 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynRsl-VLM: Enhancing Autonomous Driving Perception with Dynamic Resolution Vision-Language Models
Mar 14, 2025Visual Question Answering (VQA) models, which fall under the category of vision-language models, conventionally execute multiple downsampling processes on image inputs to strike a balance between computational efficiency and model performance. Although this approach aids in concentrating on salient features and diminishing computational burden, it incurs the loss of vital detailed information, a drawback that is particularly damaging in end-to-end autonomous driving scenarios. Downsampling can lead to an inadequate capture of distant or small objects such as pedestrians, road signs, or obstacles, all of which are crucial for safe navigation. This loss of features negatively impacts an autonomous driving system's capacity to accurately perceive the environment, potentially escalating the risk of accidents. To tackle this problem, we put forward the Dynamic Resolution Vision Language Model (DynRsl-VLM). DynRsl-VLM incorporates a dynamic resolution image input processing approach that captures all entity feature information within an image while ensuring that the image input remains computationally tractable for the Vision Transformer (ViT). Moreover, we devise a novel image-text alignment module to replace the Q-Former, enabling simple and efficient alignment with text when dealing with dynamic resolution image inputs. Our method enhances the environmental perception capabilities of autonomous driving systems without overstepping computational constraints.
Federated Learning with Positive and Unlabeled Data
Jun 21, 2021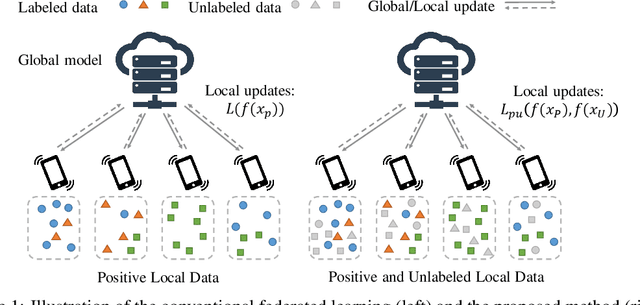
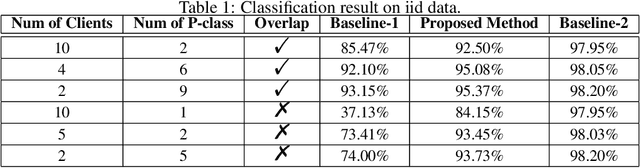
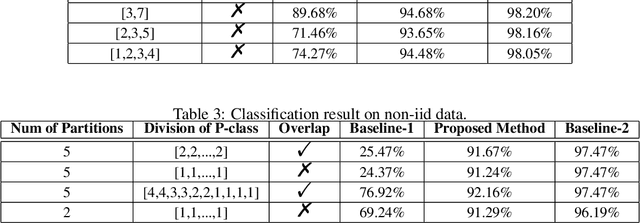
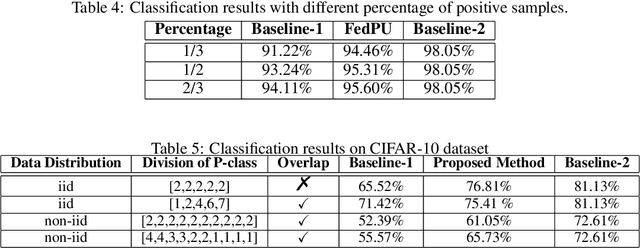
We study the problem of learning from positive and unlabeled (PU) data in the federated setting, where each client only labels a little part of their dataset due to the limitation of resources and time. Different from the settings in traditional PU learning where the negative class consists of a single class, the negative samples which cannot be identified by a client in the federated setting may come from multiple classes which are unknown to the client. Therefore, existing PU learning methods can be hardly applied in this situation. To address this problem, we propose a novel framework, namely Federated learning with Positive and Unlabeled data (FedPU), to minimize the expected risk of multiple negative classes by leveraging the labeled data in other clients. We theoretically prove that the proposed FedPU can achieve a generalization bound which is no worse than $C\sqrt{C}$ times (where $C$ denotes the number of classes) of the fully-supervised model. Empirical experiments show that the FedPU can achieve much better performance than conventional learning methods which can only use positive data.
