 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024
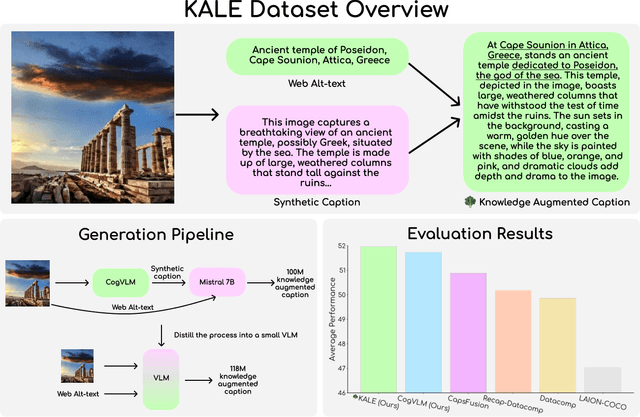
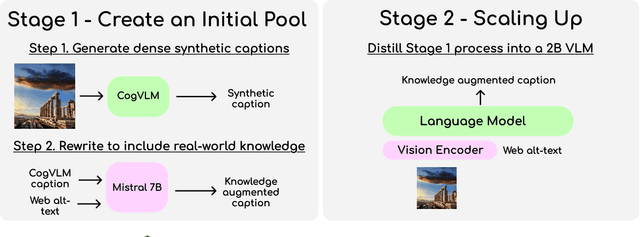

We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Jun 17, 2024



Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.