 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Policy: Accelerating On-Policy Distillation via Asynchronous Generation and Selective Packing
May 07, 2026Standard knowledge distillation for autoregressive models often suffers from distribution mismatch. While on-policy methods mitigate this by leveraging student-generated outputs, they rely on computationally expensive Reinforcement Learning (RL) frameworks. To improve efficiency, we propose Near-Policy Distillation (NPD), an asynchronous approach that decouples student generation from training. This reformulation enables Supervised Fine-Tuning (SFT) with sequence packing. However, asynchronous updates inevitably introduce policy lag and sample noise, which can cause the behavior to drift from near-policy toward off-policy. To counteract this without sacrificing efficiency, NPD integrates sparse student updates and the $Δ$-IFD filtering mechanism, a heuristic sample selection mechanism that empirically stabilizes the optimization trajectory. By filtering extreme out-of-distribution samples, $Δ$-IFD prevents noise from dominating the gradients, ensuring updates remain within a safe proximal learning zone. Empirically, the NPD framework achieves a 8.1x speedup over on-policy baselines and outperforms SFT by 8.09%. Crucially, by effectively narrowing the exploration space for subsequent RL, our method enables openPangu-Embedded-1B to reach a state-of-the-art score of 68.73%, outperforming the substantially larger Qwen3-1.7B. Codes will be released soon.
Revealing the Power of Post-Training for Small Language Models via Knowledge Distillation
