 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Space Contrastive Reinforcement Learning for Stable and Efficient LLM Reasoning
Jan 24, 2026While Large Language Models (LLMs) demonstrate exceptional performance in surface-level text generation, their nature in handling complex multi-step reasoning tasks often remains one of ``statistical fitting'' rather than systematic logical deduction. Traditional Reinforcement Learning (RL) attempts to mitigate this by introducing a ``think-before-speak'' paradigm. However, applying RL directly in high-dimensional, discrete token spaces faces three inherent challenges: sample-inefficient rollouts, high gradient estimation variance, and the risk of catastrophic forgetting. To fundamentally address these structural bottlenecks, we propose \textbf{DeepLatent Reasoning (DLR)}, a latent-space bidirectional contrastive reinforcement learning framework. This framework shifts the trial-and-error cost from expensive token-level full sequence generation to the continuous latent manifold. Specifically, we introduce a lightweight assistant model to efficiently sample $K$ reasoning chain encodings within the latent space. These encodings are filtered via a dual reward mechanism based on correctness and formatting; only high-value latent trajectories are fed into a \textbf{frozen main model} for single-pass decoding. To maximize reasoning diversity while maintaining coherence, we design a contrastive learning objective to enable directed exploration within the latent space. Since the main model parameters remain frozen during optimization, this method mathematically eliminates catastrophic forgetting. Experiments demonstrate that under comparable GPU computational budgets, DLR achieves more stable training convergence, supports longer-horizon reasoning chains, and facilitates the sustainable accumulation of reasoning capabilities, providing a viable path toward reliable and scalable reinforcement learning for LLMs.
Multimodal Interpretation of Remote Sensing Images: Dynamic Resolution Input Strategy and Multi-scale Vision-Language Alignment Mechanism
Dec 29, 2025Multimodal fusion of remote sensing images serves as a core technology for overcoming the limitations of single-source data and improving the accuracy of surface information extraction, which exhibits significant application value in fields such as environmental monitoring and urban planning. To address the deficiencies of existing methods, including the failure of fixed resolutions to balance efficiency and detail, as well as the lack of semantic hierarchy in single-scale alignment, this study proposes a Vision-language Model (VLM) framework integrated with two key innovations: the Dynamic Resolution Input Strategy (DRIS) and the Multi-scale Vision-language Alignment Mechanism (MS-VLAM).Specifically, the DRIS adopts a coarse-to-fine approach to adaptively allocate computational resources according to the complexity of image content, thereby preserving key fine-grained features while reducing redundant computational overhead. The MS-VLAM constructs a three-tier alignment mechanism covering object, local-region and global levels, which systematically captures cross-modal semantic consistency and alleviates issues of semantic misalignment and granularity imbalance.Experimental results on the RS-GPT4V dataset demonstrate that the proposed framework significantly improves the accuracy of semantic understanding and computational efficiency in tasks including image captioning and cross-modal retrieval. Compared with conventional methods, it achieves superior performance in evaluation metrics such as BLEU-4 and CIDEr for image captioning, as well as R@10 for cross-modal retrieval. This technical framework provides a novel approach for constructing efficient and robust multimodal remote sensing systems, laying a theoretical foundation and offering technical guidance for the engineering application of intelligent remote sensing interpretation.
NeuroVoxel-LM: Language-Aligned 3D Perception via Dynamic Voxelization and Meta-Embedding
Jul 27, 2025Recent breakthroughs in Visual Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have significantly advanced 3D scene perception towards language-driven cognition. However, existing 3D language models struggle with sparse, large-scale point clouds due to slow feature extraction and limited representation accuracy. To address these challenges, we propose NeuroVoxel-LM, a novel framework that integrates Neural Radiance Fields (NeRF) with dynamic resolution voxelization and lightweight meta-embedding. Specifically, we introduce a Dynamic Resolution Multiscale Voxelization (DR-MSV) technique that adaptively adjusts voxel granularity based on geometric and structural complexity, reducing computational cost while preserving reconstruction fidelity. In addition, we propose the Token-level Adaptive Pooling for Lightweight Meta-Embedding (TAP-LME) mechanism, which enhances semantic representation through attention-based weighting and residual fusion. Experimental results demonstrate that DR-MSV significantly improves point cloud feature extraction efficiency and accuracy, while TAP-LME outperforms conventional max-pooling in capturing fine-grained semantics from NeRF weights.
