 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Dec 29, 2025Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system's modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46$\times$ over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
CLOSE: Curriculum Learning On the Sharing Extent Towards Better One-shot NAS
Jul 16, 2022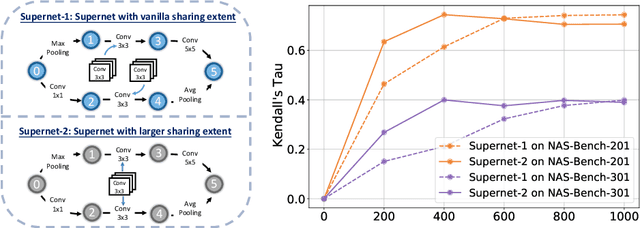
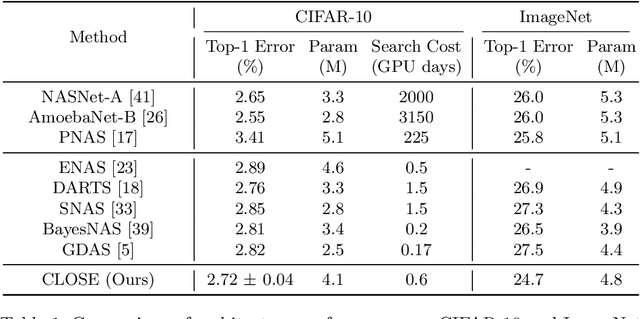
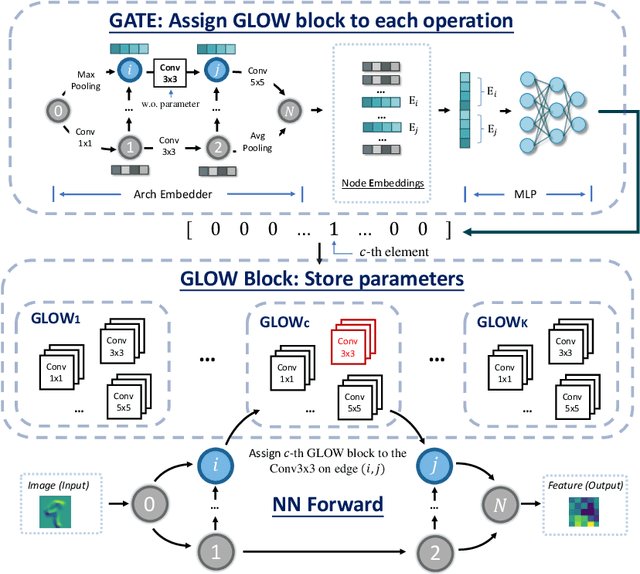

One-shot Neural Architecture Search (NAS) has been widely used to discover architectures due to its efficiency. However, previous studies reveal that one-shot performance estimations of architectures might not be well correlated with their performances in stand-alone training because of the excessive sharing of operation parameters (i.e., large sharing extent) between architectures. Thus, recent methods construct even more over-parameterized supernets to reduce the sharing extent. But these improved methods introduce a large number of extra parameters and thus cause an undesirable trade-off between the training costs and the ranking quality. To alleviate the above issues, we propose to apply Curriculum Learning On Sharing Extent (CLOSE) to train the supernet both efficiently and effectively. Specifically, we train the supernet with a large sharing extent (an easier curriculum) at the beginning and gradually decrease the sharing extent of the supernet (a harder curriculum). To support this training strategy, we design a novel supernet (CLOSENet) that decouples the parameters from operations to realize a flexible sharing scheme and adjustable sharing extent. Extensive experiments demonstrate that CLOSE can obtain a better ranking quality across different computational budget constraints than other one-shot supernets, and is able to discover superior architectures when combined with various search strategies. Code is available at https://github.com/walkerning/aw_nas.