Sep 30, 2025The rapid advancement of large language models (LLMs) has significantly advanced the capabilities of artificial intelligence across various domains. However, their massive scale and high computational costs render them unsuitable for direct deployment in resource-constrained edge environments. This creates a critical need for high-performance small models that can operate efficiently at the edge. Yet, after pre-training alone, these smaller models often fail to meet the performance requirements of complex tasks. To bridge this gap, we introduce a systematic post-training pipeline that efficiently enhances small model accuracy. Our post training pipeline consists of curriculum-based supervised fine-tuning (SFT) and offline on-policy knowledge distillation. The resulting instruction-tuned model achieves state-of-the-art performance among billion-parameter models, demonstrating strong generalization under strict hardware constraints while maintaining competitive accuracy across a variety of tasks. This work provides a practical and efficient solution for developing high-performance language models on Ascend edge devices.
Unshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
Feb 20, 2025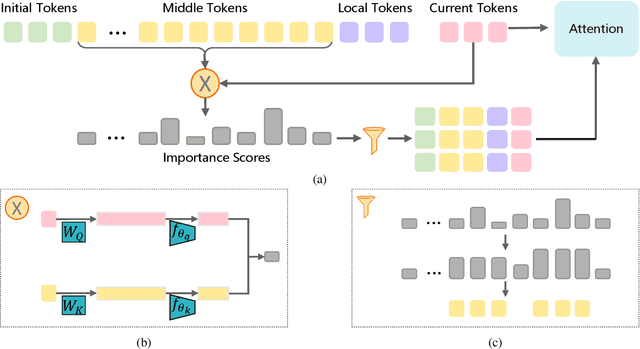
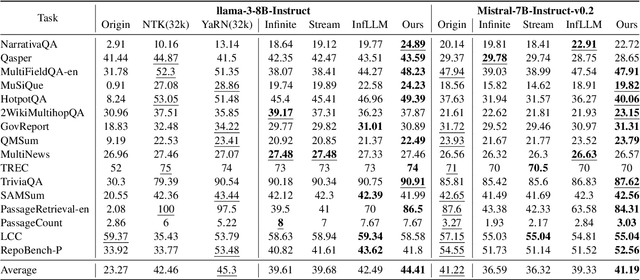
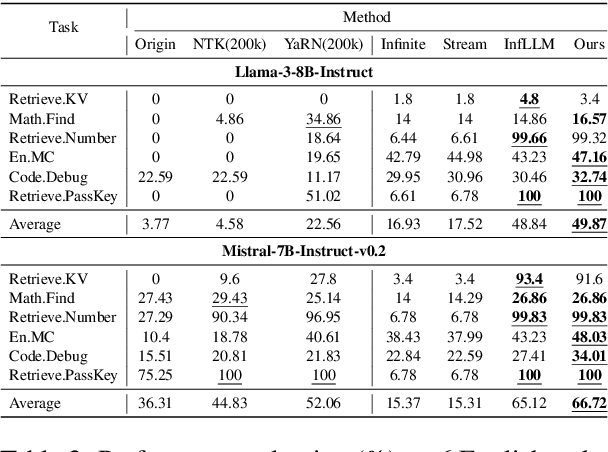
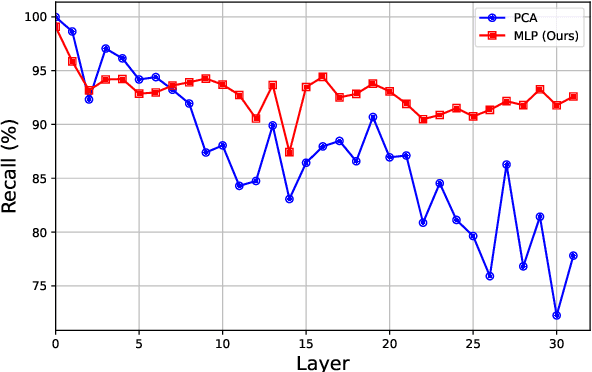
Handling long-context sequences efficiently remains a significant challenge in large language models (LLMs). Existing methods for token selection in sequence extrapolation either employ a permanent eviction strategy or select tokens by chunk, which may lead to the loss of critical information. We propose Efficient Selective Attention (ESA), a novel approach that extends context length by efficiently selecting the most critical tokens at the token level to compute attention. ESA reduces the computational complexity of token selection by compressing query