 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Understanding and Generation in Discrete Diffusion Models
Feb 01, 2026In discrete generative modeling, two dominant paradigms demonstrate divergent capabilities: Masked Diffusion Language Models (MDLM) excel at semantic understanding and zero-shot generalization, whereas Uniform-noise Diffusion Language Models (UDLM) achieve strong few-step generation quality, yet neither attains balanced performance across both dimensions. To address this, we propose XDLM, which bridges the two paradigms via a stationary noise kernel. XDLM offers two key contributions: (1) it provides a principled theoretical unification of MDLM and UDLM, recovering each paradigm as a special case; and (2) an alleviated memory bottleneck enabled by an algebraic simplification of the posterior probabilities. Experiments demonstrate that XDLM advances the Pareto frontier between understanding capability and generation quality. Quantitatively, XDLM surpasses UDLM by 5.4 points on zero-shot text benchmarks and outperforms MDLM in few-step image generation (FID 54.1 vs. 80.8). When scaled to tune an 8B-parameter large language model, XDLM achieves 15.0 MBPP in just 32 steps, effectively doubling the baseline performance. Finally, analysis of training dynamics reveals XDLM's superior potential for long-term scaling. Code is available at https://github.com/MzeroMiko/XDLM
Thinking with Images via Self-Calling Agent
Dec 11, 2025Thinking-with-images paradigms have showcased remarkable visual reasoning capability by integrating visual information as dynamic elements into the Chain-of-Thought (CoT). However, optimizing interleaved multimodal CoT (iMCoT) through reinforcement learning remains challenging, as it relies on scarce high-quality reasoning data. In this study, we propose Self-Calling Chain-of-Thought (sCoT), a novel visual reasoning paradigm that reformulates iMCoT as a language-only CoT with self-calling. Specifically, a main agent decomposes the complex visual reasoning task to atomic subtasks and invokes its virtual replicas, i.e. parameter-sharing subagents, to solve them in isolated context. sCoT enjoys substantial training effectiveness and efficiency, as it requires no explicit interleaving between modalities. sCoT employs group-relative policy optimization to reinforce effective reasoning behavior to enhance optimization. Experiments on HR-Bench 4K show that sCoT improves the overall reasoning performance by up to $1.9\%$ with $\sim 75\%$ fewer GPU hours compared to strong baseline approaches. Code is available at https://github.com/YWenxi/think-with-images-through-self-calling.
Geometric-Mean Policy Optimization
Jul 28, 2025Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis
Apr 02, 2025

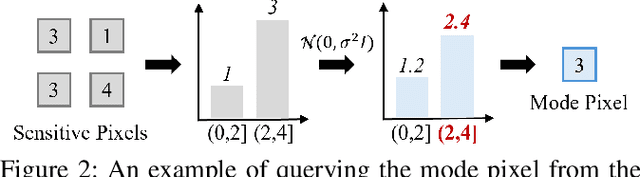

Differentially private (DP) image synthesis aims to generate synthetic images from a sensitive dataset, alleviating the privacy leakage concerns of organizations sharing and utilizing synthetic images. Although previous methods have significantly progressed, especially in training diffusion models on sensitive images with DP Stochastic Gradient Descent (DP-SGD), they still suffer from unsatisfactory performance. In this work, inspired by curriculum learning, we propose a two-stage DP image synthesis framework, where diffusion models learn to generate DP synthetic images from easy to hard. Unlike existing methods that directly use DP-SGD to train diffusion models, we propose an easy stage in the beginning, where diffusion models learn simple features of the sensitive images. To facilitate this easy stage, we propose to use `central images', simply aggregations of random samples of the sensitive dataset. Intuitively, although those central images do not show details, they demonstrate useful characteristics of all images and only incur minimal privacy costs, thus helping early-phase model training. We conduct experiments to present that on the average of four investigated image datasets, the fidelity and utility metrics of our synthetic images are 33.1% and 2.1% better than the state-of-the-art method.
Model as a Game: On Numerical and Spatial Consistency for Generative Games
Mar 27, 2025Recent advances in generative models have significantly impacted game generation. However, despite producing high-quality graphics and adequately receiving player input, existing models often fail to maintain fundamental game properties such as numerical and spatial consistency. Numerical consistency ensures gameplay mechanics correctly reflect score changes and other quantitative elements, while spatial consistency prevents jarring scene transitions, providing seamless player experiences. In this paper, we revisit the paradigm of generative games to explore what truly constitutes a Model as a Game (MaaG) with a well-developed mechanism. We begin with an empirical study on ``Traveler'', a 2D game created by an LLM featuring minimalist rules yet challenging generative models in maintaining consistency. Based on the DiT architecture, we design two specialized modules: (1) a numerical module that integrates a LogicNet to determine event triggers, with calculations processed externally as conditions for image generation; and (2) a spatial module that maintains a map of explored areas, retrieving location-specific information during generation and linking new observations to ensure continuity. Experiments across three games demonstrate that our integrated modules significantly enhance performance on consistency metrics compared to baselines, while incurring minimal time overhead during inference.
Finger in Camera Speaks Everything: Unconstrained Air-Writing for Real-World
Dec 27, 2024