Greedy Network Enlarging
Aug 04, 2021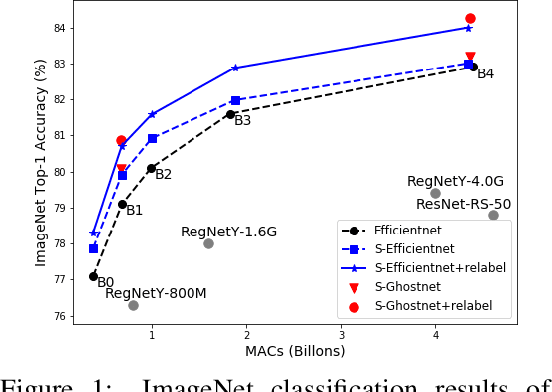
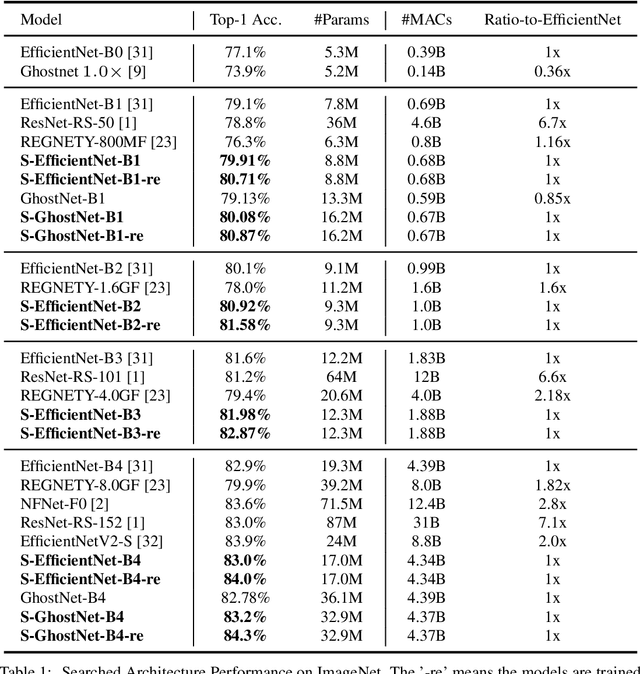
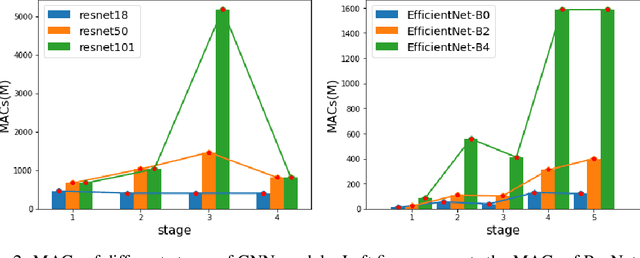
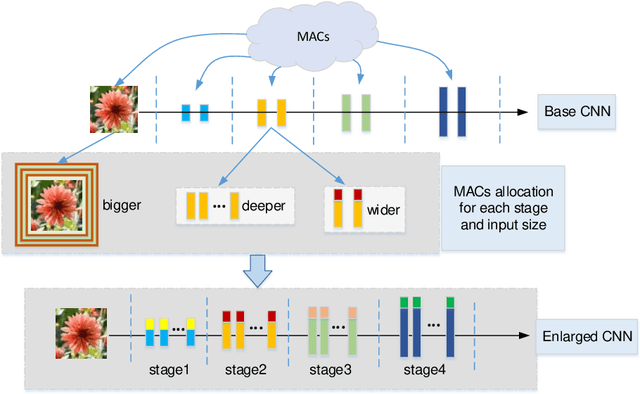
Recent studies on deep convolutional neural networks present a simple paradigm of architecture design, i.e., models with more MACs typically achieve better accuracy, such as EfficientNet and RegNet. These works try to enlarge all the stages in the model with one unified rule by sampling and statistical methods. However, we observe that some network architectures have similar MACs and accuracies, but their allocations on computations for different stages are quite different. In this paper, we propose to enlarge the capacity of CNN models by improving their width, depth and resolution on stage level. Under the assumption that the top-performing smaller CNNs are a proper subcomponent of the top-performing larger CNNs, we propose an greedy network enlarging method based on the reallocation of computations. With step-by-step modifying the computations on different stages, the enlarged network will be equipped with optimal allocation and utilization of MACs. On EfficientNet, our method consistently outperforms the performance of the original scaling method. In particular, with application of our method on GhostNet, we achieve state-of-the-art 80.9% and 84.3% ImageNet top-1 accuracies under the setting of 600M and 4.4B MACs, respectively.
