 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffHDR: Re-Exposing LDR Videos with Video Diffusion Models
Apr 07, 2026Most digital videos are stored in 8-bit low dynamic range (LDR) formats, where much of the original high dynamic range (HDR) scene radiance is lost due to saturation and quantization. This loss of highlight and shadow detail precludes mapping accurate luminance to HDR displays and limits meaningful re-exposure in post-production workflows. Although techniques have been proposed to convert LDR images to HDR through dynamic range expansion, they struggle to restore realistic detail in the over- and underexposed regions. To address this, we present DiffHDR, a framework that formulates LDR-to-HDR conversion as a generative radiance inpainting task within the latent space of a video diffusion model. By operating in Log-Gamma color space, DiffHDR leverages spatio-temporal generative priors from a pretrained video diffusion model to synthesize plausible HDR radiance in over- and underexposed regions while recovering the continuous scene radiance of the quantized pixels. Our framework further enables controllable LDR-to-HDR video conversion guided by text prompts or reference images. To address the scarcity of paired HDR video data, we develop a pipeline that synthesizes high-quality HDR video training data from static HDRI maps. Extensive experiments demonstrate that DiffHDR significantly outperforms state-of-the-art approaches in radiance fidelity and temporal stability, producing realistic HDR videos with considerable latitude for re-exposure.
Infinite-Resolution Integral Noise Warping for Diffusion Models
Nov 02, 2024Adapting pretrained image-based diffusion models to generate temporally consistent videos has become an impactful generative modeling research direction. Training-free noise-space manipulation has proven to be an effective technique, where the challenge is to preserve the Gaussian white noise distribution while adding in temporal consistency. Recently, Chang et al. (2024) formulated this problem using an integral noise representation with distribution-preserving guarantees, and proposed an upsampling-based algorithm to compute it. However, while their mathematical formulation is advantageous, the algorithm incurs a high computational cost. Through analyzing the limiting-case behavior of their algorithm as the upsampling resolution goes to infinity, we develop an alternative algorithm that, by gathering increments of multiple Brownian bridges, achieves their infinite-resolution accuracy while simultaneously reducing the computational cost by orders of magnitude. We prove and experimentally validate our theoretical claims, and demonstrate our method's effectiveness in real-world applications. We further show that our method readily extends to the 3-dimensional space.
Wassersplines for Stylized Neural Animation
Jan 28, 2022
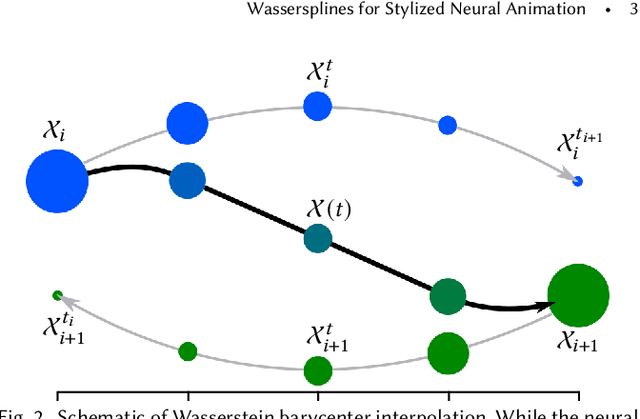
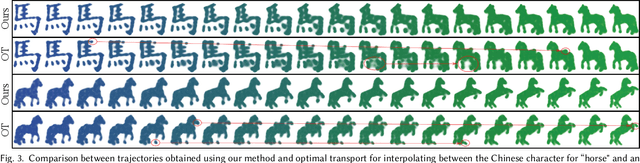
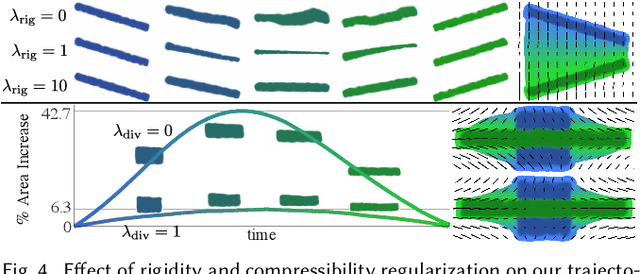
Much of computer-generated animation is created by manipulating meshes with rigs. While this approach works well for animating articulated objects like animals, it has limited flexibility for animating less structured creatures such as the Drunn in "Raya and the Last Dragon." We introduce Wassersplines, a novel trajectory inference method for animating unstructured densities based on recent advances in continuous normalizing flows and optimal transport. The key idea is to train a neurally-parameterized velocity field that represents the motion between keyframes. Trajectories are then computed by pushing keyframes through the velocity field. We solve an additional Wasserstein barycenter interpolation problem to guarantee strict adherence to keyframes. Our tool can stylize trajectories through a variety of PDE-based regularizers to create different visual effects. We demonstrate our tool on various keyframe interpolation problems to produce temporally-coherent animations without meshing or rigging.
