 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025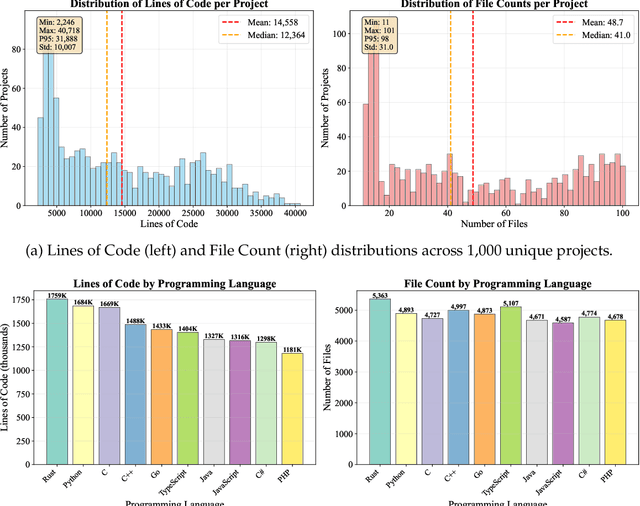
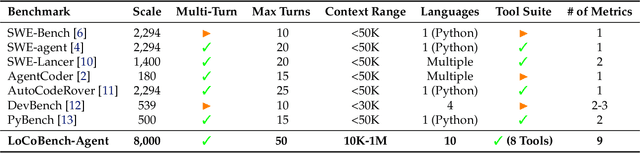

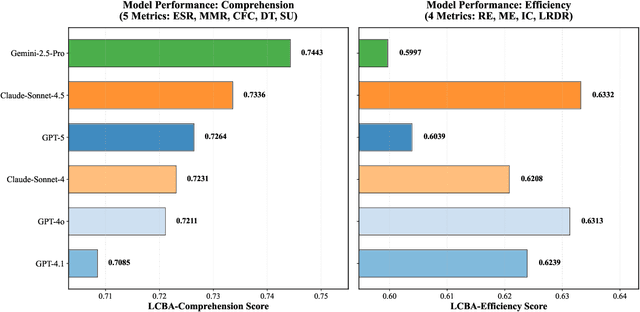
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025



The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
Entropy-Based Block Pruning for Efficient Large Language Models
Apr 04, 2025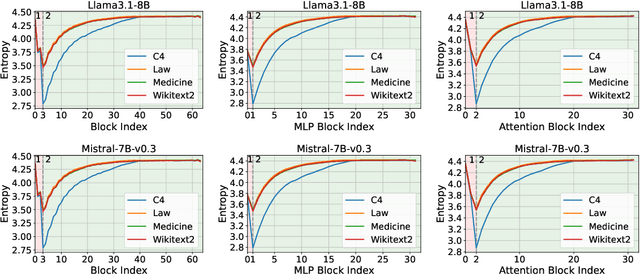
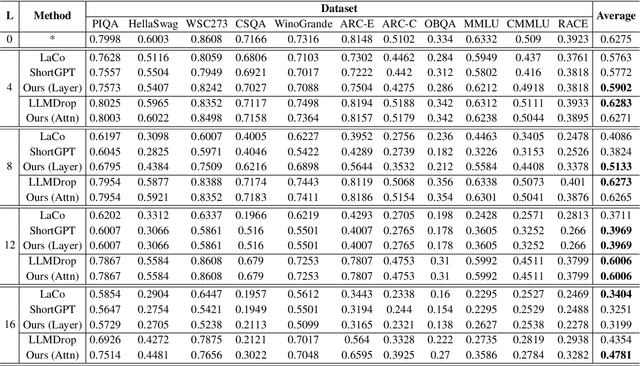
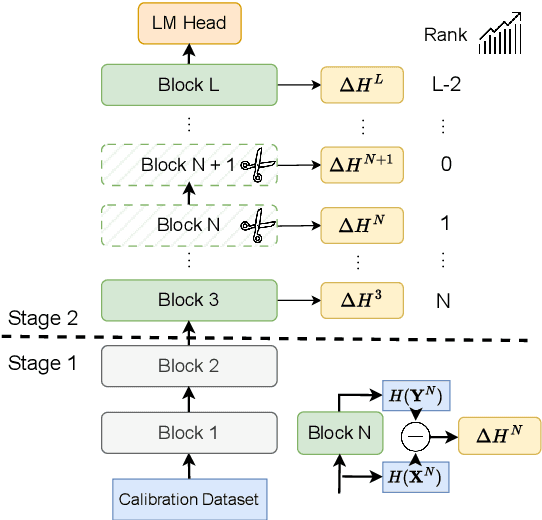
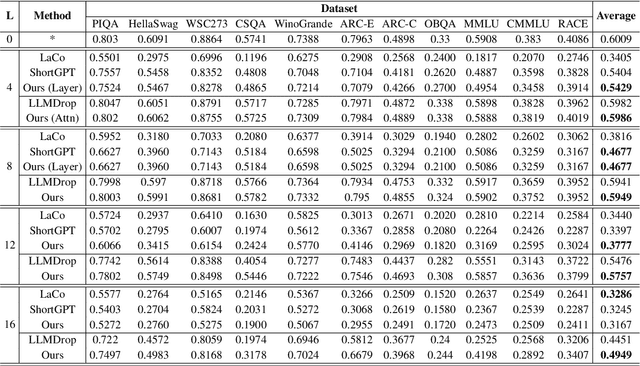
As large language models continue to scale, their growing computational and storage demands pose significant challenges for real-world deployment. In this work, we investigate redundancy within Transformer-based models and propose an entropy-based pruning strategy to enhance efficiency while maintaining performance. Empirical analysis reveals that the entropy of hidden representations decreases in the early blocks but progressively increases across most subsequent blocks. This trend suggests that entropy serves as a more effective measure of information richness within computation blocks. Unlike cosine similarity, which primarily captures geometric relationships, entropy directly quantifies uncertainty and information content, making it a more reliable criterion for pruning. Extensive experiments demonstrate that our entropy-based pruning approach surpasses cosine similarity-based methods in reducing model size while preserving accuracy, offering a promising direction for efficient model deployment.
ActionStudio: A Lightweight Framework for Data and Training of Large Action Models
Mar 31, 2025Action models are essential for enabling autonomous agents to perform complex tasks. However, training large action models remains challenging due to the diversity of agent environments and the complexity of agentic data. Despite growing interest, existing infrastructure provides limited support for scalable, agent-specific fine-tuning. We present ActionStudio, a lightweight and extensible data and training framework designed for large action models. ActionStudio unifies heterogeneous agent trajectories through a standardized format, supports diverse training paradigms including LoRA, full fine-tuning, and distributed setups, and integrates robust preprocessing and verification tools. We validate its effectiveness across both public and realistic industry benchmarks, demonstrating strong performance and practical scalability. We open-sourced code and data at https://github.com/SalesforceAIResearch/xLAM to facilitate research in the community.
PersonaBench: Evaluating AI Models on Understanding Personal Information through Accessing (Synthetic) Private User Data
Feb 28, 2025Personalization is critical in AI assistants, particularly in the context of private AI models that work with individual users. A key scenario in this domain involves enabling AI models to access and interpret a user's private data (e.g., conversation history, user-AI interactions, app usage) to understand personal details such as biographical information, preferences, and social connections. However, due to the sensitive nature of such data, there are no publicly available datasets that allow us to assess an AI model's ability to understand users through direct access to personal information. To address this gap, we introduce a synthetic data generation pipeline that creates diverse, realistic user profiles and private documents simulating human activities. Leveraging this synthetic data, we present PersonaBench, a benchmark designed to evaluate AI models' performance in understanding personal information derived from simulated private user data. We evaluate Retrieval-Augmented Generation (RAG) pipelines using questions directly related to a user's personal information, supported by the relevant private documents provided to the models. Our results reveal that current retrieval-augmented AI models struggle to answer private questions by extracting personal information from user documents, highlighting the need for improved methodologies to enhance personalization capabilities in AI.
A-MEM: Agentic Memory for LLM Agents
Feb 17, 2025While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems' fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code is available at https://github.com/WujiangXu/AgenticMemory.
TACO: Learning Multi-modal Action Models with Synthetic Chains-of-Thought-and-Action
Dec 10, 2024