Augmented Shortcuts for Vision Transformers
Jun 30, 2021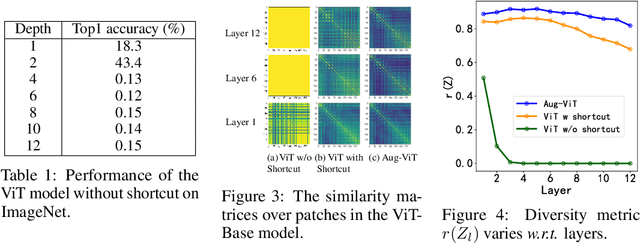
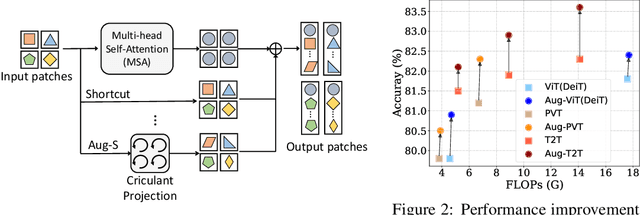
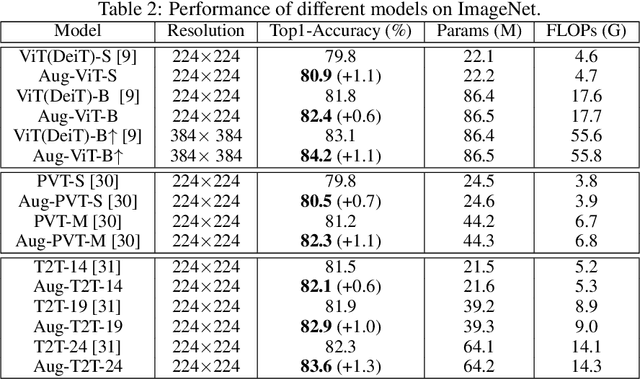
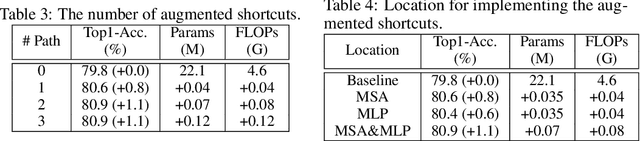
Transformer models have achieved great progress on computer vision tasks recently. The rapid development of vision transformers is mainly contributed by their high representation ability for extracting informative features from input images. However, the mainstream transformer models are designed with deep architectures, and the feature diversity will be continuously reduced as the depth increases, i.e., feature collapse. In this paper, we theoretically analyze the feature collapse phenomenon and study the relationship between shortcuts and feature diversity in these transformer models. Then, we present an augmented shortcut scheme, which inserts additional paths with learnable parameters in parallel on the original shortcuts. To save the computational costs, we further explore an efficient approach that uses the block-circulant projection to implement augmented shortcuts. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed method, which brings about 1% accuracy increase of the state-of-the-art visual transformers without obviously increasing their parameters and FLOPs.
Federated Learning with Positive and Unlabeled Data
Jun 21, 2021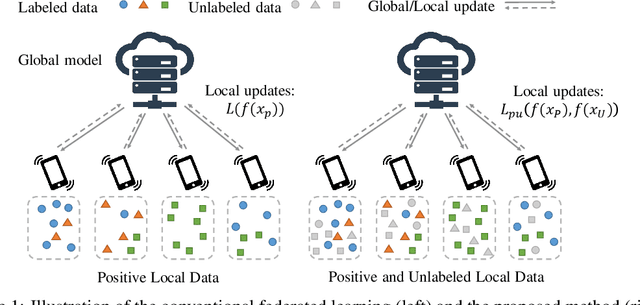
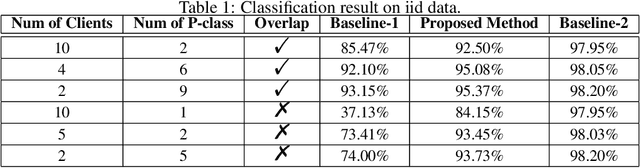
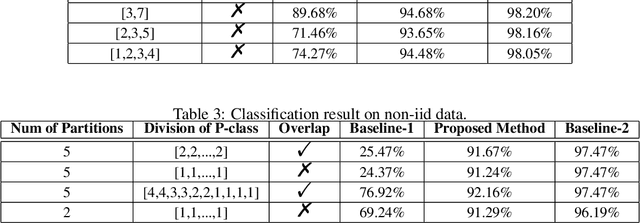
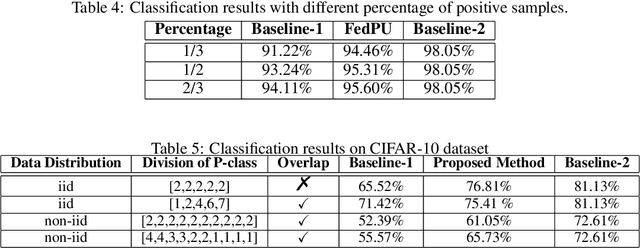
We study the problem of learning from positive and unlabeled (PU) data in the federated setting, where each client only labels a little part of their dataset due to the limitation of resources and time. Different from the settings in traditional PU learning where the negative class consists of a single class, the negative samples which cannot be identified by a client in the federated setting may come from multiple classes which are unknown to the client. Therefore, existing PU learning methods can be hardly applied in this situation. To address this problem, we propose a novel framework, namely Federated learning with Positive and Unlabeled data (FedPU), to minimize the expected risk of multiple negative classes by leveraging the labeled data in other clients. We theoretically prove that the proposed FedPU can achieve a generalization bound which is no worse than $C\sqrt{C}$ times (where $C$ denotes the number of classes) of the fully-supervised model. Empirical experiments show that the FedPU can achieve much better performance than conventional learning methods which can only use positive data.