DeepCurrents: Learning Implicit Representations of Shapes with Boundaries
Nov 17, 2021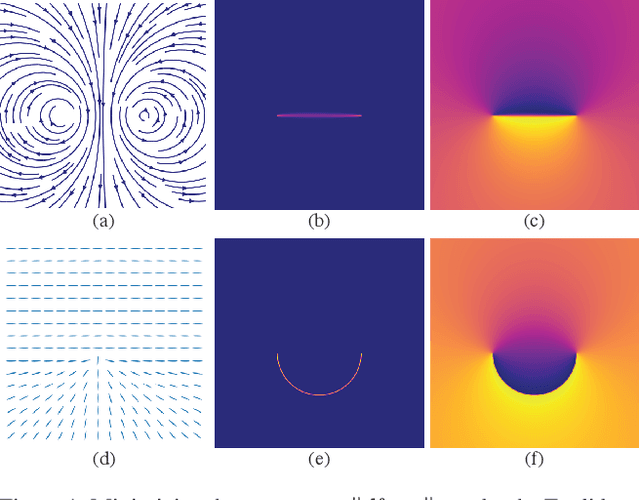
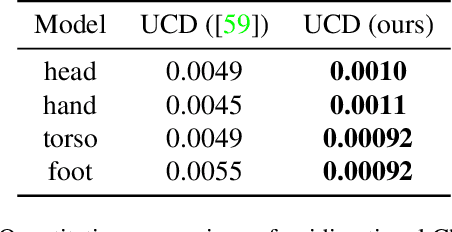
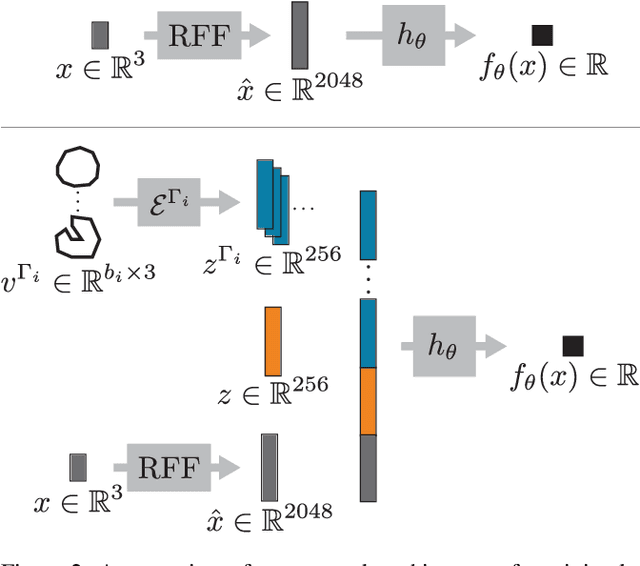
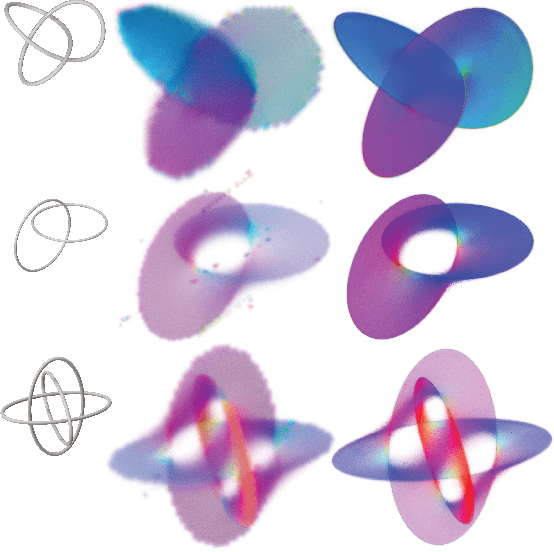
Recent techniques have been successful in reconstructing surfaces as level sets of learned functions (such as signed distance fields) parameterized by deep neural networks. Many of these methods, however, learn only closed surfaces and are unable to reconstruct shapes with boundary curves. We propose a hybrid shape representation that combines explicit boundary curves with implicit learned interiors. Using machinery from geometric measure theory, we parameterize currents using deep networks and use stochastic gradient descent to solve a minimal surface problem. By modifying the metric according to target geometry coming, e.g., from a mesh or point cloud, we can use this approach to represent arbitrary surfaces, learning implicitly defined shapes with explicitly defined boundary curves. We further demonstrate learning families of shapes jointly parameterized by boundary curves and latent codes.
