 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Positive and Unlabeled Data
Paper and Code
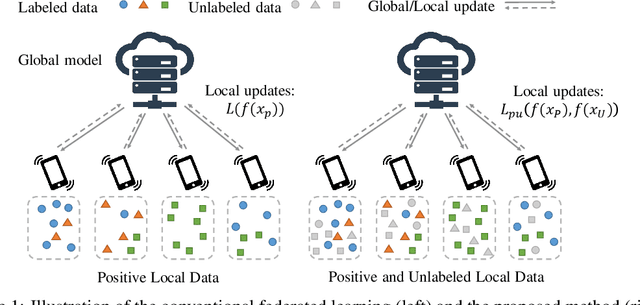
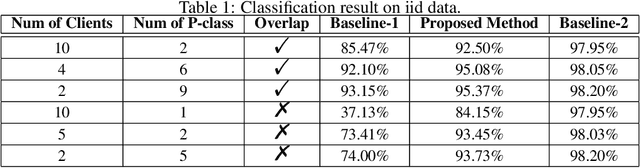
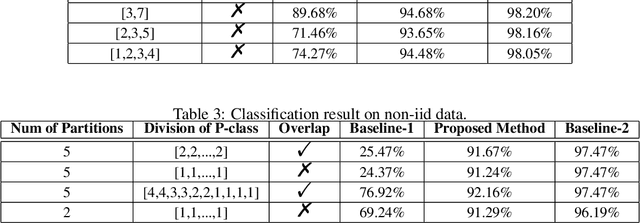
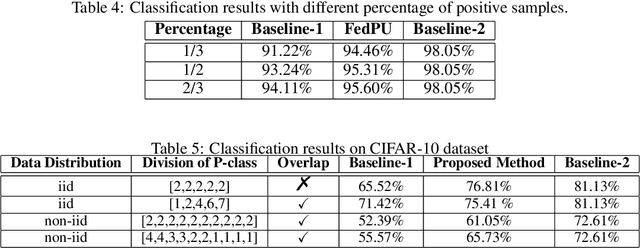
We study the problem of learning from positive and unlabeled (PU) data in the federated setting, where each client only labels a little part of their dataset due to the limitation of resources and time. Different from the settings in traditional PU learning where the negative class consists of a single class, the negative samples which cannot be identified by a client in the federated setting may come from multiple classes which are unknown to the client. Therefore, existing PU learning methods can be hardly applied in this situation. To address this problem, we propose a novel framework, namely Federated learning with Positive and Unlabeled data (FedPU), to minimize the expected risk of multiple negative classes by leveraging the labeled data in other clients. We theoretically prove that the proposed FedPU can achieve a generalization bound which is no worse than $C\sqrt{C}$ times (where $C$ denotes the number of classes) of the fully-supervised model. Empirical experiments show that the FedPU can achieve much better performance than conventional learning methods which can only use positive data.