Manifold Regularized Dynamic Network Pruning
Mar 10, 2021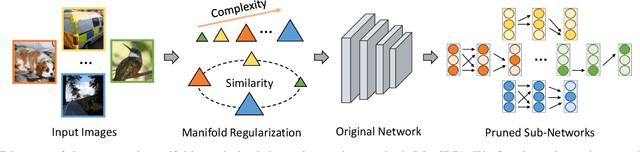
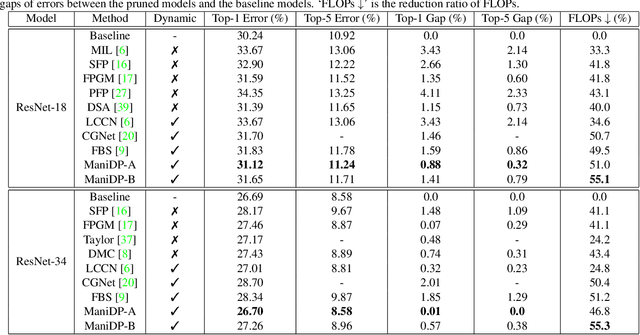
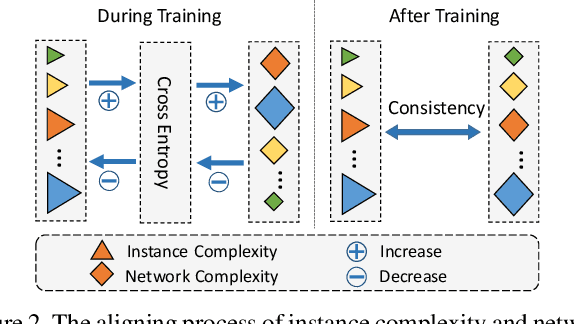
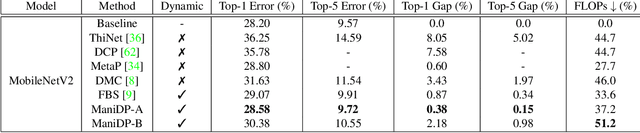
Neural network pruning is an essential approach for reducing the computational complexity of deep models so that they can be well deployed on resource-limited devices. Compared with conventional methods, the recently developed dynamic pruning methods determine redundant filters variant to each input instance which achieves higher acceleration. Most of the existing methods discover effective sub-networks for each instance independently and do not utilize the relationship between different inputs. To maximally excavate redundancy in the given network architecture, this paper proposes a new paradigm that dynamically removes redundant filters by embedding the manifold information of all instances into the space of pruned networks (dubbed as ManiDP). We first investigate the recognition complexity and feature similarity between images in the training set. Then, the manifold relationship between instances and the pruned sub-networks will be aligned in the training procedure. The effectiveness of the proposed method is verified on several benchmarks, which shows better performance in terms of both accuracy and computational cost compared to the state-of-the-art methods. For example, our method can reduce 55.3% FLOPs of ResNet-34 with only 0.57% top-1 accuracy degradation on ImageNet.