Read, Retrospect, Select: An MRC Framework to Short Text Entity Linking
Jan 07, 2021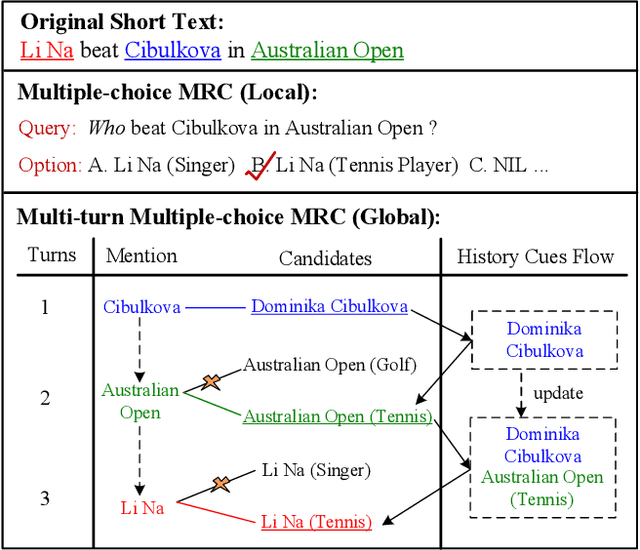
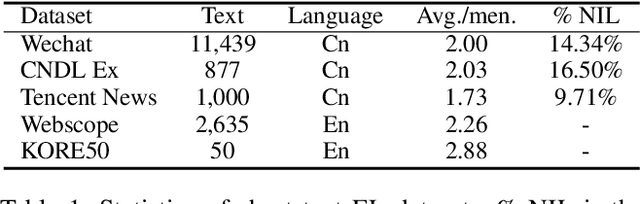
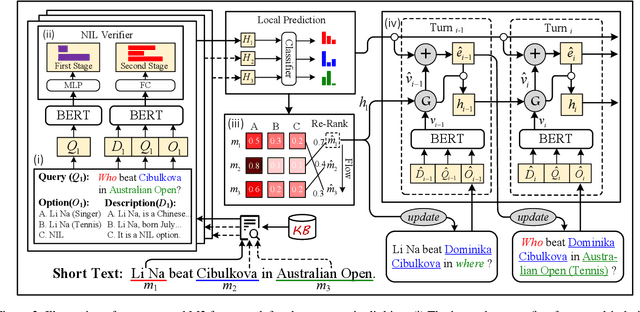
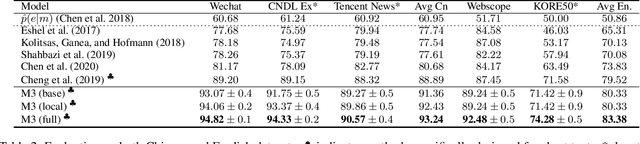
Entity linking (EL) for the rapidly growing short text (e.g. search queries and news titles) is critical to industrial applications. Most existing approaches relying on adequate context for long text EL are not effective for the concise and sparse short text. In this paper, we propose a novel framework called Multi-turn Multiple-choice Machine reading comprehension (M3}) to solve the short text EL from a new perspective: a query is generated for each ambiguous mention exploiting its surrounding context, and an option selection module is employed to identify the golden entity from candidates using the query. In this way, M3 framework sufficiently interacts limited context with candidate entities during the encoding process, as well as implicitly considers the dissimilarities inside the candidate bunch in the selection stage. In addition, we design a two-stage verifier incorporated into M3 to address the commonly existed unlinkable problem in short text. To further consider the topical coherence and interdependence among referred entities, M3 leverages a multi-turn fashion to deal with mentions in a sequence manner by retrospecting historical cues. Evaluation shows that our M3 framework achieves the state-of-the-art performance on five Chinese and English datasets for the real-world short text EL.