RecLLM-R1: A Two-Stage Training Paradigm with Reinforcement Learning and Chain-of-Thought v1
Jun 24, 2025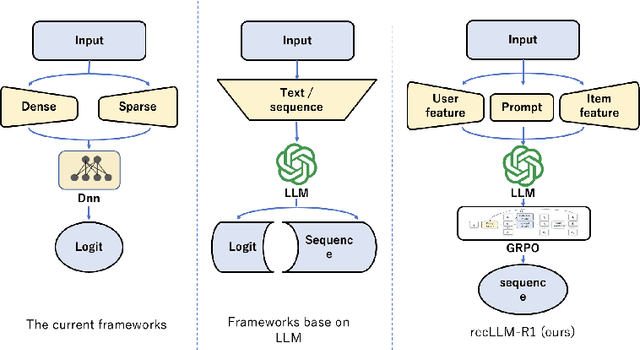



Traditional recommendation systems often grapple with "filter bubbles", underutilization of external knowledge, and a disconnect between model optimization and business policy iteration. To address these limitations, this paper introduces RecLLM-R1, a novel recommendation framework leveraging Large Language Models (LLMs) and drawing inspiration from the DeepSeek R1 methodology. The framework initiates by transforming user profiles, historical interactions, and multi-faceted item attributes into LLM-interpretable natural language prompts through a carefully engineered data construction process. Subsequently, a two-stage training paradigm is employed: the initial stage involves Supervised Fine-Tuning (SFT) to imbue the LLM with fundamental recommendation capabilities. The subsequent stage utilizes Group Relative Policy Optimization (GRPO), a reinforcement learning technique, augmented with a Chain-of-Thought (CoT) mechanism. This stage guides the model through multi-step reasoning and holistic decision-making via a flexibly defined reward function, aiming to concurrently optimize recommendation accuracy, diversity, and other bespoke business objectives. Empirical evaluations on a real-world user behavior dataset from a large-scale social media platform demonstrate that RecLLM-R1 significantly surpasses existing baseline methods across a spectrum of evaluation metrics, including accuracy, diversity, and novelty. It effectively mitigates the filter bubble effect and presents a promising avenue for the integrated optimization of recommendation models and policies under intricate business goals.
GeoGramBench: Benchmarking the Geometric Program Reasoning in Modern LLMs
May 23, 2025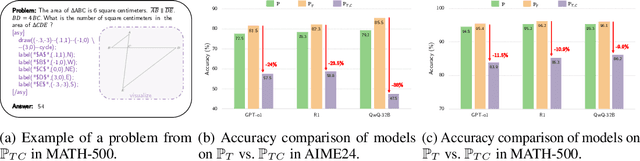
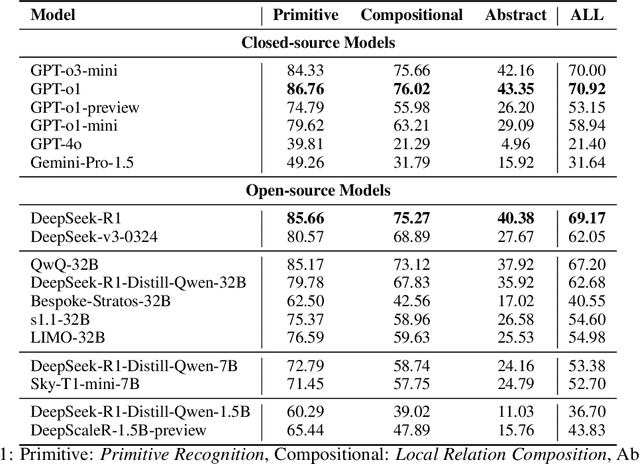
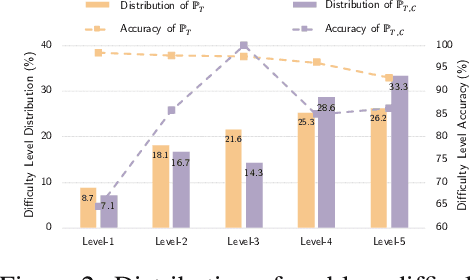
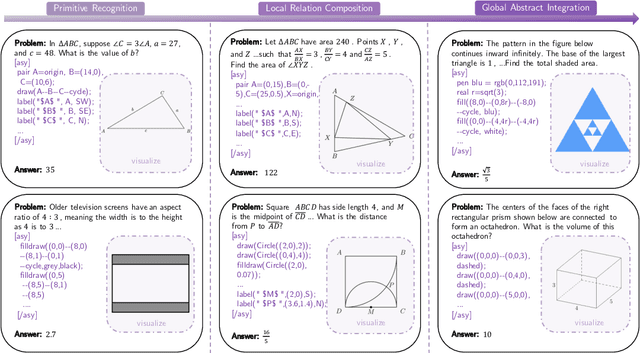
Geometric spatial reasoning forms the foundation of many applications in artificial intelligence, yet the ability of large language models (LLMs) to operate over geometric spatial information expressed in procedural code remains underexplored. In this paper, we address this gap by formalizing the Program-to-Geometry task, which challenges models to translate