GhostSR: Learning Ghost Features for Efficient Image Super-Resolution
Jan 21, 2021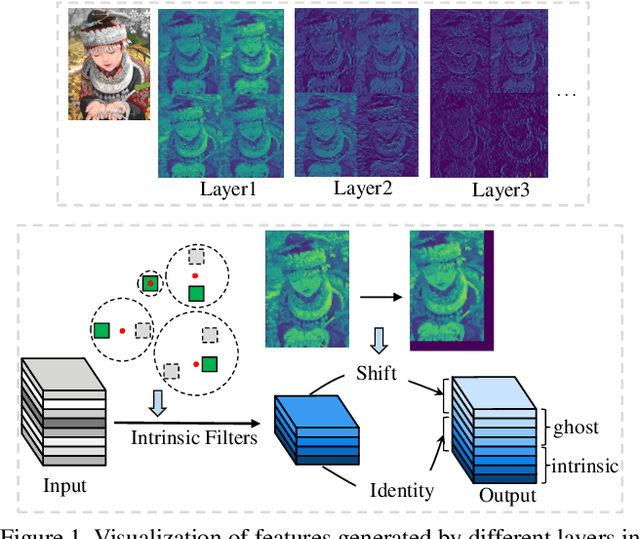
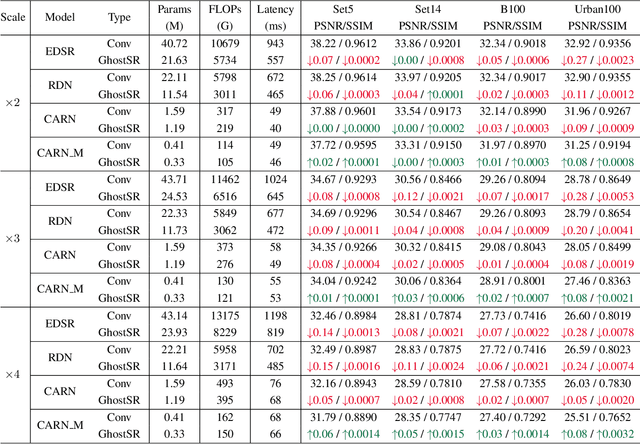
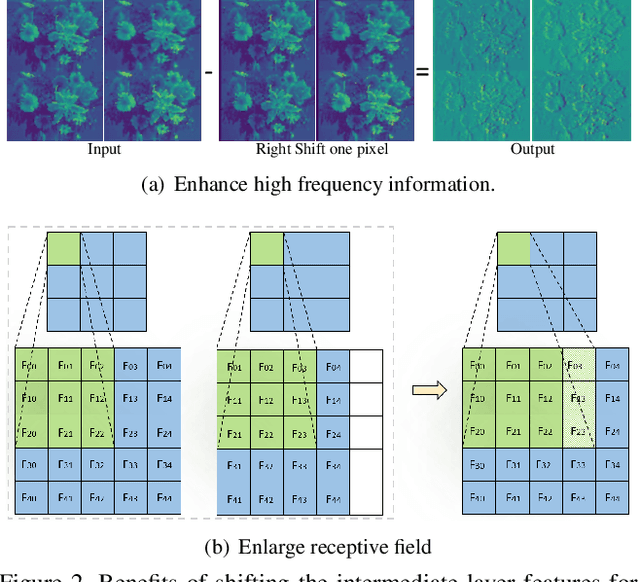
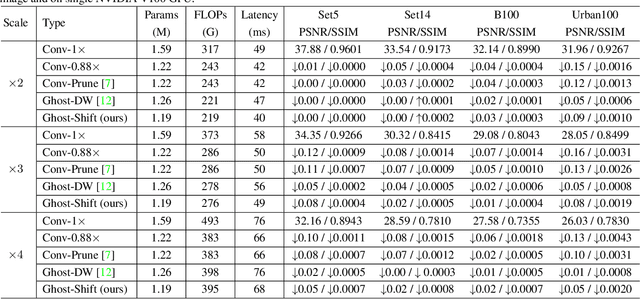
Modern single image super-resolution (SISR) system based on convolutional neural networks (CNNs) achieves fancy performance while requires huge computational costs. The problem on feature redundancy is well studied in visual recognition task, but rarely discussed in SISR. Based on the observation that many features in SISR models are also similar to each other, we propose to use shift operation to generate the redundant features (i.e., Ghost features). Compared with depth-wise convolution which is not friendly to GPUs or NPUs, shift operation can bring practical inference acceleration for CNNs on common hardware. We analyze the benefits of shift operation for SISR and make the shift orientation learnable based on Gumbel-Softmax trick. For a given pre-trained model, we first cluster all filters in each convolutional layer to identify the intrinsic ones for generating intrinsic features. Ghost features will be derived by moving these intrinsic features along a specific orientation. The complete output features are constructed by concatenating the intrinsic and ghost features together. Extensive experiments on several benchmark models and datasets demonstrate that both the non-compact and lightweight SISR models embedded in our proposed module can achieve comparable performance to that of their baselines with large reduction of parameters, FLOPs and GPU latency. For instance, we reduce the parameters by 47%, FLOPs by 46% and GPU latency by 41% of EDSR x2 network without significant performance degradation.