and key vectors into lower-dimensional representations. We evaluate ESA on long sequence benchmarks with maximum lengths up to 256k using open-source LLMs with context lengths of 8k and 32k. ESA outperforms other selective attention methods, especially in tasks requiring the retrieval of multiple pieces of information, achieving comparable performance to full-attention extrapolation methods across various tasks, with superior results in certain tasks.
Greedy Network Enlarging
Aug 04, 2021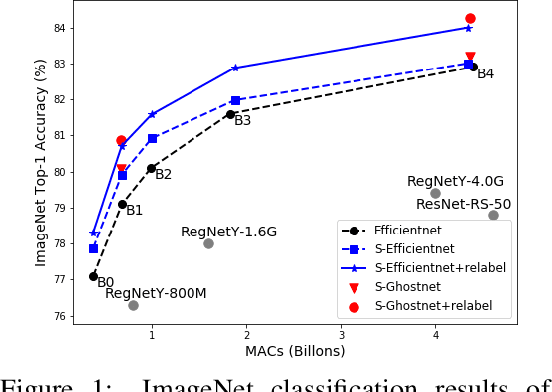
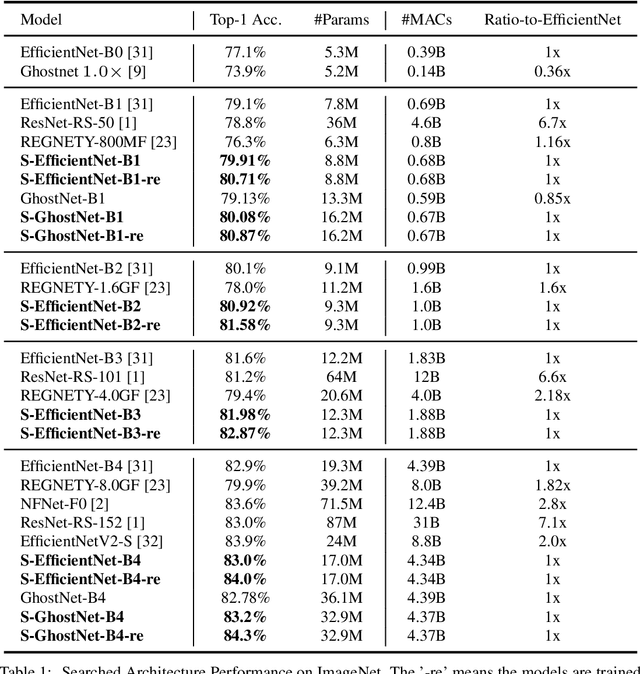
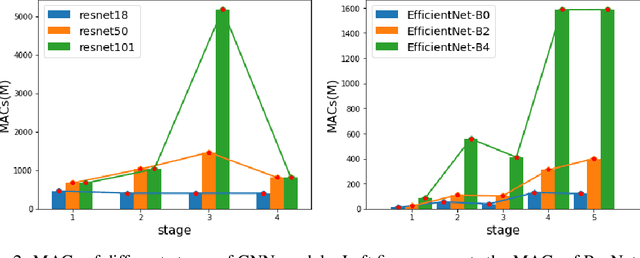
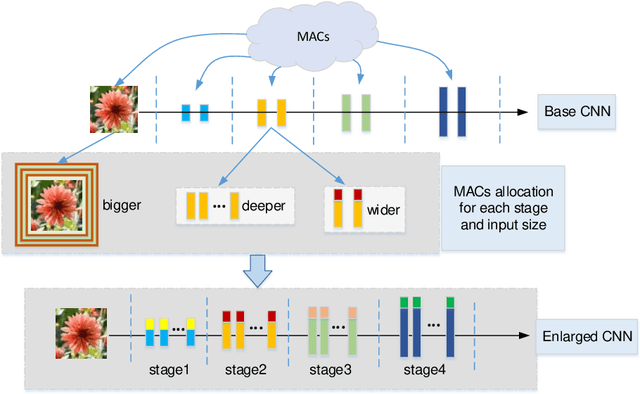
Recent studies on deep convolutional neural networks present a simple paradigm of architecture design, i.e., models with more MACs typically achieve better accuracy, such as EfficientNet and RegNet. These works try to enlarge all the stages in the model with one unified rule by sampling and statistical methods. However, we observe that some network architectures have similar MACs and accuracies, but their allocations on computations for different stages are quite different. In this paper, we propose to enlarge the capacity of CNN models by improving their width, depth and resolution on stage level. Under the assumption that the top-performing smaller CNNs are a proper subcomponent of the top-performing larger CNNs, we propose an greedy network enlarging method based on the reallocation of computations. With step-by-step modifying the computations on different stages, the enlarged network will be equipped with optimal allocation and utilization of MACs. On EfficientNet, our method consistently outperforms the performance of the original scaling method. In particular, with application of our method on GhostNet, we achieve state-of-the-art 80.9% and 84.3% ImageNet top-1 accuracies under the setting of 600M and 4.4B MACs, respectively.
