 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Aug 06, 2025Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
SemiSAM+: Rethinking Semi-Supervised Medical Image Segmentation in the Era of Foundation Models
Feb 28, 2025



Deep learning-based medical image segmentation typically requires large amount of labeled data for training, making it less applicable in clinical settings due to high annotation cost. Semi-supervised learning (SSL) has emerged as an appealing strategy due to its less dependence on acquiring abundant annotations from experts compared to fully supervised methods. Beyond existing model-centric advancements of SSL by designing novel regularization strategies, we anticipate a paradigmatic shift due to the emergence of promptable segmentation foundation models with universal segmentation capabilities using positional prompts represented by Segment Anything Model (SAM). In this paper, we present SemiSAM+, a foundation model-driven SSL framework to efficiently learn from limited labeled data for medical image segmentation. SemiSAM+ consists of one or multiple promptable foundation models as generalist models, and a trainable task-specific segmentation model as specialist model. For a given new segmentation task, the training is based on the specialist-generalist collaborative learning procedure, where the trainable specialist model delivers positional prompts to interact with the frozen generalist models to acquire pseudo-labels, and then the generalist model output provides the specialist model with informative and efficient supervision which benefits the automatic segmentation and prompt generation in turn. Extensive experiments on two public datasets and one in-house clinical dataset demonstrate that SemiSAM+ achieves significant performance improvement, especially under extremely limited annotation scenarios, and shows strong efficiency as a plug-and-play strategy that can be easily adapted to different specialist and generalist models.
SegAnyPET: Universal Promptable Segmentation from Positron Emission Tomography Images
Feb 20, 2025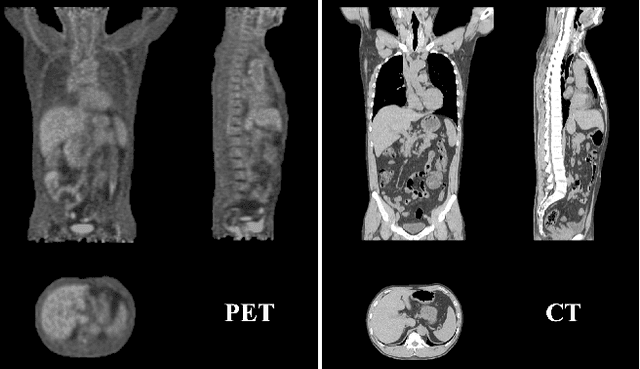
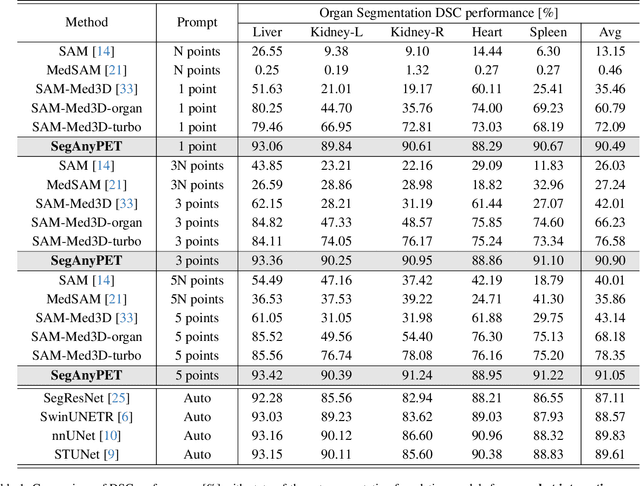
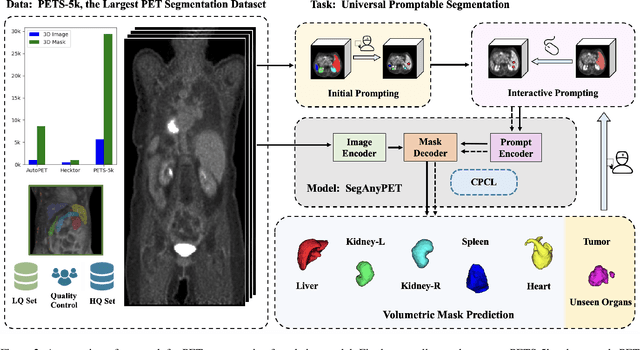
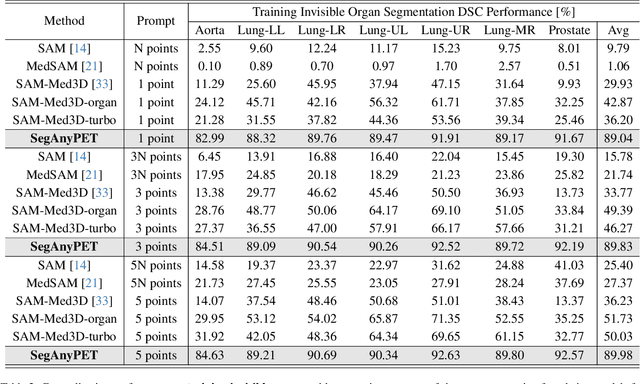
