 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinger in Camera Speaks Everything: Unconstrained Air-Writing for Real-World
Dec 27, 2024



Air-writing is a challenging task that combines the fields of computer vision and natural language processing, offering an intuitive and natural approach for human-computer interaction. However, current air-writing solutions face two primary challenges: (1) their dependency on complex sensors (e.g., Radar, EEGs and others) for capturing precise handwritten trajectories, and (2) the absence of a video-based air-writing dataset that covers a comprehensive vocabulary range. These limitations impede their practicality in various real-world scenarios, including the use on devices like iPhones and laptops. To tackle these challenges, we present the groundbreaking air-writing Chinese character video dataset (AWCV-100K-UCAS2024), serving as a pioneering benchmark for video-based air-writing. This dataset captures handwritten trajectories in various real-world scenarios using commonly accessible RGB cameras, eliminating the need for complex sensors. AWCV-100K-UCAS2024 includes 8.8 million video frames, encompassing the complete set of 3,755 characters from the GB2312-80 level-1 set (GB1). Furthermore, we introduce our baseline approach, the video-based character recognizer (VCRec). VCRec adeptly extracts fingertip features from sparse visual cues and employs a spatio-temporal sequence module for analysis. Experimental results showcase the superior performance of VCRec compared to existing models in recognizing air-written characters, both quantitatively and qualitatively. This breakthrough paves the way for enhanced human-computer interaction in real-world contexts. Moreover, our approach leverages affordable RGB cameras, enabling its applicability in a diverse range of scenarios. The code and data examples will be made public at https://github.com/wmeiqi/AWCV.
Uni-Removal: A Semi-Supervised Framework for Simultaneously Addressing Multiple Degradations in Real-World Images
Jul 11, 2023



Removing multiple degradations, such as haze, rain, and blur, from real-world images poses a challenging and illposed problem. Recently, unified models that can handle different degradations have been proposed and yield promising results. However, these approaches focus on synthetic images and experience a significant performance drop when applied to realworld images. In this paper, we introduce Uni-Removal, a twostage semi-supervised framework for addressing the removal of multiple degradations in real-world images using a unified model and parameters. In the knowledge transfer stage, Uni-Removal leverages a supervised multi-teacher and student architecture in the knowledge transfer stage to facilitate learning from pretrained teacher networks specialized in different degradation types. A multi-grained contrastive loss is introduced to enhance learning from feature and image spaces. In the domain adaptation stage, unsupervised fine-tuning is performed by incorporating an adversarial discriminator on real-world images. The integration of an extended multi-grained contrastive loss and generative adversarial loss enables the adaptation of the student network from synthetic to real-world domains. Extensive experiments on real-world degraded datasets demonstrate the effectiveness of our proposed method. We compare our Uni-Removal framework with state-of-the-art supervised and unsupervised methods, showcasing its promising results in real-world image dehazing, deraining, and deblurring simultaneously.
Explore Faster Localization Learning For Scene Text Detection
Jul 04, 2022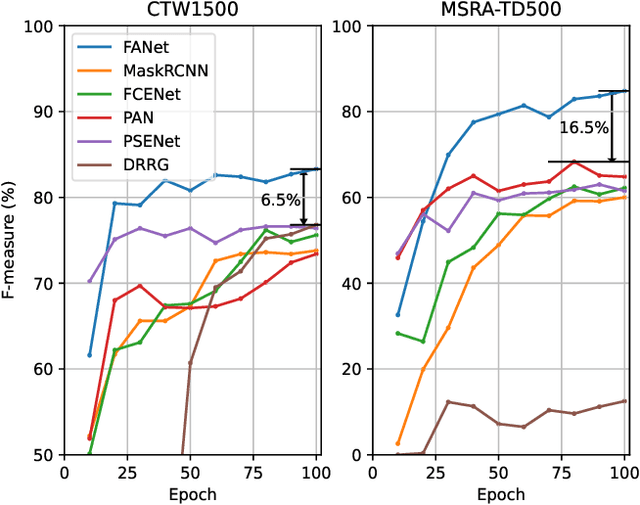