Augmented Shortcuts for Vision Transformers
Jun 30, 2021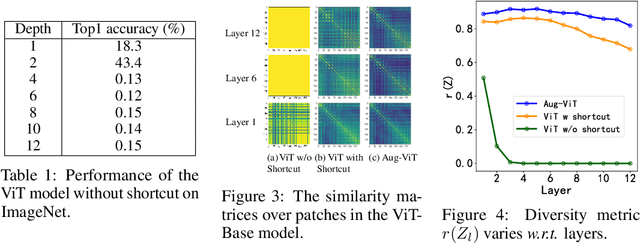
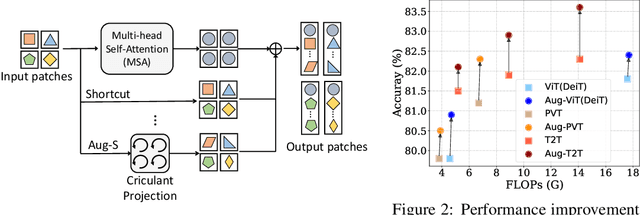
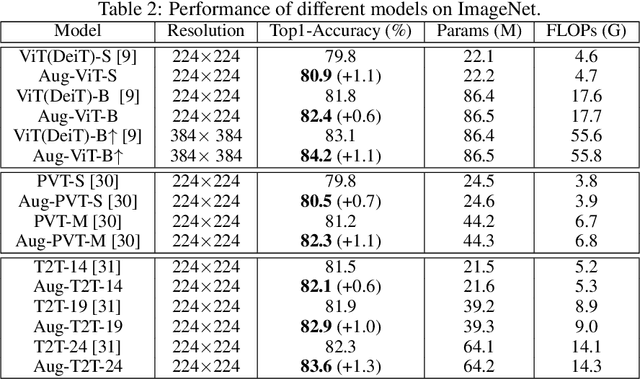
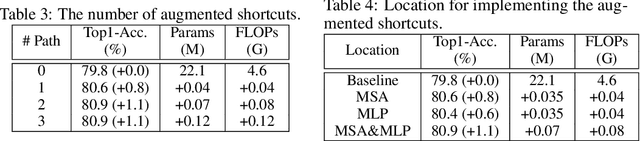
Transformer models have achieved great progress on computer vision tasks recently. The rapid development of vision transformers is mainly contributed by their high representation ability for extracting informative features from input images. However, the mainstream transformer models are designed with deep architectures, and the feature diversity will be continuously reduced as the depth increases, i.e., feature collapse. In this paper, we theoretically analyze the feature collapse phenomenon and study the relationship between shortcuts and feature diversity in these transformer models. Then, we present an augmented shortcut scheme, which inserts additional paths with learnable parameters in parallel on the original shortcuts. To save the computational costs, we further explore an efficient approach that uses the block-circulant projection to implement augmented shortcuts. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed method, which brings about 1% accuracy increase of the state-of-the-art visual transformers without obviously increasing their parameters and FLOPs.
Transformer in Transformer
Feb 27, 2021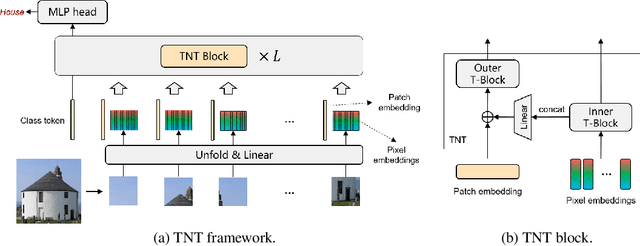

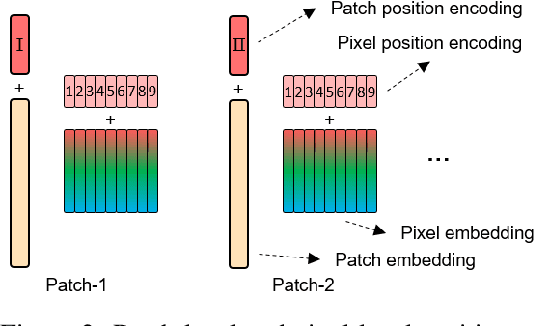
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves $81.3\%$ top-1 accuracy on ImageNet which is $1.5\%$ higher than that of DeiT with similar computational cost. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/TNT.
