and 5 LLMs demonstrate that WoT surpasses all previous baselines. In addition, WoT exhibits powerful capabilities in difficult computation tasks.
AutoCAP: Towards Automatic Cross-lingual Alignment Planning for Zero-shot Chain-of-Thought
Jun 20, 2024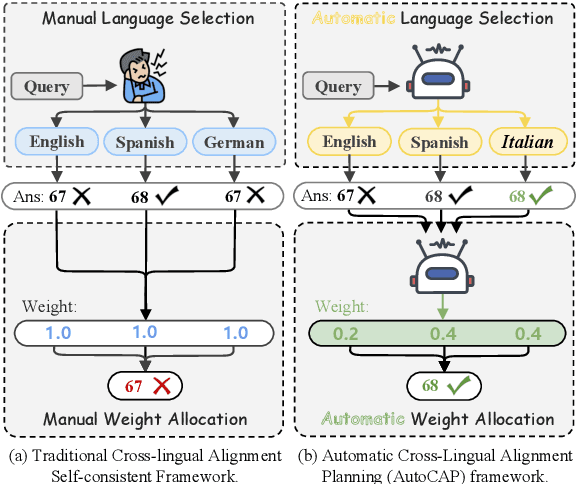
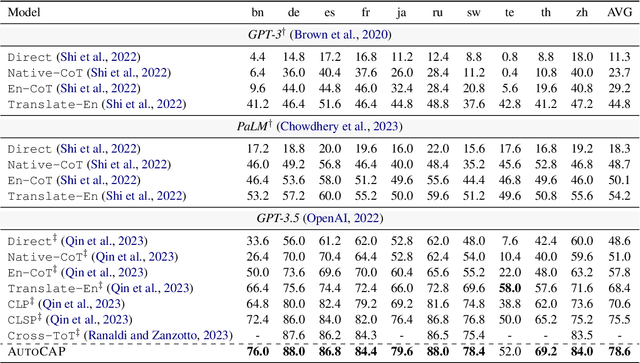
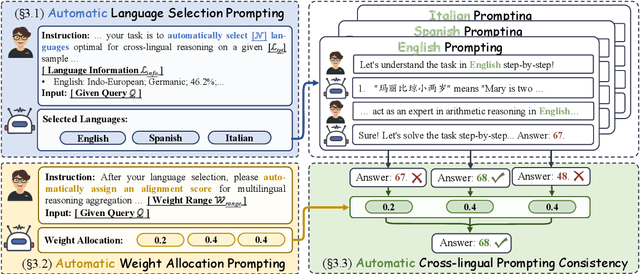
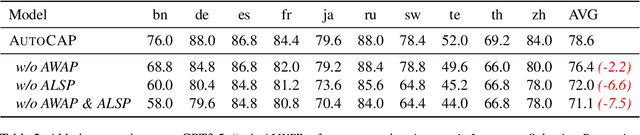
Cross-lingual chain-of-thought can effectively complete reasoning tasks across languages, which gains increasing attention. Recently, dominant approaches in the literature improve cross-lingual alignment capabilities by integrating reasoning knowledge from different languages. Despite achieving excellent performance, current methods still have two main challenges: (1) Manual language specification: They still highly rely on manually selecting the languages to integrate, severely affecting their generalizability; (2) Static weight allocation: Current methods simply integrate all languages equally. In fact, different language reasoning paths should have different weights to achieve better complementation and integration. Motivated by this, we introduce an Automatic Cross-lingual Alignment Planning (AutoCAP) for zero-shot chain-of-thought to address the above challenges. The core of AutoCAP consists of two components: (1) Automatic Language Selection Prompting to guide LLMs to select appropriate languages and (2) Automatic Weight Allocation Prompting to automatically allocate alignment weight scores to each reasoning path. Extensive experiments on several benchmarks reveal that AutoCAP achieves state-of-the-art performance, surpassing previous methods that required manual effort.
Large Language Models Meet NLP: A Survey
May 21, 2024



