 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
Apr 23, 2025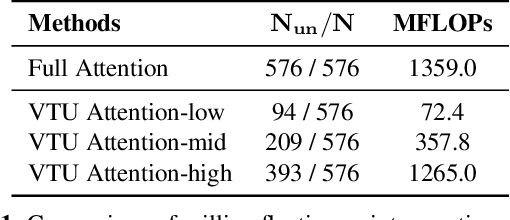
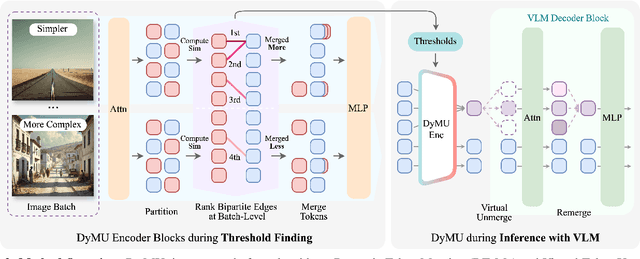
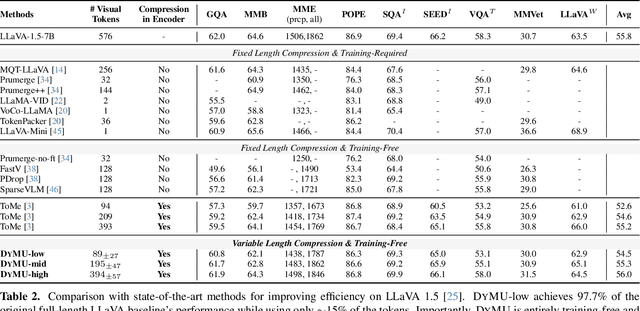
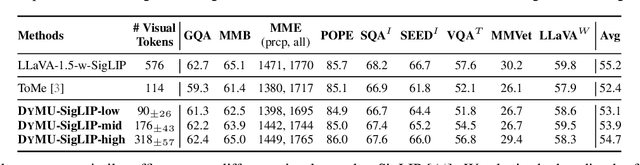
We present DyMU, an efficient, training-free framework that dynamically reduces the computational burden of vision-language models (VLMs) while maintaining high task performance. Our approach comprises two key components. First, Dynamic Token Merging (DToMe) reduces the number of visual token embeddings by merging similar tokens based on image complexity, addressing the inherent inefficiency of fixed-length outputs in vision transformers. Second, Virtual Token Unmerging (VTU) simulates the expected token sequence for large language models (LLMs) by efficiently reconstructing the attention dynamics of a full sequence, thus preserving the downstream performance without additional fine-tuning. Unlike previous approaches, our method dynamically adapts token compression to the content of the image and operates completely training-free, making it readily applicable to most state-of-the-art VLM architectures. Extensive experiments on image and video understanding tasks demonstrate that DyMU can reduce the average visual token count by 32%-85% while achieving comparable performance to full-length models across diverse VLM architectures, including the recently popularized AnyRes-based visual encoders. Furthermore, through qualitative analyses, we demonstrate that DToMe effectively adapts token reduction based on image complexity and, unlike existing systems, provides users more control over computational costs. Project page: https://mikewangwzhl.github.io/dymu/.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024
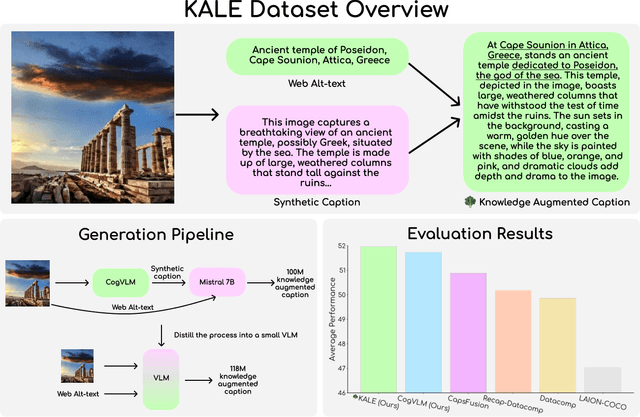
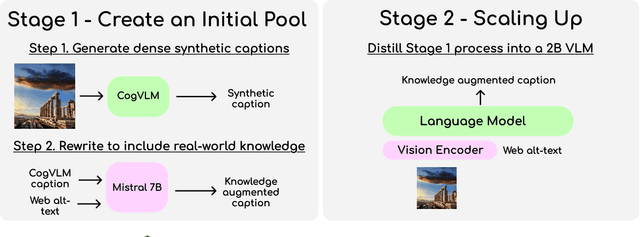

We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
Trust but Verify: Programmatic VLM Evaluation in the Wild
Oct 17, 2024
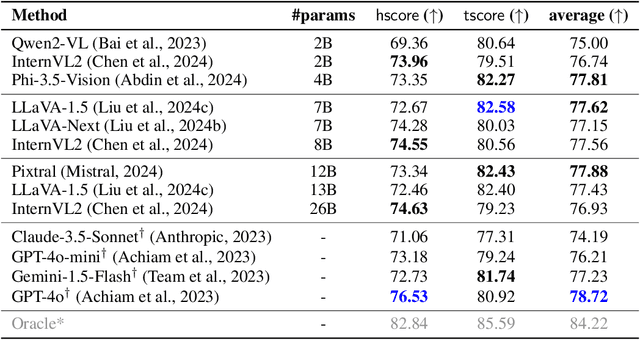