A Survey on Visual Transformer
Jan 30, 2021
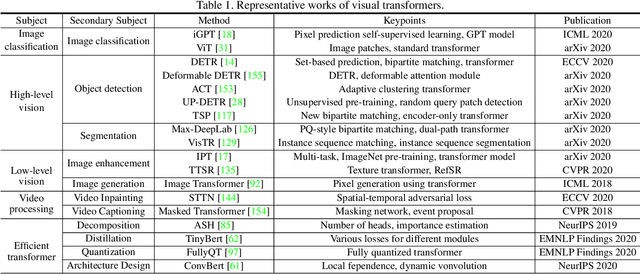
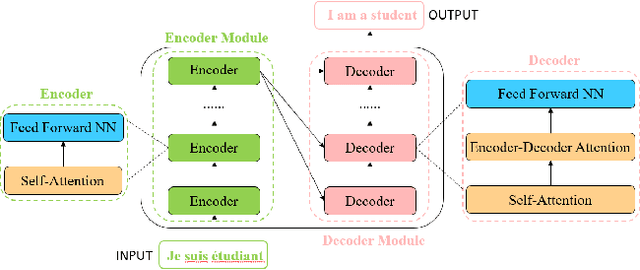
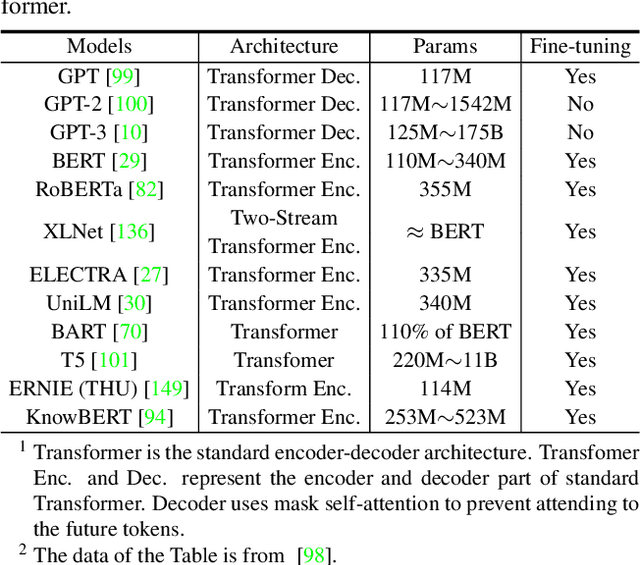
Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks. In a variety of visual benchmarks, transformer-based models perform similar to or better than other types of networks such as convolutional and recurrent networks. Given its high performance and no need for human-defined inductive bias, transformer is receiving more and more attention from the computer vision community. In this paper, we review these visual transformer models by categorizing them in different tasks and analyzing their advantages and disadvantages. The main categories we explore include the backbone network, high/mid-level vision, low-level vision, and video processing. We also take a brief look at the self-attention mechanism in computer vision, as it is the base component in transformer. Furthermore, we include efficient transformer methods for pushing transformer into real device-based applications. Toward the end of this paper, we discuss the challenges and provide several further research directions for visual transformers.
GhostSR: Learning Ghost Features for Efficient Image Super-Resolution
Jan 21, 2021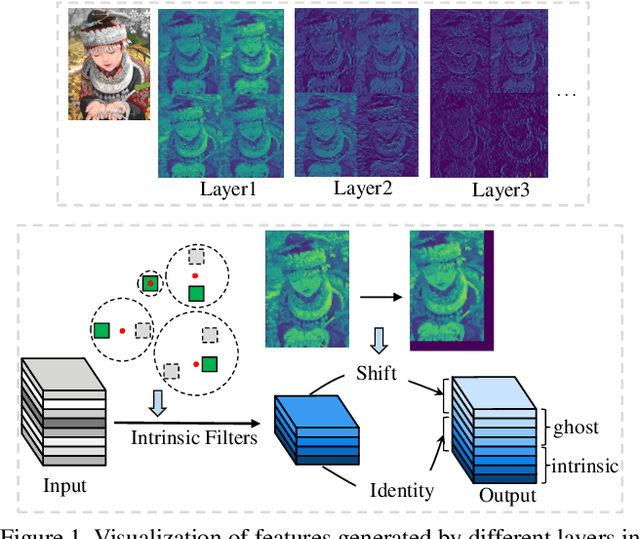
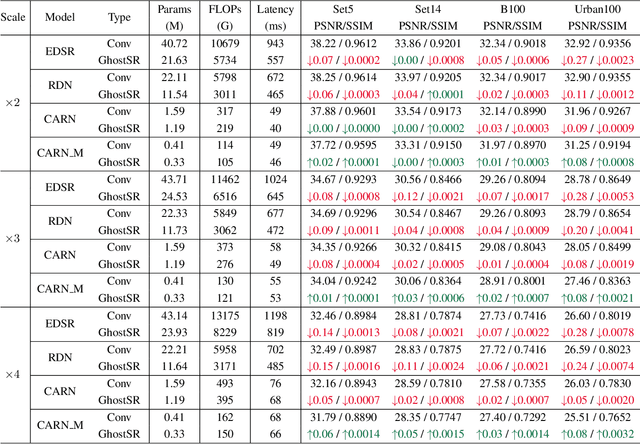
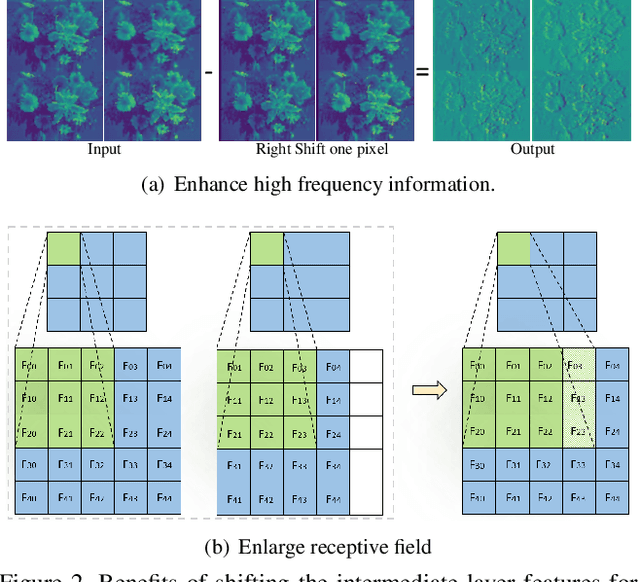
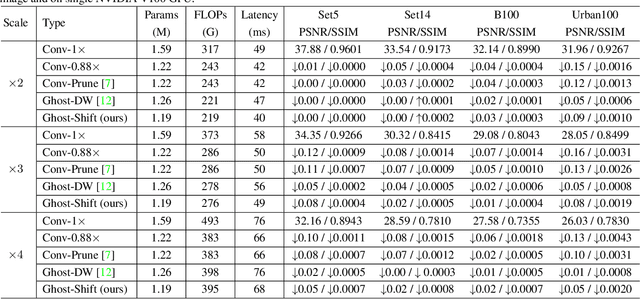
Modern single image super-resolution (SISR) system based on convolutional neural networks (CNNs) achieves fancy performance while requires huge computational costs. The problem on feature redundancy is well studied in visual recognition task, but rarely discussed in SISR. Based on the observation that many features in SISR models are also similar to each other, we propose to use shift operation to generate the redundant features (i.e., Ghost features). Compared with depth-wise convolution which is not friendly to GPUs or NPUs, shift operation can bring practical inference acceleration for CNNs on common hardware. We analyze the benefits of shift operation for SISR and make the shift orientation learnable based on Gumbel-Softmax trick. For a given pre-trained model, we first cluster all filters in each convolutional layer to identify the intrinsic ones for generating intrinsic features. Ghost features will be derived by moving these intrinsic features along a specific orientation. The complete output features are constructed by concatenating the intrinsic and ghost features together. Extensive experiments on several benchmark models and datasets demonstrate that both the non-compact and lightweight SISR models embedded in our proposed module can achieve comparable performance to that of their baselines with large reduction of parameters, FLOPs and GPU latency. For instance, we reduce the parameters by 47%, FLOPs by 46% and GPU latency by 41% of EDSR x2 network without significant performance degradation.
