 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradually Compacting Large Language Models for Reasoning Like a Boiling Frog
Feb 04, 2026Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, but their substantial size often demands significant computational resources. To reduce resource consumption and accelerate inference, it is essential to eliminate redundant parameters without compromising performance. However, conventional pruning methods that directly remove such parameters often lead to a dramatic drop in model performance in reasoning tasks, and require extensive post-training to recover the lost capabilities. In this work, we propose a gradual compacting method that divides the compression process into multiple fine-grained iterations, applying a Prune-Tune Loop (PTL) at each stage to incrementally reduce model size while restoring performance with finetuning. This iterative approach-reminiscent of the "boiling frog" effect-enables the model to be progressively compressed without abrupt performance loss. Experimental results show that PTL can compress LLMs to nearly half their original size with only lightweight post-training, while maintaining performance comparable to the original model on reasoning tasks. Moreover, PTL is flexible and can be applied to various pruning strategies, such as neuron pruning and layer pruning, as well as different post-training methods, including continual pre-training and reinforcement learning. Additionally, experimental results confirm the effectiveness of PTL on a variety of tasks beyond mathematical reasoning, such as code generation, demonstrating its broad applicability.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
Fractured Chain-of-Thought Reasoning
May 19, 2025Inference-time scaling techniques have significantly bolstered the reasoning capabilities of large language models (LLMs) by harnessing additional computational effort at inference without retraining. Similarly, Chain-of-Thought (CoT) prompting and its extension, Long CoT, improve accuracy by generating rich intermediate reasoning trajectories, but these approaches incur substantial token costs that impede their deployment in latency-sensitive settings. In this work, we first show that truncated CoT, which stops reasoning before completion and directly generates the final answer, often matches full CoT sampling while using dramatically fewer tokens. Building on this insight, we introduce Fractured Sampling, a unified inference-time strategy that interpolates between full CoT and solution-only sampling along three orthogonal axes: (1) the number of reasoning trajectories, (2) the number of final solutions per trajectory, and (3) the depth at which reasoning traces are truncated. Through extensive experiments on five diverse reasoning benchmarks and several model scales, we demonstrate that Fractured Sampling consistently achieves superior accuracy-cost trade-offs, yielding steep log-linear scaling gains in Pass@k versus token budget. Our analysis reveals how to allocate computation across these dimensions to maximize performance, paving the way for more efficient and scalable LLM reasoning.
Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
May 15, 2025Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model's "aha moment". However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs' reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental "aha moments". Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10\% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional 2\% average gain in the performance ceiling across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
Scalable Chain of Thoughts via Elastic Reasoning
May 08, 2025Large reasoning models (LRMs) have achieved remarkable progress on complex tasks by generating extended chains of thought (CoT). However, their uncontrolled output lengths pose significant challenges for real-world deployment, where inference-time budgets on tokens, latency, or compute are strictly constrained. We propose Elastic Reasoning, a novel framework for scalable chain of thoughts that explicitly separates reasoning into two phases--thinking and solution--with independently allocated budgets. At test time, Elastic Reasoning prioritize that completeness of solution segments, significantly improving reliability under tight resource constraints. To train models that are robust to truncated thinking, we introduce a lightweight budget-constrained rollout strategy, integrated into GRPO, which teaches the model to reason adaptively when the thinking process is cut short and generalizes effectively to unseen budget constraints without additional training. Empirical results on mathematical (AIME, MATH500) and programming (LiveCodeBench, Codeforces) benchmarks demonstrate that Elastic Reasoning performs robustly under strict budget constraints, while incurring significantly lower training cost than baseline methods. Remarkably, our approach also produces more concise and efficient reasoning even in unconstrained settings. Elastic Reasoning offers a principled and practical solution to the pressing challenge of controllable reasoning at scale.