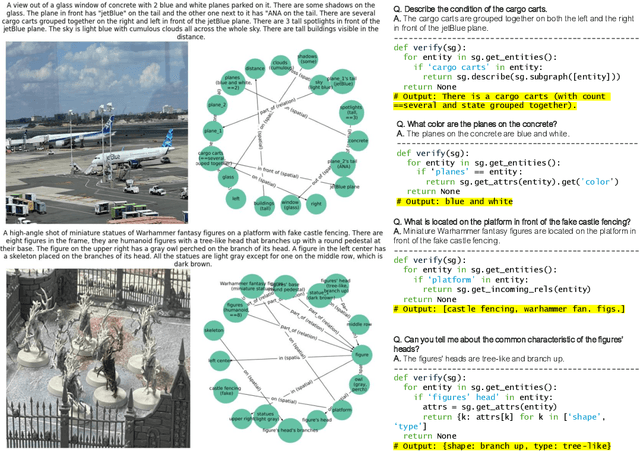
Vision-Language Models (VLMs) often generate plausible but incorrect responses to visual queries. However, reliably quantifying the effect of such hallucinations in free-form responses to open-ended queries is challenging as it requires visually verifying each claim within the response. We propose Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm for evaluating VLM responses to open-ended queries. To construct PROVE, we provide a large language model (LLM) with a high-fidelity scene-graph representation constructed from a hyper-detailed image caption, and prompt it to generate diverse question-answer (QA) pairs, as well as programs that can be executed over the scene graph object to verify each QA pair. We thus construct a benchmark of 10.5k challenging but visually grounded QA pairs. Next, to evaluate free-form model responses to queries in PROVE, we propose a programmatic evaluation strategy that measures both the helpfulness and truthfulness of a response within a unified scene graph-based framework. We benchmark the helpfulness-truthfulness trade-offs of a range of VLMs on PROVE, finding that very few are in-fact able to achieve a good balance between the two. Project page: \url{https://prove-explorer.netlify.app/}.
SFR-RAG: Towards Contextually Faithful LLMs
Sep 16, 2024Retrieval Augmented Generation (RAG), a paradigm that integrates external contextual information with large language models (LLMs) to enhance factual accuracy and relevance, has emerged as a pivotal area in generative AI. The LLMs used in RAG applications are required to faithfully and completely comprehend the provided context and users' questions, avoid hallucination, handle unanswerable, counterfactual or otherwise low-quality and irrelevant contexts, perform complex multi-hop reasoning and produce reliable citations. In this paper, we introduce SFR-RAG, a small LLM that is instruction-tuned with an emphasis on context-grounded generation and hallucination minimization. We also present ContextualBench, a new evaluation framework compiling multiple popular and diverse RAG benchmarks, such as HotpotQA and TriviaQA, with consistent RAG settings to ensure reproducibility and consistency in model assessments. Experimental results demonstrate that our SFR-RAG-9B model outperforms leading baselines such as Command-R+ (104B) and GPT-4o, achieving state-of-the-art results in 3 out of 7 benchmarks in ContextualBench with significantly fewer parameters. The model is also shown to be resilient to alteration in the contextual information and behave appropriately when relevant context is removed. Additionally, the SFR-RAG model maintains competitive performance in general instruction-following tasks and function-calling capabilities.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
BootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models
Jan 25, 2024



Recent text-to-image generation models have demonstrated incredible success in generating images that faithfully follow input prompts. However, the requirement of using words to describe a desired concept provides limited control over the appearance of the generated concepts. In this work, we address this shortcoming by proposing an approach to enable personalization capabilities in existing text-to-image diffusion models. We propose a novel architecture (BootPIG) that allows a user to provide reference images of an object in order to guide the appearance of a concept in the generated images. The proposed BootPIG architecture makes minimal modifications to a pretrained text-to-image diffusion model and utilizes a separate UNet model to steer the generations toward the desired appearance. We introduce a training procedure that allows us to bootstrap personalization capabilities in the BootPIG architecture using data generated from pretrained text-to-image models, LLM chat agents, and image segmentation models. In contrast to existing methods that require several days of pretraining, the BootPIG architecture can be trained in approximately 1 hour. Experiments on the DreamBooth dataset demonstrate that BootPIG outperforms existing zero-shot methods while being comparable with test-time finetuning approaches. Through a user study, we validate the preference for BootPIG generations over existing methods both in maintaining fidelity to the reference object's appearance and aligning with textual prompts.
Diffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023



Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
ConRad: Image Constrained Radiance Fields for 3D Generation from a Single Image
Nov 09, 2023We present a novel method for reconstructing 3D objects from a single RGB image. Our method leverages the latest image generation models to infer the hidden 3D structure while remaining faithful to the input image. While existing methods obtain impressive results in generating 3D models from text prompts, they do not provide an easy approach for conditioning on input RGB data. Na\"ive extensions of these methods often lead to improper alignment in appearance between the input image and the 3D reconstructions. We address these challenges by introducing Image Constrained Radiance Fields (ConRad), a novel variant of neural radiance fields. ConRad is an efficient 3D representation that explicitly captures the appearance of an input image in one viewpoint. We propose a training algorithm that leverages the single RGB image in conjunction with pretrained Diffusion Models to optimize the parameters of a ConRad representation. Extensive experiments show that ConRad representations can simplify preservation of image details while producing a realistic 3D reconstruction. Compared to existing state-of-the-art baselines, we show that our 3D reconstructions remain more faithful to the input and produce more consistent 3D models while demonstrating significantly improved quantitative performance on a ShapeNet object benchmark.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.