 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Target: From Imitation to Collaboration in Speculative Decoding
May 24, 2026Speculative decoding (SPD) accelerates large language model (LLM) inference by letting a smaller draft model propose multiple future tokens that are verified in parallel by a larger target model. The dominant SPD paradigm treats the target model as the sole reliable teacher, accepting a draft token only when it exactly matches the target prediction. This design implicitly assumes that the target is always the better choice at every position. In practice, this assumption does not hold. Although the draft is the weaker model overall, it is not uniformly inferior at the token level. In a meaningful fraction of cases where draft and target disagree, the draft's choice is the one that leads to the correct final answer. Inspired by this, we introduce \textbf{Collaborative Speculative Decoding (CoSpec)}, a generalization of SPD that no longer treats the target model as the sole token-level authority. CoSpec trains an arbitration policy via reinforcement learning to decide whether to accept tokens from the draft or target model, selectively accepting draft tokens at mismatches when doing so is likely to yield a correct final answer. Experimental results show that CoSpec maintains substantial speedups while surpassing target-only performance. By shifting the emphasis from imitation to collaboration, CoSpec suggests a new perspective on speculative decoding.
Learnable Permutation for Structured Sparsity on Transformer Models
Jan 30, 2026Structured sparsity has emerged as a popular model pruning technique, widely adopted in various architectures, including CNNs, Transformer models, and especially large language models (LLMs) in recent years. A promising direction to further improve post-pruning performance is weight permutation, which reorders model weights into patterns more amenable to pruning. However, the exponential growth of the permutation search space with the scale of Transformer architectures forces most methods to rely on greedy or heuristic algorithms, limiting the effectiveness of reordering. In this work, we propose a novel end-to-end learnable permutation framework. Our method introduces a learnable permutation cost matrix to quantify the cost of swapping any two input channels of a given weight matrix, a differentiable bipartite matching solver to obtain the optimal binary permutation matrix given a cost matrix, and a sparsity optimization loss function to directly optimize the permutation operator. We extensively validate our approach on vision and language Transformers, demonstrating that our method achieves state-of-the-art permutation results for structured sparsity.
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
Aug 21, 2025Long-context inference in large language models (LLMs) is increasingly constrained by the KV cache bottleneck: memory usage grows linearly with sequence length, while attention computation scales quadratically. Existing approaches address this issue by compressing the KV cache along the temporal axis through strategies such as token eviction or merging to reduce memory and computational overhead. However, these methods often neglect fine-grained importance variations across feature dimensions (i.e., the channel axis), thereby limiting their ability to effectively balance efficiency and model accuracy. In reality, we observe that channel saliency varies dramatically across both queries and positions: certain feature channels carry near-zero information for a given query, while others spike in relevance. To address this oversight, we propose SPARK, a training-free plug-and-play method that applies unstructured sparsity by pruning KV at the channel level, while dynamically restoring the pruned entries during attention score computation. Notably, our approach is orthogonal to existing KV compression and quantization techniques, making it compatible for integration with them to achieve further acceleration. By reducing channel-level redundancy, SPARK enables processing of longer sequences within the same memory budget. For sequences of equal length, SPARK not only preserves or improves model accuracy but also reduces KV cache storage by over 30% compared to eviction-based methods. Furthermore, even with an aggressive pruning ratio of 80%, SPARK maintains performance with less degradation than 5% compared to the baseline eviction method, demonstrating its robustness and effectiveness. Our code will be available at https://github.com/Xnhyacinth/SparK.
Gumiho: A Hybrid Architecture to Prioritize Early Tokens in Speculative Decoding
Mar 13, 2025Speculative decoding (SPD) aims to accelerate the auto-regressive token generation process of a target Large Language Model (LLM). Some approaches employ a draft model with multiple heads to predict a sequence of future tokens, where each head handles a token in the sequence. The target LLM verifies the predicted sequence and accepts aligned tokens, enabling efficient multi-token generation. However, existing methods assume that all tokens within a sequence are equally important, employing identical head structures and relying on a single-generation paradigm, either serial or parallel. To this end, we theoretically demonstrate that initial tokens in the draft sequence are more important than later ones. Building on this insight, we propose Gumiho, a hybrid model combining serial and parallel heads. Specifically, given the critical importance of early tokens, we employ a sophisticated Transformer architecture for the early draft heads in a serial configuration to improve accuracy. For later tokens, we utilize multiple lightweight MLP heads operating in parallel to enhance efficiency. By allocating more advanced model structures and longer running times to the early heads, Gumiho achieves improved overall performance. The experimental results demonstrate that our method outperforms existing approaches, fully validating its effectiveness.