Pre-Trained Image Processing Transformer
Dec 03, 2020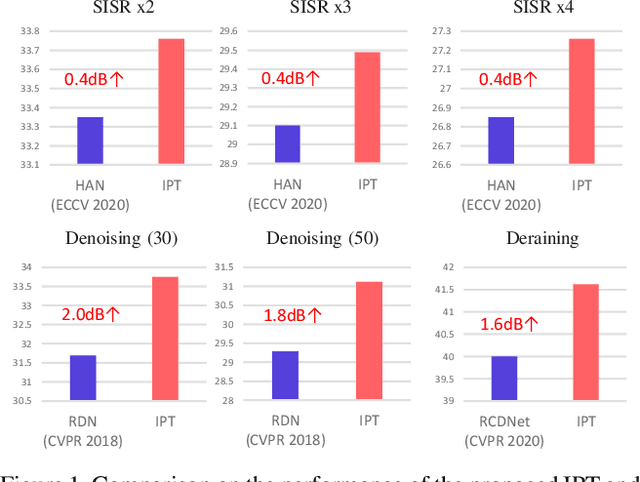
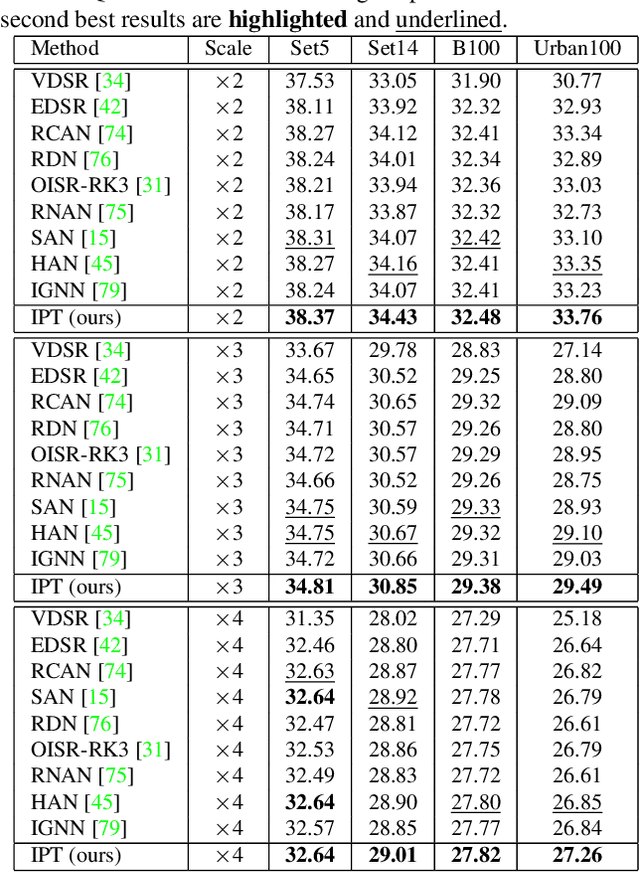
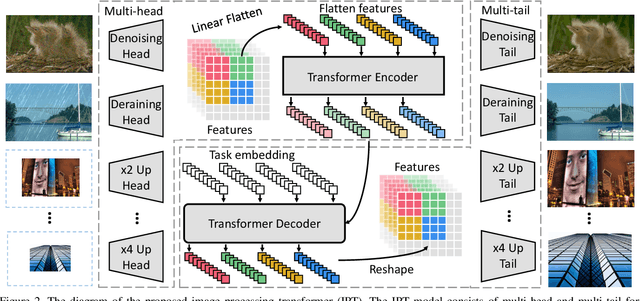
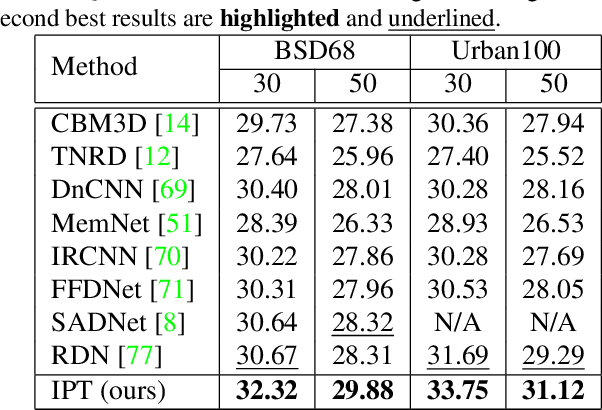
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.