Positron Emission Tomography (PET) imaging plays a crucial role in modern medical diagnostics by revealing the metabolic processes within a patient's body, which is essential for quantification of therapy response and monitoring treatment progress. However, the segmentation of PET images presents unique challenges due to their lower contrast and less distinct boundaries compared to other structural medical modalities. Recent developments in segmentation foundation models have shown superior versatility across diverse natural image segmentation tasks. Despite the efforts of medical adaptations, these works primarily focus on structural medical images with detailed physiological structural information and exhibit poor generalization ability when adapted to molecular PET imaging. In this paper, we collect and construct PETS-5k, the largest PET segmentation dataset to date, comprising 5,731 three-dimensional whole-body PET images and encompassing over 1.3M 2D images. Based on the established dataset, we develop SegAnyPET, a modality-specific 3D foundation model for universal promptable segmentation from PET images. To issue the challenge of discrepant annotation quality of PET images, we adopt a cross prompting confident learning (CPCL) strategy with an uncertainty-guided self-rectification process to robustly learn segmentation from high-quality labeled data and low-quality noisy labeled data. Experimental results demonstrate that SegAnyPET can correctly segment seen and unseen targets using only one or a few prompt points, outperforming state-of-the-art foundation models and task-specific fully supervised models with higher accuracy and strong generalization ability for universal segmentation. As the first foundation model for PET images, we believe that SegAnyPET will advance the applications to various downstream tasks for molecular imaging.
ProVision: Programmatically Scaling Vision-centric Instruction Data for Multimodal Language Models
Dec 09, 2024
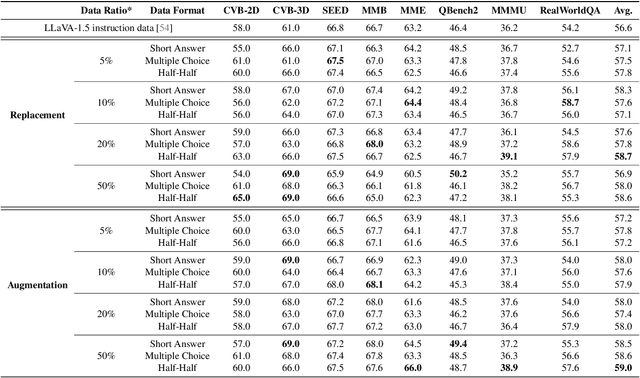
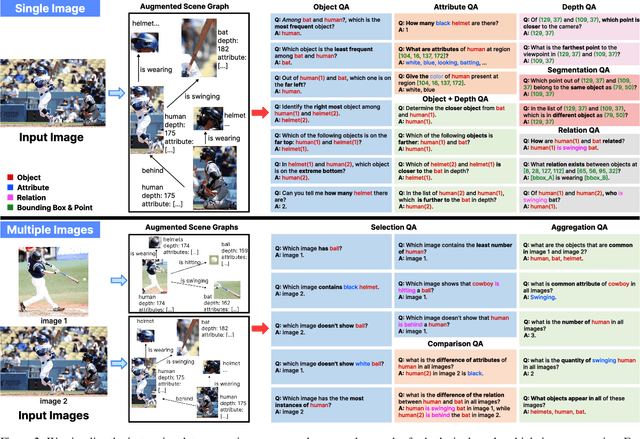
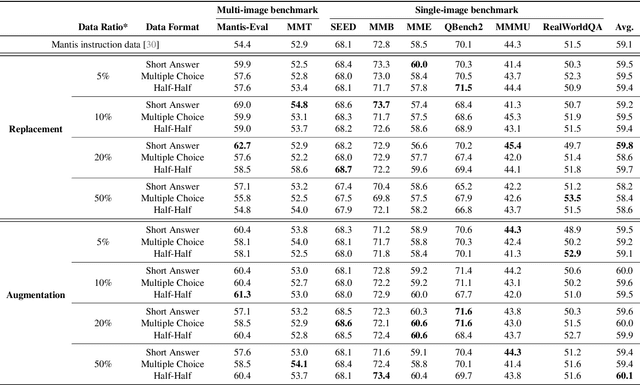
With the rise of multimodal applications, instruction data has become critical for training multimodal language models capable of understanding complex image-based queries. Existing practices rely on powerful but costly large language models (LLMs) or multimodal language models (MLMs) to produce instruction data. These are often prone to hallucinations, licensing issues and the generation process is often hard to scale and interpret. In this work, we present a programmatic