 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
VLM Q-Learning: Aligning Vision-Language Models for Interactive Decision-Making
May 06, 2025Recent research looks to harness the general knowledge and reasoning of large language models (LLMs) into agents that accomplish user-specified goals in interactive environments. Vision-language models (VLMs) extend LLMs to multi-modal data and provide agents with the visual reasoning necessary for new applications in areas such as computer automation. However, agent tasks emphasize skills where accessible open-weight VLMs lag behind their LLM equivalents. For example, VLMs are less capable of following an environment's strict output syntax requirements and are more focused on open-ended question answering. Overcoming these limitations requires supervised fine-tuning (SFT) on task-specific expert demonstrations. Our work approaches these challenges from an offline-to-online reinforcement learning (RL) perspective. RL lets us fine-tune VLMs to agent tasks while learning from the unsuccessful decisions of our own model or more capable (larger) models. We explore an off-policy RL solution that retains the stability and simplicity of the widely used SFT workflow while allowing our agent to self-improve and learn from low-quality datasets. We demonstrate this technique with two open-weight VLMs across three multi-modal agent domains.
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
Instance-Aware Generalized Referring Expression Segmentation
Nov 22, 2024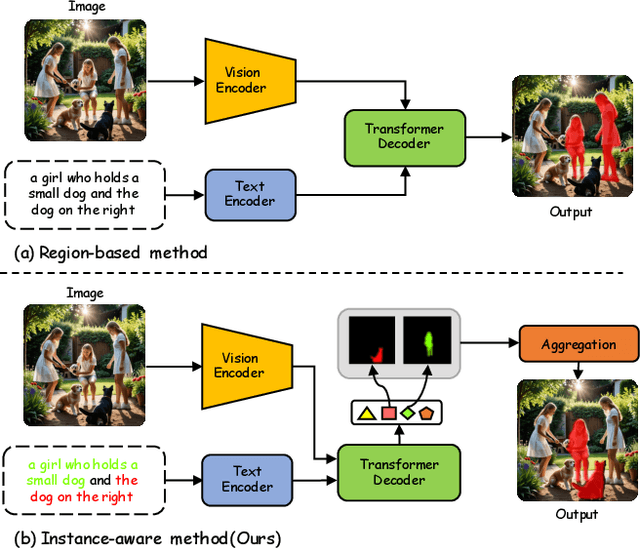
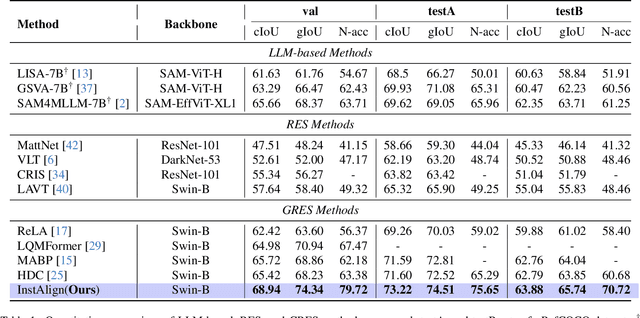
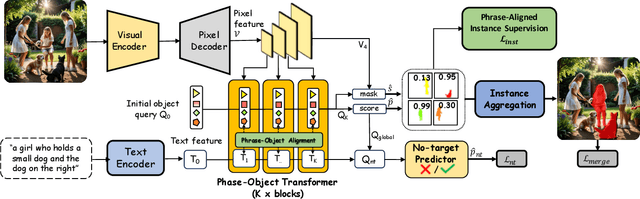
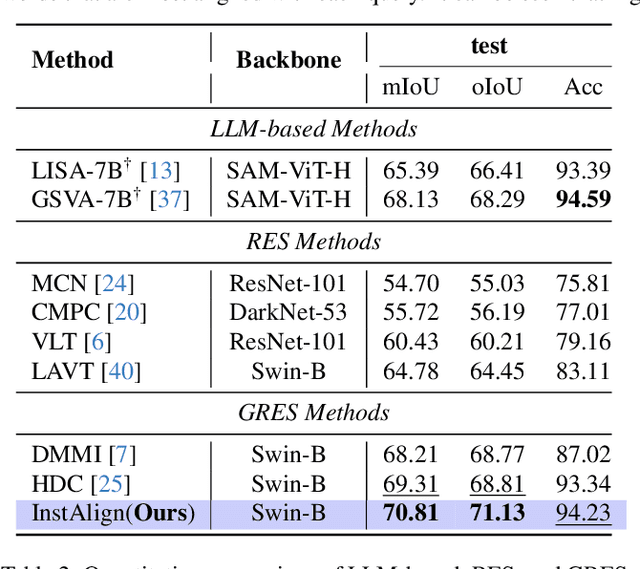
Recent works on Generalized Referring Expression Segmentation (GRES) struggle with handling complex expressions referring to multiple distinct objects. This is because these methods typically employ an end-to-end foreground-background segmentation and lack a mechanism to explicitly differentiate and associate different object instances to the text query. To this end, we propose InstAlign, a method that incorporates object-level reasoning into the segmentation process. Our model leverages both text and image inputs to extract a set of object-level tokens that capture both the semantic information in the input prompt and the objects within the image. By modeling the text-object alignment via instance-level supervision, each token uniquely represents an object segment in the image, while also aligning with relevant semantic information from the text. Extensive experiments on the gRefCOCO and Ref-ZOM benchmarks demonstrate that our method significantly advances state-of-the-art performance, setting a new standard for precise and flexible GRES.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention
Dec 04, 2023



We present Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT): a new paradigm for addressing the emerging challenge of scaling up Robotics Transformers (RT) for on-robot deployment. SARA-RT relies on the new method of fine-tuning proposed by us, called up-training. It converts pre-trained or already fine-tuned Transformer-based robotic policies of quadratic time complexity (including massive billion-parameter vision-language-action models or VLAs), into their efficient linear-attention counterparts maintaining high quality. We demonstrate the effectiveness of SARA-RT by speeding up: (a) the class of recently introduced RT-2 models, the first VLA robotic policies pre-trained on internet-scale data, as well as (b) Point Cloud Transformer (PCT) robotic policies operating on large point clouds. We complement our results with the rigorous mathematical analysis providing deeper insight into the phenomenon of SARA.
Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
Oct 31, 2023



Vision Transformers (ViTs) have become ubiquitous in computer vision. Despite their success, ViTs lack inductive biases, which can make it difficult to train them with limited data. To address this challenge, prior studies suggest training ViTs with self-supervised learning (SSL) and fine-tuning sequentially. However, we observe that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task (SSAT) is surprisingly beneficial when the amount of training data is limited. We explore the appropriate SSL tasks that can be optimized alongside the primary task, the training schemes for these tasks, and the data scale at which they can be most effective. Our findings reveal that SSAT is a powerful technique that enables ViTs to leverage the unique characteristics of both the self-supervised and primary tasks, achieving better performance than typical ViTs pre-training with SSL and fine-tuning sequentially. Our experiments, conducted on 10 datasets, demonstrate that SSAT significantly improves ViT performance while reducing carbon footprint. We also confirm the effectiveness of SSAT in the video domain for deepfake detection, showcasing its generalizability. Our code is available at https://github.com/dominickrei/Limited-data-vits.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Language-based Action Concept Spaces Improve Video Self-Supervised Learning
Jul 20, 2023Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io