 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGentle-CLIP: Exploring Aligned Semantic In Low-Quality Multimodal Data With Soft Alignment
Jun 09, 2024Multimodal fusion breaks through the barriers between diverse modalities and has already yielded numerous impressive performances. However, in various specialized fields, it is struggling to obtain sufficient alignment data for the training process, which seriously limits the use of previously elegant models. Thus, semi-supervised learning attempts to achieve multimodal alignment with fewer matched pairs but traditional methods like pseudo-labeling are difficult to apply in domains with no label information. To address these problems, we transform semi-supervised multimodal alignment into a manifold matching problem and propose a new method based on CLIP, named Gentle-CLIP. Specifically, we design a novel semantic density distribution loss to explore implicit semantic alignment information from unpaired multimodal data by constraining the latent representation distribution with fine granularity, thus eliminating the need for numerous strictly matched pairs. Meanwhile, we introduce multi-kernel maximum mean discrepancy as well as self-supervised contrastive loss to pull separate modality distributions closer and enhance the stability of the representation distribution. In addition, the contrastive loss used in CLIP is employed on the supervised matched data to prevent negative optimization. Extensive experiments conducted on a range of tasks in various fields, including protein, remote sensing, and the general vision-language field, demonstrate the effectiveness of our proposed Gentle-CLIP.
AttacKG+:Boosting Attack Knowledge Graph Construction with Large Language Models
May 08, 2024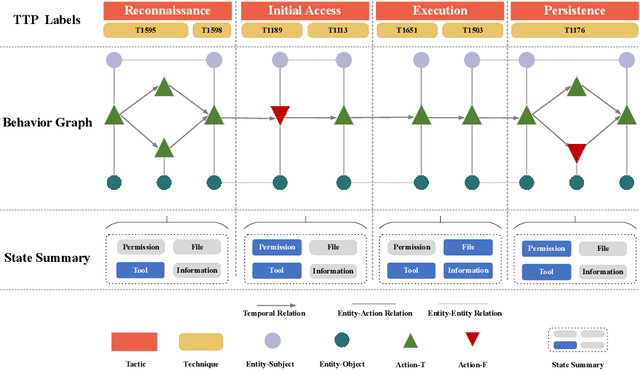



Attack knowledge graph construction seeks to convert textual cyber threat intelligence (CTI) reports into structured representations, portraying the evolutionary traces of cyber attacks. Even though previous research has proposed various methods to construct attack knowledge graphs, they generally suffer from limited generalization capability to diverse knowledge types as well as requirement of expertise in model design and tuning. Addressing these limitations, we seek to utilize Large Language Models (LLMs), which have achieved enormous success in a broad range of tasks given exceptional capabilities in both language understanding and zero-shot task fulfillment. Thus, we propose a fully automatic LLM-based framework to construct attack knowledge graphs named: AttacKG+. Our framework consists of four consecutive modules: rewriter, parser, identifier, and summarizer, each of which is implemented by instruction prompting and in-context learning empowered by LLMs. Furthermore, we upgrade the existing attack knowledge schema and propose a comprehensive version. We represent a cyber attack as a temporally unfolding event, each temporal step of which encapsulates three layers of representation, including behavior graph, MITRE TTP labels, and state summary. Extensive evaluation demonstrates that: 1) our formulation seamlessly satisfies the information needs in threat event analysis, 2) our construction framework is effective in faithfully and accurately extracting the information defined by AttacKG+, and 3) our attack graph directly benefits downstream security practices such as attack reconstruction. All the code and datasets will be released upon acceptance.