Air-writing is a challenging task that combines the fields of computer vision and natural language processing, offering an intuitive and natural approach for human-computer interaction. However, current air-writing solutions face two primary challenges: (1) their dependency on complex sensors (e.g., Radar, EEGs and others) for capturing precise handwritten trajectories, and (2) the absence of a video-based air-writing dataset that covers a comprehensive vocabulary range. These limitations impede their practicality in various real-world scenarios, including the use on devices like iPhones and laptops. To tackle these challenges, we present the groundbreaking air-writing Chinese character video dataset (AWCV-100K-UCAS2024), serving as a pioneering benchmark for video-based air-writing. This dataset captures handwritten trajectories in various real-world scenarios using commonly accessible RGB cameras, eliminating the need for complex sensors. AWCV-100K-UCAS2024 includes 8.8 million video frames, encompassing the complete set of 3,755 characters from the GB2312-80 level-1 set (GB1). Furthermore, we introduce our baseline approach, the video-based character recognizer (VCRec). VCRec adeptly extracts fingertip features from sparse visual cues and employs a spatio-temporal sequence module for analysis. Experimental results showcase the superior performance of VCRec compared to existing models in recognizing air-written characters, both quantitatively and qualitatively. This breakthrough paves the way for enhanced human-computer interaction in real-world contexts. Moreover, our approach leverages affordable RGB cameras, enabling its applicability in a diverse range of scenarios. The code and data examples will be made public at https://github.com/wmeiqi/AWCV.
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model
Nov 28, 2024


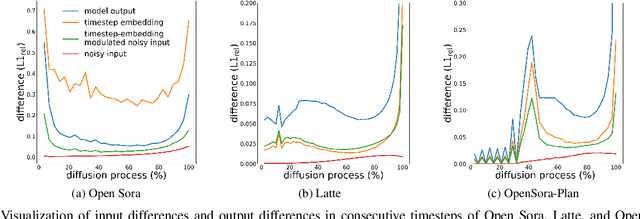
As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising. Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps. However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality. In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps. Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost. TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching. Experiments show that TeaCache achieves up to 4.41x acceleration over Open-Sora-Plan with negligible (-0.07% Vbench score) degradation of visual quality.
Evaluation of Text-to-Video Generation Models: A Dynamics Perspective
Jul 01, 2024Comprehensive and constructive evaluation protocols play an important role in the development of sophisticated text-to-video (T2V) generation models. Existing evaluation protocols primarily focus on temporal consistency and content continuity, yet largely ignore the dynamics of video content. Dynamics are an essential dimension for measuring the visual vividness and the honesty of video content to text prompts. In this study, we propose an effective evaluation protocol, termed DEVIL, which centers on the dynamics dimension to evaluate T2V models. For this purpose, we establish a new benchmark comprising text prompts that fully reflect multiple dynamics grades, and define a set of dynamics scores corresponding to various temporal granularities to comprehensively evaluate the dynamics of each generated video. Based on the new benchmark and the dynamics scores, we assess T2V models with the design of three metrics: dynamics range, dynamics controllability, and dynamics-based quality. Experiments show that DEVIL achieves a Pearson correlation exceeding 90% with human ratings, demonstrating its potential to advance T2V generation models. Code is available at https://github.com/MingXiangL/DEVIL.
DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution
May 25, 2024



Region-level multi-modality methods can translate referred image regions to human preferred language descriptions. Unfortunately, most of existing methods using fixed visual inputs remain lacking the resolution adaptability to find out precise language descriptions. In this study, we propose a dynamic resolution approach, referred to as DynRefer, to pursue high-accuracy region-level referring through mimicking the resolution adaptability of human visual cognition. DynRefer first implements stochastic vision-language alignment. It aligns desired language descriptions of multi-modality tasks with images of stochastic resolution, which are constructed by nesting a set of views around the referred region. DynRefer then implements dynamic multi-modality referring, which is realized by selecting views based on image and language priors. This allows the visual information used for referring to better match human preferences, thereby improving the representational adaptability of region-level multi-modality models. Extensive experiments show that DynRefer brings mutual improvement upon tasks including region-level captioning, open-vocabulary region recognition and attribute detection. Last but not least, DynRefer achieves new state-of-the-art on multiple region-level multi-modality tasks using a single model. Code is available at https://github.com/callsys/DynRefer.
Controllable Dense Captioner with Multimodal Embedding Bridging
Feb 01, 2024In this paper, we propose a controllable dense captioner (ControlCap), which accommodates user's intention to dense captioning by introducing linguistic guidance. ControlCap is defined as a multimodal embedding bridging architecture, which comprises multimodal embedding generation (MEG) module and bi-directional embedding bridging (BEB) module. While MEG module represents objects/regions by combining embeddings of detailed information with context-aware ones, it also endows ControlCap the adaptability to specialized controls by utilizing them as linguistic guidance. BEB module aligns the linguistic guidance with visual embeddings through borrowing/returning features from/to the visual domain and gathering such features to predict text descriptions. Experiments on Visual Genome and VG-COCO datasets show that ControlCap respectively outperforms the state-of-the-art methods by 1.5% and 3.7% (mAP). Last but not least, with the capability of converting region-category pairs to region-text pairs, ControlCap is able to act as a powerful data engine for dense captioning. Code is available at https://github.com/callsys/ControlCap.