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
Apr 15, 2025



Reinforcement learning (RL) has become a prevailing approach for fine-tuning large language models (LLMs) on complex reasoning tasks. Among recent methods, GRPO stands out for its empirical success in training models such as DeepSeek-R1, yet the sources of its effectiveness remain poorly understood. In this work, we revisit GRPO from a reinforce-like algorithm perspective and analyze its core components. Surprisingly, we find that a simple rejection sampling baseline, RAFT, which trains only on positively rewarded samples, yields competitive performance than GRPO and PPO. Our ablation studies reveal that GRPO's main advantage arises from discarding prompts with entirely incorrect responses, rather than from its reward normalization. Motivated by this insight, we propose Reinforce-Rej, a minimal extension of policy gradient that filters both entirely incorrect and entirely correct samples. Reinforce-Rej improves KL efficiency and stability, serving as a lightweight yet effective alternative to more complex RL algorithms. We advocate RAFT as a robust and interpretable baseline, and suggest that future advances should focus on more principled designs for incorporating negative samples, rather than relying on them indiscriminately. Our findings provide guidance for future work in reward-based LLM post-training.
Entropy-Based Block Pruning for Efficient Large Language Models
Apr 04, 2025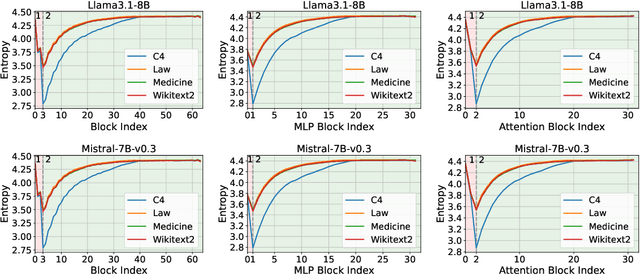
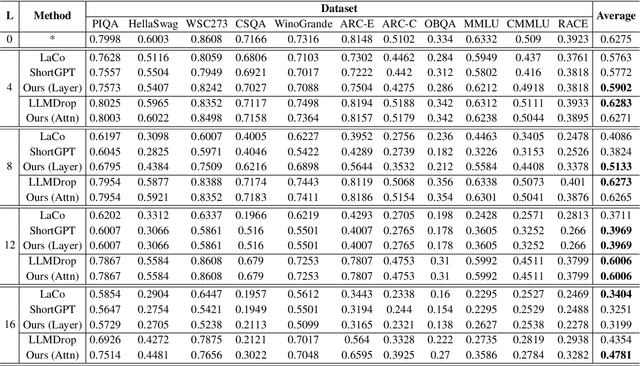
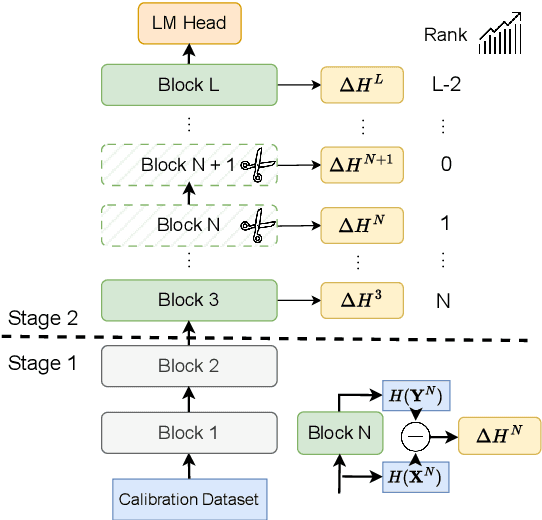
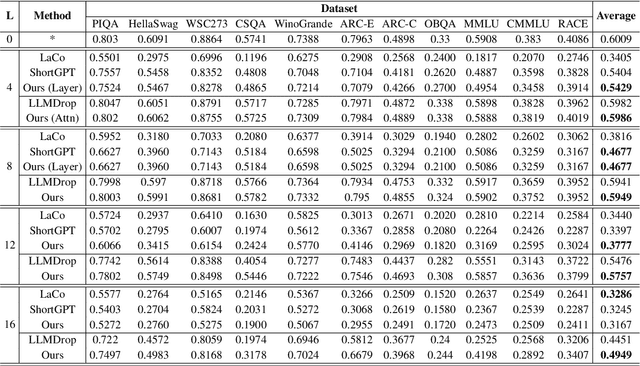
As large language models continue to scale, their growing computational and storage demands pose significant challenges for real-world deployment. In this work, we investigate redundancy within Transformer-based models and propose an entropy-based pruning strategy to enhance efficiency while maintaining performance. Empirical analysis reveals that the entropy of hidden representations decreases in the early blocks but progressively increases across most subsequent blocks. This trend suggests that entropy serves as a more effective measure of information richness within computation blocks. Unlike cosine similarity, which primarily captures geometric relationships, entropy directly quantifies uncertainty and information content, making it a more reliable criterion for pruning. Extensive experiments demonstrate that our entropy-based pruning approach surpasses cosine similarity-based methods in reducing model size while preserving accuracy, offering a promising direction for efficient model deployment.
Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum Scheduling
Feb 22, 2025



Cross-domain recommendation (CDR) is a task that aims to improve the recommendation performance in a target domain by leveraging the information from source domains. Contrastive learning methods have been widely adopted among intra-domain (intra-CL) and inter-domain (inter-CL) users/items for their representation learning and knowledge transfer during the matching stage of CDR. However, we observe that directly employing contrastive learning on mixed-up intra-CL and inter-CL tasks ignores the difficulty of learning from inter-domain over learning from intra-domain, and thus could cause severe training instability. Therefore, this instability deteriorates the representation learning process and hurts the quality of generated embeddings. To this end, we propose a novel framework named SCCDR built up on a separated intra-CL and inter-CL paradigm and a stop-gradient operation to handle the drawback. Specifically, SCCDR comprises two specialized curriculum stages: intra-inter separation and inter-domain curriculum scheduling. The former stage explicitly uses two distinct contrastive views for the intra-CL task in the source and target domains, respectively. Meanwhile, the latter stage deliberately tackles the inter-CL tasks with a curriculum scheduling strategy that derives effective curricula by accounting for the difficulty of negative samples anchored by overlapping users. Empirical experiments on various open-source datasets and an offline proprietary industrial dataset extracted from a real-world recommender system, and an online A/B test verify that SCCDR achieves state-of-the-art performance over multiple baselines.
Reward Models Identify Consistency, Not Causality
Feb 20, 2025Reward models (RMs) play a crucial role in aligning large language models (LLMs) with human preferences and enhancing reasoning quality. Traditionally, RMs are trained to rank candidate outputs based on their correctness and coherence. However, in this work, we present several surprising findings that challenge common assumptions about RM behavior. Our analysis reveals that state-of-the-art reward models prioritize structural consistency over causal correctness. Specifically, removing the problem statement has minimal impact on reward scores, whereas altering numerical values or disrupting the reasoning flow significantly affects RM outputs. Furthermore, RMs exhibit a strong dependence on complete reasoning trajectories truncated or incomplete steps lead to significant variations in reward assignments, indicating that RMs primarily rely on learned reasoning patterns rather than explicit problem comprehension. These findings hold across multiple architectures, datasets, and tasks, leading to three key insights: (1) RMs primarily assess coherence rather than true reasoning quality; (2) The role of explicit problem comprehension in reward assignment is overstated; (3) Current RMs may be more effective at ranking responses than verifying logical validity. Our results suggest a fundamental limitation in existing reward modeling approaches, emphasizing the need for a shift toward causality-aware reward models that go beyond consistency-driven evaluation.
Reward-Guided Speculative Decoding for Efficient LLM Reasoning
Jan 31, 2025



We introduce Reward-Guided Speculative Decoding (RSD), a novel framework aimed at improving the efficiency of inference in large language models (LLMs). RSD synergistically combines a lightweight draft model with a more powerful target model, incorporating a controlled bias to prioritize high-reward outputs, in contrast to existing speculative decoding methods that enforce strict unbiasedness. RSD employs a process reward model to evaluate intermediate decoding steps and dynamically decide whether to invoke the target model, optimizing the trade-off between computational cost and output quality. We theoretically demonstrate that a threshold-based mixture strategy achieves an optimal balance between resource utilization and performance. Extensive evaluations on challenging reasoning benchmarks, including Olympiad-level tasks, show that RSD delivers significant efficiency gains against decoding with the target model only (up to 4.4x fewer FLOPs), while achieving significant better accuracy than parallel decoding method on average (up to +3.5). These results highlight RSD as a robust and cost-effective approach for deploying LLMs in resource-intensive scenarios.