programmatic drawing code into accurate and abstract geometric reasoning. To evaluate this capability, we present GeoGramBench, a benchmark of 500 carefully refined problems organized by a tailored three-level taxonomy that considers geometric complexity rather than traditional mathematical reasoning complexity. Our comprehensive evaluation of 17 frontier LLMs reveals consistent and pronounced deficiencies: even the most advanced models achieve less than 50% accuracy at the highest abstraction level. These results highlight the unique challenges posed by program-driven spatial reasoning and establish GeoGramBench as a valuable resource for advancing research in symbolic-to-spatial geometric reasoning. Project page: https://github.com/LiAuto-DSR/GeoGramBench.
GMM-Based Comprehensive Feature Extraction and Relative Distance Preservation For Few-Shot Cross-Modal Retrieval
May 19, 2025Few-shot cross-modal retrieval focuses on learning cross-modal representations with limited training samples, enabling the model to handle unseen classes during inference. Unlike traditional cross-modal retrieval tasks, which assume that both training and testing data share the same class distribution, few-shot retrieval involves data with sparse representations across modalities. Existing methods often fail to adequately model the multi-peak distribution of few-shot cross-modal data, resulting in two main biases in the latent semantic space: intra-modal bias, where sparse samples fail to capture intra-class diversity, and inter-modal bias, where misalignments between image and text distributions exacerbate the semantic gap. These biases hinder retrieval accuracy. To address these issues, we propose a novel method, GCRDP, for few-shot cross-modal retrieval. This approach effectively captures the complex multi-peak distribution of data using a Gaussian Mixture Model (GMM) and incorporates a multi-positive sample contrastive learning mechanism for comprehensive feature modeling. Additionally, we introduce a new strategy for cross-modal semantic alignment, which constrains the relative distances between image and text feature distributions, thereby improving the accuracy of cross-modal representations. We validate our approach through extensive experiments on four benchmark datasets, demonstrating superior performance over six state-of-the-art methods.
