 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
Infinite-Resolution Integral Noise Warping for Diffusion Models
Nov 02, 2024Adapting pretrained image-based diffusion models to generate temporally consistent videos has become an impactful generative modeling research direction. Training-free noise-space manipulation has proven to be an effective technique, where the challenge is to preserve the Gaussian white noise distribution while adding in temporal consistency. Recently, Chang et al. (2024) formulated this problem using an integral noise representation with distribution-preserving guarantees, and proposed an upsampling-based algorithm to compute it. However, while their mathematical formulation is advantageous, the algorithm incurs a high computational cost. Through analyzing the limiting-case behavior of their algorithm as the upsampling resolution goes to infinity, we develop an alternative algorithm that, by gathering increments of multiple Brownian bridges, achieves their infinite-resolution accuracy while simultaneously reducing the computational cost by orders of magnitude. We prove and experimentally validate our theoretical claims, and demonstrate our method's effectiveness in real-world applications. We further show that our method readily extends to the 3-dimensional space.
Fluid Simulation on Neural Flow Maps
Dec 22, 2023We introduce Neural Flow Maps, a novel simulation method bridging the emerging paradigm of implicit neural representations with fluid simulation based on the theory of flow maps, to achieve state-of-the-art simulation of inviscid fluid phenomena. We devise a novel hybrid neural field representation, Spatially Sparse Neural Fields (SSNF), which fuses small neural networks with a pyramid of overlapping, multi-resolution, and spatially sparse grids, to compactly represent long-term spatiotemporal velocity fields at high accuracy. With this neural velocity buffer in hand, we compute long-term, bidirectional flow maps and their Jacobians in a mechanistically symmetric manner, to facilitate drastic accuracy improvement over existing solutions. These long-range, bidirectional flow maps enable high advection accuracy with low dissipation, which in turn facilitates high-fidelity incompressible flow simulations that manifest intricate vortical structures. We demonstrate the efficacy of our neural fluid simulation in a variety of challenging simulation scenarios, including leapfrogging vortices, colliding vortices, vortex reconnections, as well as vortex generation from moving obstacles and density differences. Our examples show increased performance over existing methods in terms of energy conservation, visual complexity, adherence to experimental observations, and preservation of detailed vortical structures.
Inferring Hybrid Neural Fluid Fields from Videos
Dec 11, 2023We study recovering fluid density and velocity from sparse multiview videos. Existing neural dynamic reconstruction methods predominantly rely on optical flows; therefore, they cannot accurately estimate the density and uncover the underlying velocity due to the inherent visual ambiguities of fluid velocity, as fluids are often shapeless and lack stable visual features. The challenge is further pronounced by the turbulent nature of fluid flows, which calls for properly designed fluid velocity representations. To address these challenges, we propose hybrid neural fluid fields (HyFluid), a neural approach to jointly infer fluid density and velocity fields. Specifically, to deal with visual ambiguities of fluid velocity, we introduce a set of physics-based losses that enforce inferring a physically plausible velocity field, which is divergence-free and drives the transport of density. To deal with the turbulent nature of fluid velocity, we design a hybrid neural velocity representation that includes a base neural velocity field that captures most irrotational energy and a vortex particle-based velocity that models residual turbulent velocity. We show that our method enables recovering vortical flow details. Our approach opens up possibilities for various learning and reconstruction applications centered around 3D incompressible flow, including fluid re-simulation and editing, future prediction, and neural dynamic scene composition. Project website: https://kovenyu.com/HyFluid/
Learning Vortex Dynamics for Fluid Inference and Prediction
Feb 01, 2023We propose a novel differentiable vortex particle (DVP) method to infer and predict fluid dynamics from a single video. Lying at its core is a particle-based latent space to encapsulate the hidden, Lagrangian vortical evolution underpinning the observable, Eulerian flow phenomena. Our differentiable vortex particles are coupled with a learnable, vortex-to-velocity dynamics mapping to effectively capture the complex flow features in a physically-constrained, low-dimensional space. This representation facilitates the learning of a fluid simulator tailored to the input video that can deliver robust, long-term future predictions. The value of our method is twofold: first, our learned simulator enables the inference of hidden physics quantities (e.g., velocity field) purely from visual observation; secondly, it also supports future prediction, constructing the input video's sequel along with its future dynamics evolution. We compare our method with a range of existing methods on both synthetic and real-world videos, demonstrating improved reconstruction quality, visual plausibility, and physical integrity.
Soft Multicopter Control using Neural Dynamics Identification
Sep 02, 2020
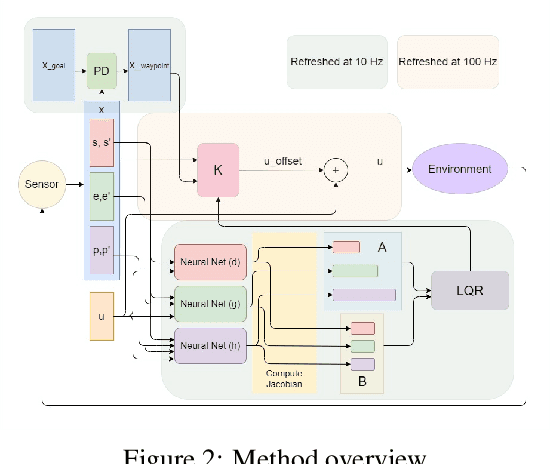
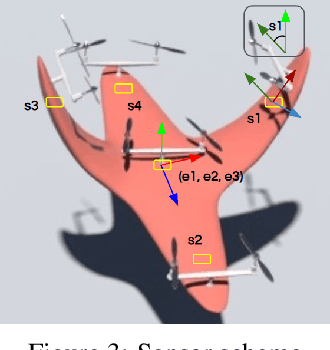
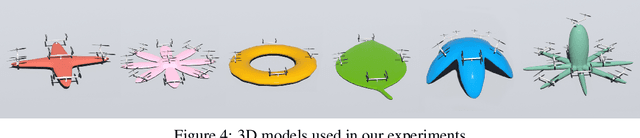
Dynamic control of a soft-body robot to deliver complex behaviors with low-dimensional actuation inputs is challenging. In this paper, we present a computational approach to automatically generate versatile, underactuated control policies that drives soft-bodied machines with complicated structures and nonlinear dynamics. Our target application is focused on the autonomous control of a soft multicopter, featured by its elastic material components, non-conventional shapes, and asymmetric rotor layouts, to precisely deliver compliant deformation and agile locomotion. The central piece of our approach lies in a lightweight neural surrogate model to identify and predict the temporal evolution of a set of geometric variables characterizing an elastic soft body. This physics-based learning model is further integrated into a Linear Quadratic Regulator (LQR) control loop enhanced by a novel online fixed-point relinearization scheme to accommodate the dynamic body balance, allowing an aggressive reduction of the computational overhead caused by the conventional full-scale sensing-simulation-control workflow. We demonstrate the efficacy of our approach by generating controllers for a broad spectrum of customized soft multicopter designs and testing them in a high-fidelity physics simulation environment. The control algorithm enables the multicopters to perform a variety of tasks, including hovering, trajectory tracking, cruising and active deforming.