Týr-the-Pruner: Unlocking Accurate 50% Structural Pruning for LLMs via Global Sparsity Distribution Optimization
Mar 12, 2025Structural pruning enhances hardware-agnostic inference efficiency for large language models (LLMs) but often struggles to maintain performance. Local pruning performs efficient layer-by-layer compression but ignores global topology. Global pruning has the potential to find the optimal solution although resource-intensive. However, existing methods tend to rank structural saliency uniformly, ignoring inter-structure dependencies and failing to achieve end-to-end optimization. To address these limitations, we propose T\'yr-the-Pruner, an efficient end-to-end search-based global structural pruning framework. This framework constructs a supernet by repeatedly applying local pruning across a range of sparsity ratios to each layer in an LLM, with the core goal of determining the optimal sparsity distribution under a target overall sparsity ratio. Concretely, we introduce an effective local pruning and an expectation error accumulation approach to improve supernet construction. Furthermore, we employ an iterative prune-and-search strategy with coarse-to-fine sparsity granularity to ensure efficient search convergence. Experimental results show that T\'yr-the-Pruner achieves state-of-the-art structural pruning, retaining 97% of the dense model's performance while removing a challenging 50% of Llama-3.1-70B's parameters.
Optimizing Ride-Pooling Operations with Extended Pickup and Drop-Off Flexibility
Mar 11, 2025The Ride-Pool Matching Problem (RMP) is central to on-demand ride-pooling services, where vehicles must be matched with multiple requests while adhering to service constraints such as pickup delays, detour limits, and vehicle capacity. Most existing RMP solutions assume passengers are picked up and dropped off at their original locations, neglecting the potential for passengers to walk to nearby spots to meet vehicles. This assumption restricts the optimization potential in ride-pooling operations. In this paper, we propose a novel matching method that incorporates extended pickup and drop-off areas for passengers. We first design a tree-based approach to efficiently generate feasible matches between passengers and vehicles. Next, we optimize vehicle routes to cover all designated pickup and drop-off locations while minimizing total travel distance. Finally, we employ dynamic assignment strategies to achieve optimal matching outcomes. Experiments on city-scale taxi datasets demonstrate that our method improves the number of served requests by up to 13\% and average travel distance by up to 21\% compared to leading existing solutions, underscoring the potential of leveraging passenger mobility to significantly enhance ride-pooling service efficiency.
Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE
Feb 10, 2025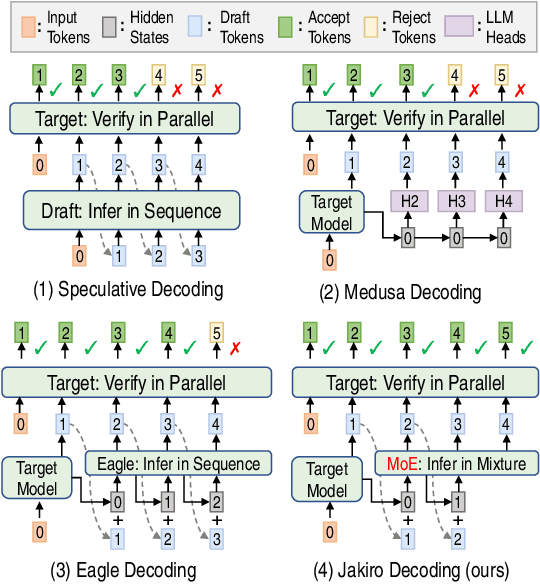
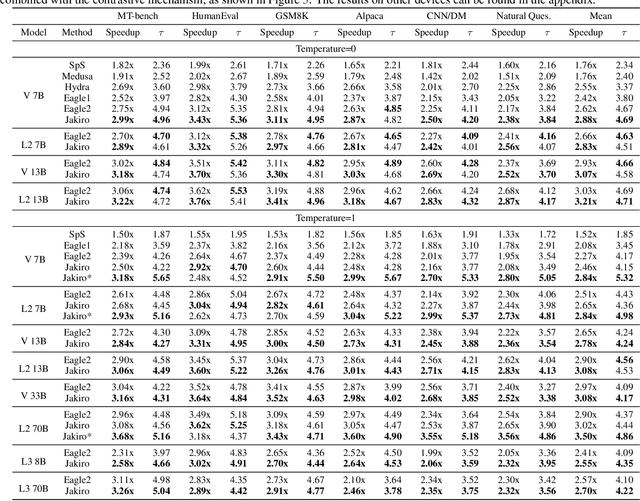
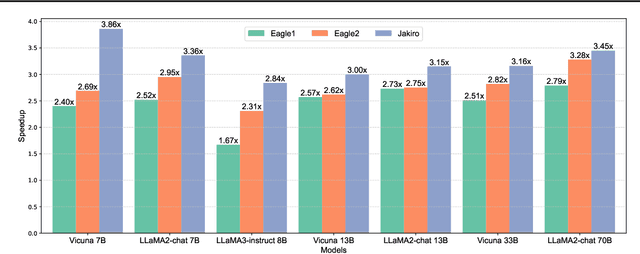
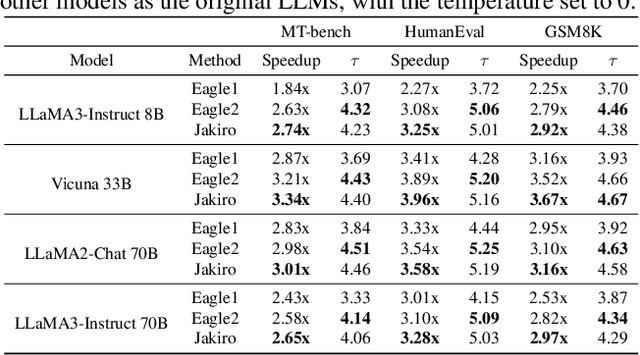
Speculative decoding (SD) accelerates large language model inference by using a smaller draft model to predict multiple tokens, which are then verified in parallel by the larger target model. However, the limited capacity of the draft model often necessitates tree-based sampling to improve prediction accuracy, where multiple candidates are generated at each step. We identify a key limitation in this approach: the candidates at the same step are derived from the same representation, limiting diversity and reducing overall effectiveness. To address this, we propose Jakiro, leveraging Mixture of Experts (MoE), where independent experts generate diverse predictions, effectively decoupling correlations among candidates. Furthermore, we introduce a hybrid inference strategy, combining autoregressive decoding for initial tokens with parallel decoding for subsequent stages, and enhance the latter with contrastive mechanism in features to improve accuracy. Our method significantly boosts prediction accuracy and achieves higher inference speedups. Extensive experiments across diverse models validate the effectiveness and robustness of our approach, establishing a new SOTA in speculative decoding. Our codes are available at https://github.com/haiduo/Jakiro.
MSWA: Refining Local Attention with Multi-ScaleWindow Attention
Jan 02, 2025



Transformer-based LLMs have achieved exceptional performance across a wide range of NLP tasks. However, the standard self-attention mechanism suffers from quadratic time complexity and linearly increased cache size. Sliding window attention (SWA) solves this problem by restricting the attention range to a fixed-size local context window. Nevertheless, SWA employs a uniform window size for each head in each layer, making it inefficient in capturing context of varying scales. To mitigate this limitation, we propose Multi-Scale Window Attention (MSWA) which applies diverse window sizes across heads and layers in the Transformer. It not only allows for different window sizes among heads within the same layer but also progressively increases window size allocation from shallow to deep layers, thus enabling the model to capture contextual information with different lengths and distances. Experimental results on language modeling and common-sense reasoning tasks substantiate that MSWA outperforms traditional local attention in both effectiveness and efficiency.