While open-source multi-modal language models perform well on simple question answering tasks, they often fail on complex questions that require multiple capabilities, such as fine-grained recognition, visual grounding, and reasoning, and that demand multi-step solutions. We present TACO, a family of multi-modal large action models designed to improve performance on such complex, multi-step, and multi-modal tasks. During inference, TACO produces chains-of-thought-and-action (CoTA), executes intermediate steps by invoking external tools such as OCR, depth estimation and calculator, then integrates both the thoughts and action outputs to produce coherent responses. To train TACO, we create a large dataset of over 1M synthetic CoTA traces generated with GPT-4o and Python programs. We then experiment with various data filtering and mixing techniques and obtain a final subset of 293K high-quality CoTA examples. This dataset enables TACO to learn complex reasoning and action paths, surpassing existing models trained on instruction tuning data with only direct answers. Our model TACO outperforms the instruction-tuned baseline across 8 benchmarks, achieving a 3.6% improvement on average, with gains of up to 15% in MMVet tasks involving OCR, mathematical reasoning, and spatial reasoning. Training on high-quality CoTA traces sets a new standard for complex multi-modal reasoning, highlighting the need for structured, multi-step instruction tuning in advancing open-source mutli-modal models' capabilities.
SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs
Nov 20, 2024



Evaluating the output of Large Language Models (LLMs) is one of the most critical aspects of building a performant compound AI system. Since the output from LLMs propagate to downstream steps, identifying LLM errors is crucial to system performance. A common task for LLMs in AI systems is tool use. While there are several benchmark environments for evaluating LLMs on this task, they typically only give a success rate without any explanation of the failure cases. To solve this problem, we introduce SpecTool, a new benchmark to identify error patterns in LLM output on tool-use tasks. Our benchmark data set comprises of queries from diverse environments that can be used to test for the presence of seven newly characterized error patterns. Using SPECTOOL , we show that even the most prominent LLMs exhibit these error patterns in their outputs. Researchers can use the analysis and insights from SPECTOOL to guide their error mitigation strategies.
PRACT: Optimizing Principled Reasoning and Acting of LLM Agent
Oct 24, 2024



We introduce the Principled Reasoning and Acting (PRAct) framework, a novel method for learning and enforcing action principles from trajectory data. Central to our approach is the use of text gradients from a reflection and optimization engine to derive these action principles. To adapt action principles to specific task requirements, we propose a new optimization framework, Reflective Principle Optimization (RPO). After execution, RPO employs a reflector to critique current action principles and an optimizer to update them accordingly. We develop the RPO framework under two scenarios: Reward-RPO, which uses environmental rewards for reflection, and Self-RPO, which conducts self-reflection without external rewards. Additionally, two RPO methods, RPO-Traj and RPO-Batch, is introduced to adapt to different settings. Experimental results across four environments demonstrate that the PRAct agent, leveraging the RPO framework, effectively learns and applies action principles to enhance performance.