Weight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
Aug 05, 2020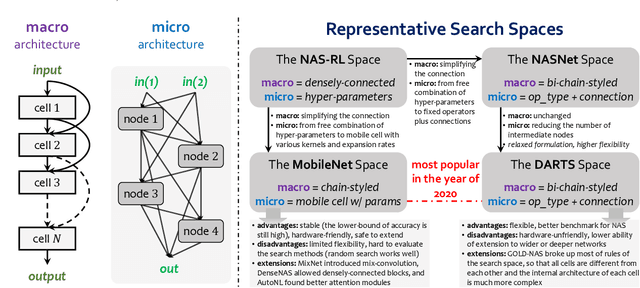
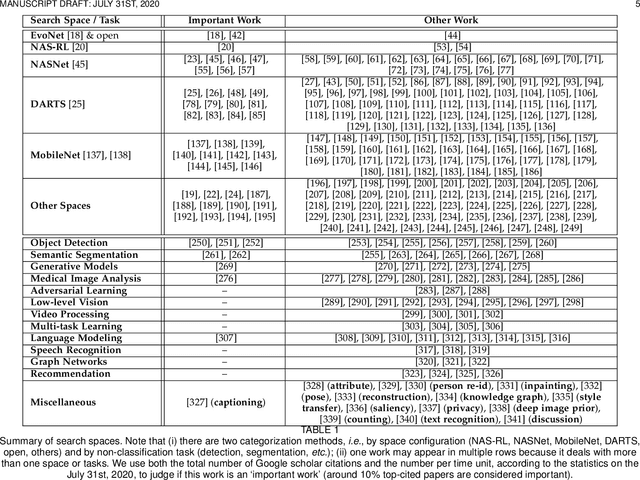
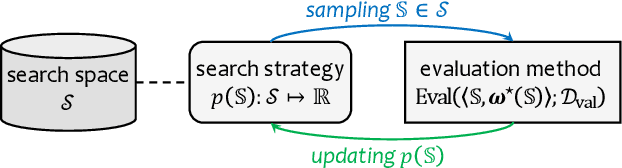
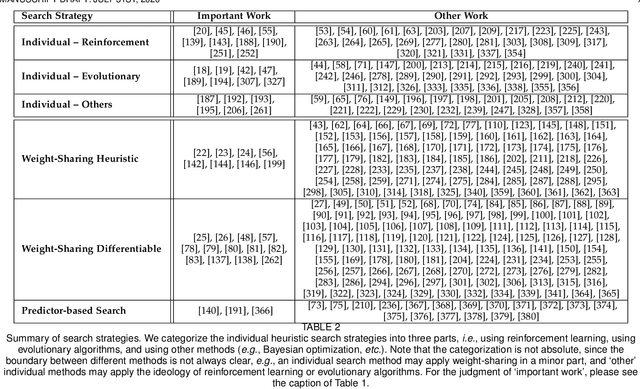
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.
Circumventing Outliers of AutoAugment with Knowledge Distillation
Mar 25, 2020
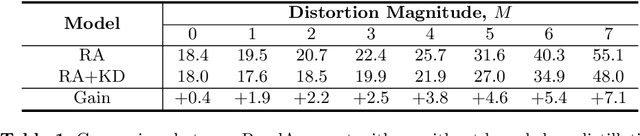
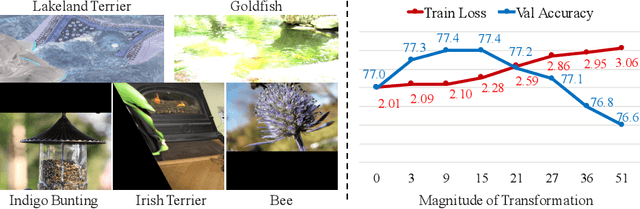
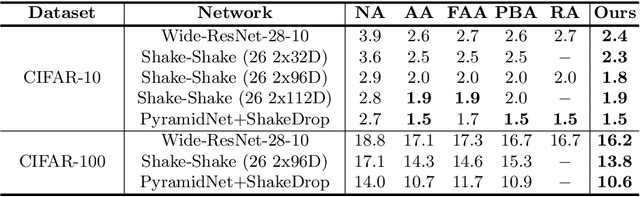
AutoAugment has been a powerful algorithm that improves the accuracy of many vision tasks, yet it is sensitive to the operator space as well as hyper-parameters, and an improper setting may degenerate network optimization. This paper delves deep into the working mechanism, and reveals that AutoAugment may remove part of discriminative information from the training image and so insisting on the ground-truth label is no longer the best option. To relieve the inaccuracy of supervision, we make use of knowledge distillation that refers to the output of a teacher model to guide network training. Experiments are performed in standard image classification benchmarks, and demonstrate the effectiveness of our approach in suppressing noise of data augmentation and stabilizing training. Upon the cooperation of knowledge distillation and AutoAugment, we claim the new state-of-the-art on ImageNet classification with a top-1 accuracy of 85.8%.