BiMLP: Compact Binary Architectures for Vision Multi-Layer Perceptrons
Dec 29, 2022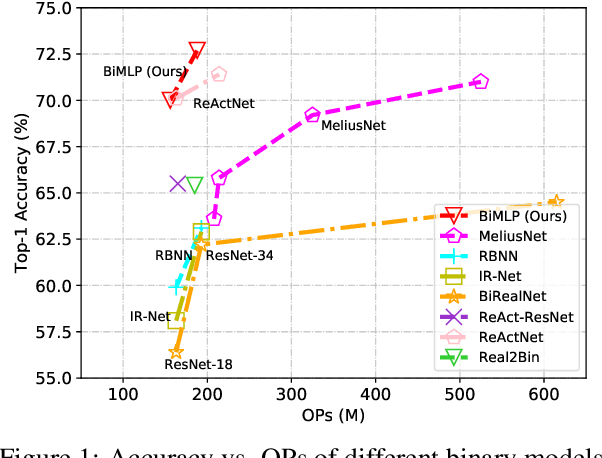
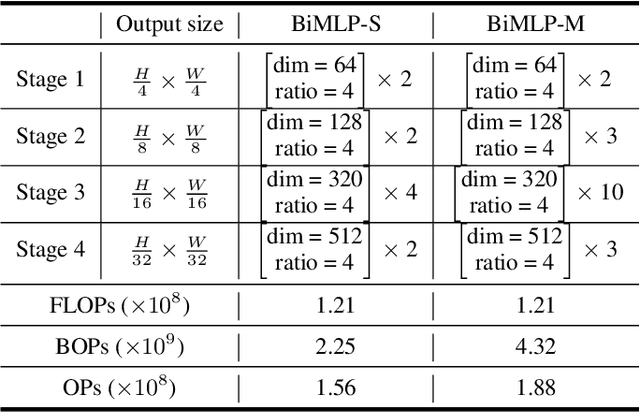
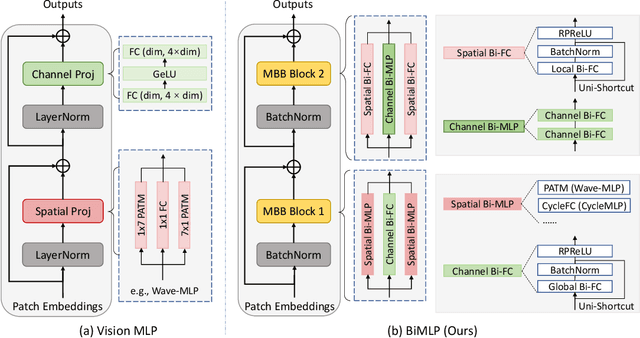
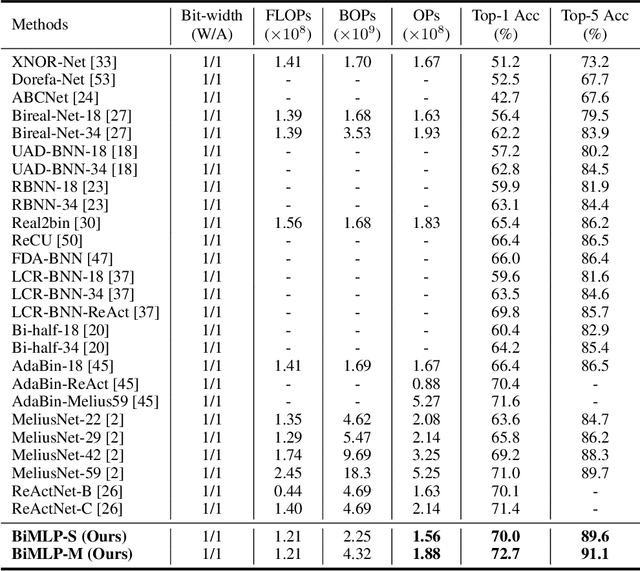
This paper studies the problem of designing compact binary architectures for vision multi-layer perceptrons (MLPs). We provide extensive analysis on the difficulty of binarizing vision MLPs and find that previous binarization methods perform poorly due to limited capacity of binary MLPs. In contrast with the traditional CNNs that utilizing convolutional operations with large kernel size, fully-connected (FC) layers in MLPs can be treated as convolutional layers with kernel size $1\times1$. Thus, the representation ability of the FC layers will be limited when being binarized, and places restrictions on the capability of spatial mixing and channel mixing on the intermediate features. To this end, we propose to improve the performance of binary MLP (BiMLP) model by enriching the representation ability of binary FC layers. We design a novel binary block that contains multiple branches to merge a series of outputs from the same stage, and also a universal shortcut connection that encourages the information flow from the previous stage. The downsampling layers are also carefully designed to reduce the computational complexity while maintaining the classification performance. Experimental results on benchmark dataset ImageNet-1k demonstrate the effectiveness of the proposed BiMLP models, which achieve state-of-the-art accuracy compared to prior binary CNNs. The MindSpore code is available at \url{https://gitee.com/mindspore/models/tree/master/research/cv/BiMLP}.