While large language models (LLMs) like ChatGPT have shown impressive capabilities in Natural Language Processing (NLP) tasks, a systematic investigation of their potential in this field remains largely unexplored. This study aims to address this gap by exploring the following questions: (1) How are LLMs currently applied to NLP tasks in the literature? (2) Have traditional NLP tasks already been solved with LLMs? (3) What is the future of the LLMs for NLP? To answer these questions, we take the first step to provide a comprehensive overview of LLMs in NLP. Specifically, we first introduce a unified taxonomy including (1) parameter-frozen application and (2) parameter-tuning application to offer a unified perspective for understanding the current progress of LLMs in NLP. Furthermore, we summarize the new frontiers and the associated challenges, aiming to inspire further groundbreaking advancements. We hope this work offers valuable insights into the {potential and limitations} of LLMs in NLP, while also serving as a practical guide for building effective LLMs in NLP.
AttacKG+:Boosting Attack Knowledge Graph Construction with Large Language Models
May 08, 2024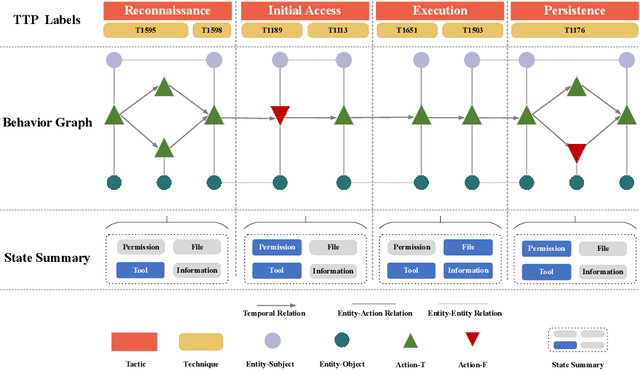



Attack knowledge graph construction seeks to convert textual cyber threat intelligence (CTI) reports into structured representations, portraying the evolutionary traces of cyber attacks. Even though previous research has proposed various methods to construct attack knowledge graphs, they generally suffer from limited generalization capability to diverse knowledge types as well as requirement of expertise in model design and tuning. Addressing these limitations, we seek to utilize Large Language Models (LLMs), which have achieved enormous success in a broad range of tasks given exceptional capabilities in both language understanding and zero-shot task fulfillment. Thus, we propose a fully automatic LLM-based framework to construct attack knowledge graphs named: AttacKG+. Our framework consists of four consecutive modules: rewriter, parser, identifier, and summarizer, each of which is implemented by instruction prompting and in-context learning empowered by LLMs. Furthermore, we upgrade the existing attack knowledge schema and propose a comprehensive version. We represent a cyber attack as a temporally unfolding event, each temporal step of which encapsulates three layers of representation, including behavior graph, MITRE TTP labels, and state summary. Extensive evaluation demonstrates that: 1) our formulation seamlessly satisfies the information needs in threat event analysis, 2) our construction framework is effective in faithfully and accurately extracting the information defined by AttacKG+, and 3) our attack graph directly benefits downstream security practices such as attack reconstruction. All the code and datasets will be released upon acceptance.
Uni-Removal: A Semi-Supervised Framework for Simultaneously Addressing Multiple Degradations in Real-World Images
Jul 11, 2023



Removing multiple degradations, such as haze, rain, and blur, from real-world images poses a challenging and illposed problem. Recently, unified models that can handle different degradations have been proposed and yield promising results. However, these approaches focus on synthetic images and experience a significant performance drop when applied to realworld images. In this paper, we introduce Uni-Removal, a twostage semi-supervised framework for addressing the removal of multiple degradations in real-world images using a unified model and parameters. In the knowledge transfer stage, Uni-Removal leverages a supervised multi-teacher and student architecture in the knowledge transfer stage to facilitate learning from pretrained teacher networks specialized in different degradation types. A multi-grained contrastive loss is introduced to enhance learning from feature and image spaces. In the domain adaptation stage, unsupervised fine-tuning is performed by incorporating an adversarial discriminator on real-world images. The integration of an extended multi-grained contrastive loss and generative adversarial loss enables the adaptation of the student network from synthetic to real-world domains. Extensive experiments on real-world degraded datasets demonstrate the effectiveness of our proposed method. We compare our Uni-Removal framework with state-of-the-art supervised and unsupervised methods, showcasing its promising results in real-world image dehazing, deraining, and deblurring simultaneously.