Generally pre-training and long-time training computation are necessary for obtaining a good-performance text detector based on deep networks. In this paper, we present a new scene text detection network (called FANet) with a Fast convergence speed and Accurate text localization. The proposed FANet is an end-to-end text detector based on transformer feature learning and normalized Fourier descriptor modeling, where the Fourier Descriptor Proposal Network and Iterative Text Decoding Network are designed to efficiently and accurately identify text proposals. Additionally, a Dense Matching Strategy and a well-designed loss function are also proposed for optimizing the network performance. Extensive experiments are carried out to demonstrate that the proposed FANet can achieve the SOTA performance with fewer training epochs and no pre-training. When we introduce additional data for pre-training, the proposed FANet can achieve SOTA performance on MSRATD500, CTW1500 and TotalText. The ablation experiments also verify the effectiveness of our contributions.
End-to-End Video Text Spotting with Transformer
Mar 20, 2022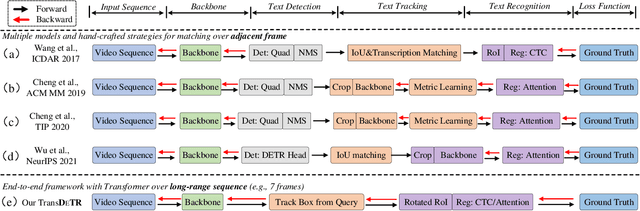


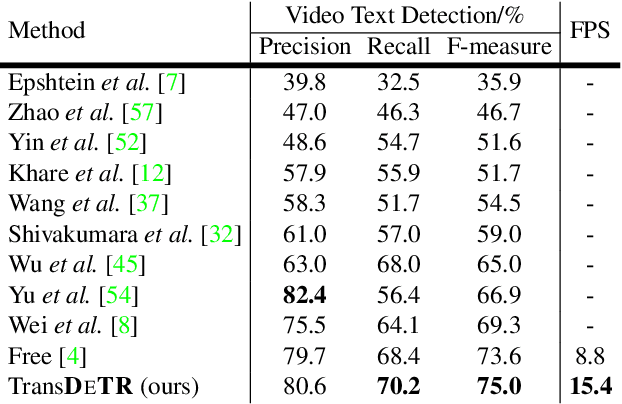
Recent video text spotting methods usually require the three-staged pipeline, i.e., detecting text in individual images, recognizing localized text, tracking text streams with post-processing to generate final results. These methods typically follow the tracking-by-match paradigm and develop sophisticated pipelines. In this paper, rooted in Transformer sequence modeling, we propose a simple, but effective end-to-end video text DEtection, Tracking, and Recognition framework (TransDETR). TransDETR mainly includes two advantages: 1) Different from the explicit match paradigm in the adjacent frame, TransDETR tracks and recognizes each text implicitly by the different query termed text query over long-range temporal sequence (more than 7 frames). 2) TransDETR is the first end-to-end trainable video text spotting framework, which simultaneously addresses the three sub-tasks (e.g., text detection, tracking, recognition). Extensive experiments in four video text datasets (i.e.,ICDAR2013 Video, ICDAR2015 Video, Minetto, and YouTube Video Text) are conducted to demonstrate that TransDETR achieves state-of-the-art performance with up to around 8.0% improvements on video text spotting tasks. The code of TransDETR can be found at https://github.com/weijiawu/TransDETR.
A Bilingual, OpenWorld Video Text Dataset and End-to-end Video Text Spotter with Transformer
Dec 09, 2021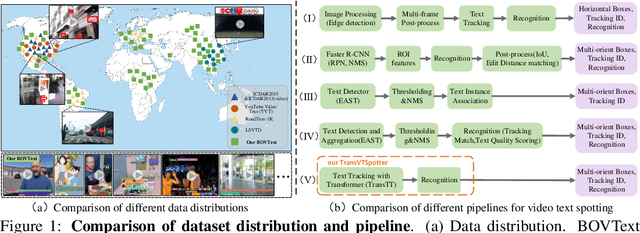
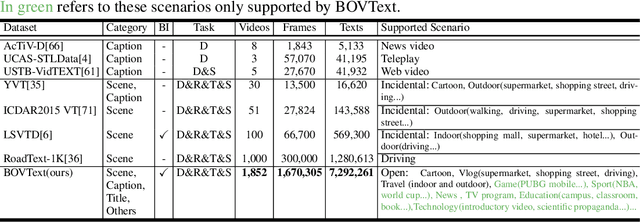