Source-Free Domain Adaptation via Distribution Estimation
Apr 24, 2022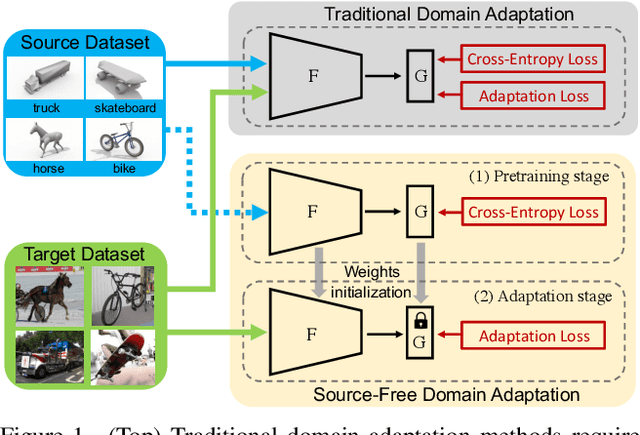
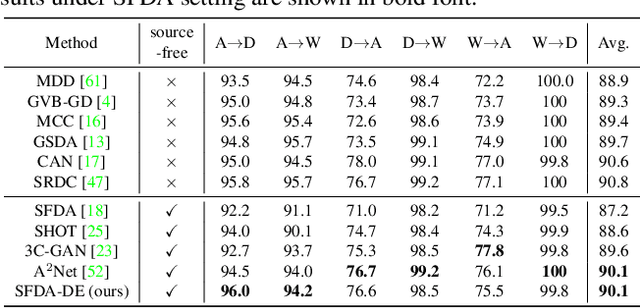
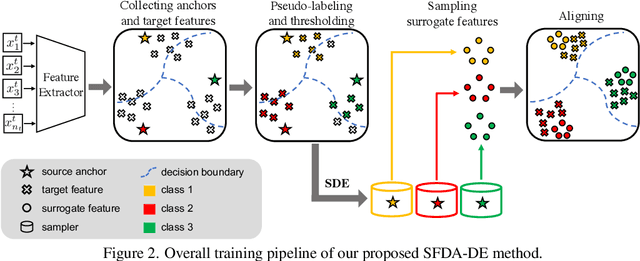
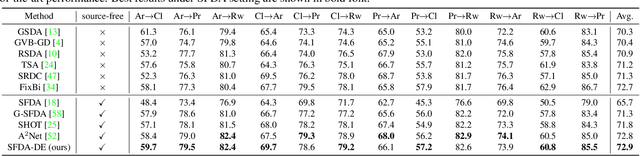
Domain Adaptation aims to transfer the knowledge learned from a labeled source domain to an unlabeled target domain whose data distributions are different. However, the training data in source domain required by most of the existing methods is usually unavailable in real-world applications due to privacy preserving policies. Recently, Source-Free Domain Adaptation (SFDA) has drawn much attention, which tries to tackle domain adaptation problem without using source data. In this work, we propose a novel framework called SFDA-DE to address SFDA task via source Distribution Estimation. Firstly, we produce robust pseudo-labels for target data with spherical k-means clustering, whose initial class centers are the weight vectors (anchors) learned by the classifier of pretrained model. Furthermore, we propose to estimate the class-conditioned feature distribution of source domain by exploiting target data and corresponding anchors. Finally, we sample surrogate features from the estimated distribution, which are then utilized to align two domains by minimizing a contrastive adaptation loss function. Extensive experiments show that the proposed method achieves state-of-the-art performance on multiple DA benchmarks, and even outperforms traditional DA methods which require plenty of source data.