approach that employs scene graphs as symbolic representations of images and human-written programs to systematically synthesize vision-centric instruction data. Our approach ensures the interpretability and controllability of the data generation process and scales efficiently while maintaining factual accuracy. By implementing a suite of 24 single-image, 14 multi-image instruction generators, and a scene graph generation pipeline, we build a scalable, cost-effective system: ProVision which produces diverse question-answer pairs concerning objects, attributes, relations, depth, etc., for any given image. Applied to Visual Genome and DataComp datasets, we generate over 10 million instruction data points, ProVision-10M, and leverage them in both pretraining and instruction tuning stages of MLMs. When adopted in the instruction tuning stage, our single-image instruction data yields up to a 7% improvement on the 2D split and 8% on the 3D split of CVBench, along with a 3% increase in performance on QBench2, RealWorldQA, and MMMU. Our multi-image instruction data leads to an 8% improvement on Mantis-Eval. Incorporation of our data in both pre-training and fine-tuning stages of xGen-MM-4B leads to an averaged improvement of 1.6% across 11 benchmarks.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024
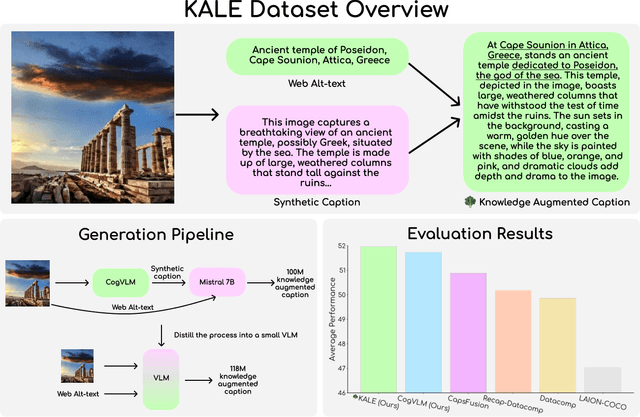
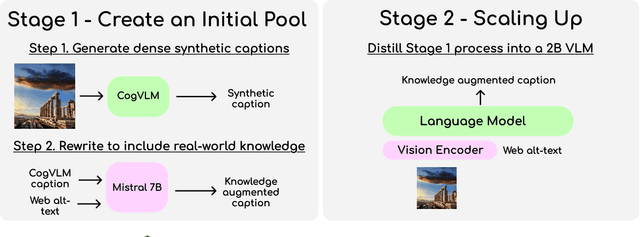

We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs
Oct 21, 2024



We present xGen-MM-Vid (BLIP-3-Video): a multimodal language model for videos, particularly designed to efficiently capture temporal information over multiple frames. BLIP-3-Video takes advantage of the 'temporal encoder' in addition to the conventional visual tokenizer, which maps a sequence of tokens over multiple frames into a compact set of visual tokens. This enables BLIP3-Video to use much fewer visual tokens than its competing models (e.g., 32 vs. 4608 tokens). We explore different types of temporal encoders, including learnable spatio-temporal pooling as well as sequential models like Token Turing Machines. We experimentally confirm that BLIP-3-Video obtains video question-answering accuracies comparable to much larger state-of-the-art models (e.g., 34B), while being much smaller (i.e., 4B) and more efficient by using fewer visual tokens. The project website is at https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html