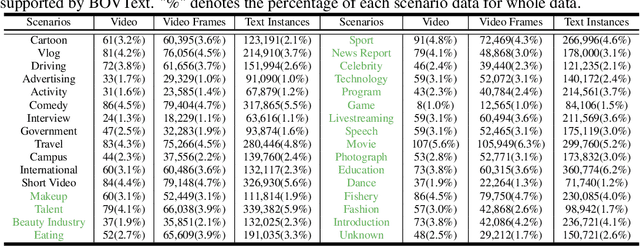
Most existing video text spotting benchmarks focus on evaluating a single language and scenario with limited data. In this work, we introduce a large-scale, Bilingual, Open World Video text benchmark dataset(BOVText). There are four features for BOVText. Firstly, we provide 2,000+ videos with more than 1,750,000+ frames, 25 times larger than the existing largest dataset with incidental text in videos. Secondly, our dataset covers 30+ open categories with a wide selection of various scenarios, e.g., Life Vlog, Driving, Movie, etc. Thirdly, abundant text types annotation (i.e., title, caption or scene text) are provided for the different representational meanings in video. Fourthly, the BOVText provides bilingual text annotation to promote multiple cultures live and communication. Besides, we propose an end-to-end video text spotting framework with Transformer, termed TransVTSpotter, which solves the multi-orient text spotting in video with a simple, but efficient attention-based query-key mechanism. It applies object features from the previous frame as a tracking query for the current frame and introduces a rotation angle prediction to fit the multiorient text instance. On ICDAR2015(video), TransVTSpotter achieves the state-of-the-art performance with 44.1% MOTA, 9 fps. The dataset and code of TransVTSpotter can be found at github:com=weijiawu=BOVText and github:com=weijiawu=TransVTSpotter, respectively.
* 20 pages, 6 figures
Towards Spatio-Temporal Video Scene Text Detection via Temporal Clustering
Nov 19, 2020



With only bounding-box annotations in the spatial domain, existing video scene text detection (VSTD) benchmarks lack temporal relation of text instances among video frames, which hinders the development of video text-related applications. In this paper, we systematically introduce a new large-scale benchmark, named as STVText4, a well-designed spatial-temporal detection metric (STDM), and a novel clustering-based baseline method, referred to as Temporal Clustering (TC). STVText4 opens a challenging yet promising direction of VSTD, termed as ST-VSTD, which targets at simultaneously detecting video scene texts in both spatial and temporal domains. STVText4 contains more than 1.4 million text instances from 161,347 video frames of 106 videos, where each instance is annotated with not only spatial bounding box and temporal range but also four intrinsic attributes, including legibility, density, scale, and lifecycle, to facilitate the community. With continuous propagation of identical texts in the video sequence, TC can accurately output the spatial quadrilateral and temporal range of the texts, which sets a strong baseline for ST-VSTD. Experiments demonstrate the efficacy of our method and the great academic and practical value of the STVText4. The dataset and code will be available soon.
Rethinking Object Detection in Retail Stores
Mar 18, 2020
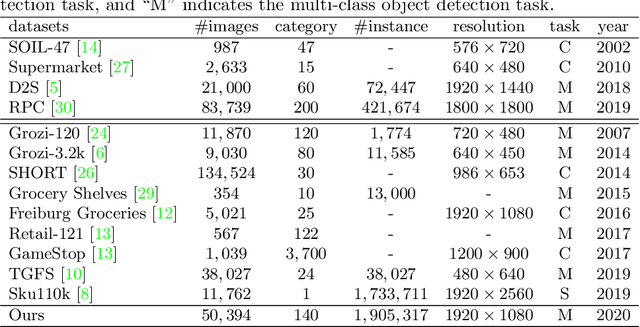


The convention standard for object detection uses a bounding box to represent each individual object instance. However, it is not practical in the industry-relevant applications in the context of warehouses due to severe occlusions among groups of instances of the same categories. In this paper, we propose a new task, ie, simultaneously object localization and counting, abbreviated as Locount, which requires algorithms to localize groups of objects of interest with the number of instances. However, there does not exist a dataset or benchmark designed for such a task. To this end, we collect a large-scale object localization and counting dataset with rich annotations in retail stores, which consists of 50,394 images with more than 1.9 million object instances in 140 categories. Together with this dataset, we provide a new evaluation protocol and divide the training and testing subsets to fairly evaluate the performance of algorithms for Locount, developing a new benchmark for the Locount task. Moreover, we present a cascaded localization and counting network as a strong baseline, which gradually classifies and regresses the bounding boxes of objects with the predicted numbers of instances enclosed in the bounding boxes, trained in an end-to-end manner. Extensive experiments are conducted on the proposed dataset to demonstrate its significance and the analysis discussions on failure cases are provided to indicate future directions. Dataset is available at https://isrc.iscas.ac.cn/gitlab/research/locount-dataset.
Guided Attention Network for Object Detection and Counting on Drones
Sep 25, 2019



Object detection and counting are related but challenging problems, especially for drone based scenes with small objects and cluttered background. In this paper, we propose a new Guided Attention Network (GANet) to deal with both object detection and counting tasks based on the feature pyramid. Different from the previous methods relying on unsupervised attention modules, we fuse different scales of feature maps by using the proposed weakly-supervised Background Attention (BA) between the background and objects for more semantic feature representation. Then, the Foreground Attention (FA) module is developed to consider both global and local appearance of the object to facilitate accurate localization. Moreover, the new data argumentation strategy is designed to train a robust model in various complex scenes. Extensive experiments on three challenging benchmarks (i.e., UAVDT, CARPK and PUCPR+) show the state-of-the-art detection and counting performance of the proposed method compared with existing methods.