LLM-CoT Enhanced Graph Neural Recommendation with Harmonized Group Policy Optimization
May 18, 2025Graph neural networks (GNNs) have advanced recommender systems by modeling interaction relationships. However, existing graph-based recommenders rely on sparse ID features and do not fully exploit textual information, resulting in low information density within representations. Furthermore, graph contrastive learning faces challenges. Random negative sampling can introduce false negative samples, while fixed temperature coefficients cannot adapt to the heterogeneity of different nodes. In addition, current efforts to enhance recommendations with large language models (LLMs) have not fully utilized their Chain-of-Thought (CoT) reasoning capabilities to guide representation learning. To address these limitations, we introduces LGHRec (LLM-CoT Enhanced Graph Neural Recommendation with Harmonized Group Policy Optimization). This framework leverages the CoT reasoning ability of LLMs to generate semantic IDs, enriching reasoning processes and improving information density and semantic quality of representations. Moreover, we design a reinforcement learning algorithm, Harmonized Group Policy Optimization (HGPO), to optimize negative sampling strategies and temperature coefficients in contrastive learning. This approach enhances long-tail recommendation performance and ensures optimization consistency across different groups. Experimental results on three datasets demonstrate that LGHRec improves representation quality through semantic IDs generated by LLM's CoT reasoning and effectively boosts contrastive learning with HGPO. Our method outperforms several baseline models. The code is available at: https://anonymous.4open.science/r/LLM-Rec.
Cognitive Memory in Large Language Models
Apr 03, 2025This paper examines memory mechanisms in Large Language Models (LLMs), emphasizing their importance for context-rich responses, reduced hallucinations, and improved efficiency. It categorizes memory into sensory, short-term, and long-term, with sensory memory corresponding to input prompts, short-term memory processing immediate context, and long-term memory implemented via external databases or structures. The text-based memory section covers acquisition (selection and summarization), management (updating, accessing, storing, and resolving conflicts), and utilization (full-text search, SQL queries, semantic search). The KV cache-based memory section discusses selection methods (regularity-based summarization, score-based approaches, special token embeddings) and compression techniques (low-rank compression, KV merging, multimodal compression), along with management strategies like offloading and shared attention mechanisms. Parameter-based memory methods (LoRA, TTT, MoE) transform memories into model parameters to enhance efficiency, while hidden-state-based memory approaches (chunk mechanisms, recurrent transformers, Mamba model) improve long-text processing by combining RNN hidden states with current methods. Overall, the paper offers a comprehensive analysis of LLM memory mechanisms, highlighting their significance and future research directions.
DynRsl-VLM: Enhancing Autonomous Driving Perception with Dynamic Resolution Vision-Language Models
Mar 14, 2025Visual Question Answering (VQA) models, which fall under the category of vision-language models, conventionally execute multiple downsampling processes on image inputs to strike a balance between computational efficiency and model performance. Although this approach aids in concentrating on salient features and diminishing computational burden, it incurs the loss of vital detailed information, a drawback that is particularly damaging in end-to-end autonomous driving scenarios. Downsampling can lead to an inadequate capture of distant or small objects such as pedestrians, road signs, or obstacles, all of which are crucial for safe navigation. This loss of features negatively impacts an autonomous driving system's capacity to accurately perceive the environment, potentially escalating the risk of accidents. To tackle this problem, we put forward the Dynamic Resolution Vision Language Model (DynRsl-VLM). DynRsl-VLM incorporates a dynamic resolution image input processing approach that captures all entity feature information within an image while ensuring that the image input remains computationally tractable for the Vision Transformer (ViT). Moreover, we devise a novel image-text alignment module to replace the Q-Former, enabling simple and efficient alignment with text when dealing with dynamic resolution image inputs. Our method enhances the environmental perception capabilities of autonomous driving systems without overstepping computational constraints.
Synthetic Lung X-ray Generation through Cross-Attention and Affinity Transformation
Mar 10, 2025Collecting and annotating medical images is a time-consuming and resource-intensive task. However, generating synthetic data through models such as Diffusion offers a cost-effective alternative. This paper introduces a new method for the automatic generation of accurate semantic masks from synthetic lung X-ray images based on a stable diffusion model trained on text-image pairs. This method uses cross-attention mapping between text and image to extend text-driven image synthesis to semantic mask generation. It employs text-guided cross-attention information to identify specific areas in an image and combines this with innovative techniques to produce high-resolution, class-differentiated pixel masks. This approach significantly reduces the costs associated with data collection and annotation. The experimental results demonstrate that segmentation models trained on synthetic data generated using the method are comparable to, and in some cases even better than, models trained on real datasets. This shows the effectiveness of the method and its potential to revolutionize medical image analysis.