MarioNette: Self-Supervised Sprite Learning
Apr 29, 2021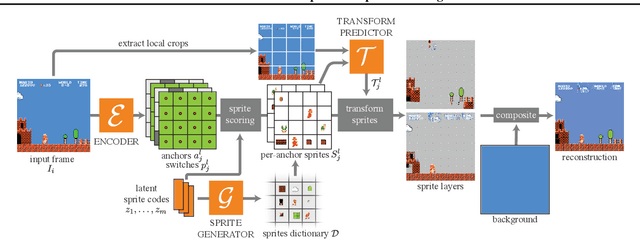
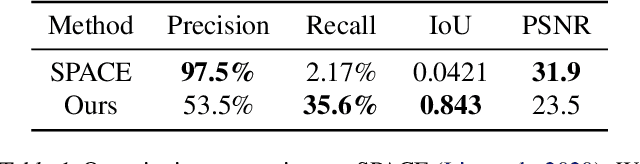
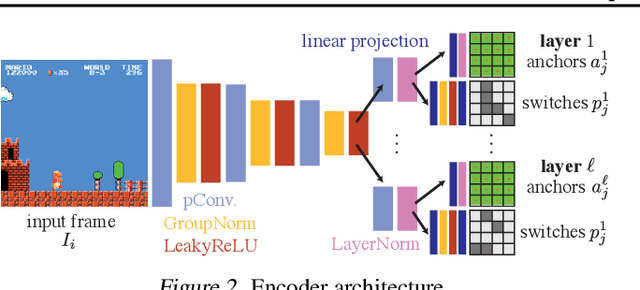
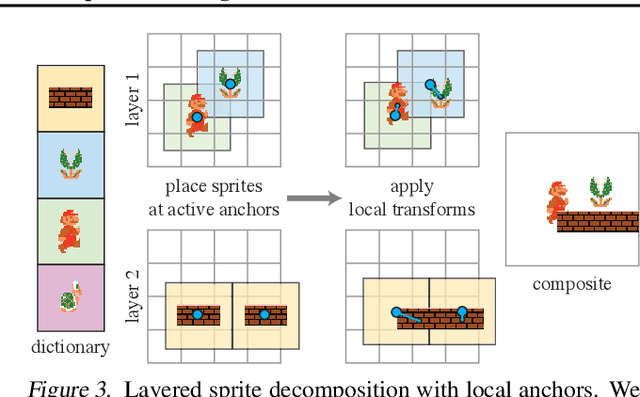
Visual content often contains recurring elements. Text is made up of glyphs from the same font, animations, such as cartoons or video games, are composed of sprites moving around the screen, and natural videos frequently have repeated views of objects. In this paper, we propose a deep learning approach for obtaining a graphically disentangled representation of recurring elements in a completely self-supervised manner. By jointly learning a dictionary of texture patches and training a network that places them onto a canvas, we effectively deconstruct sprite-based content into a sparse, consistent, and interpretable representation that can be easily used in downstream tasks. Our framework offers a promising approach for discovering recurring patterns in image collections without supervision.
Polygonal Building Segmentation by Frame Field Learning
Apr 30, 2020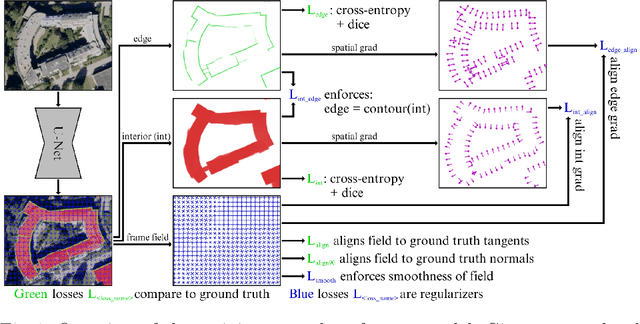
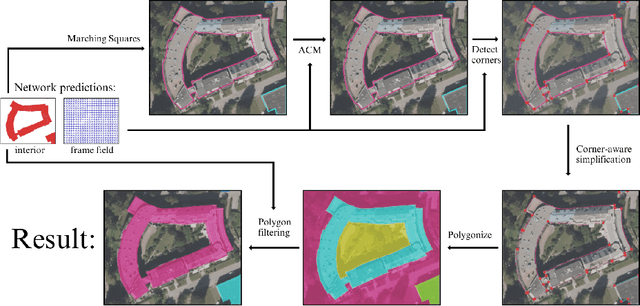

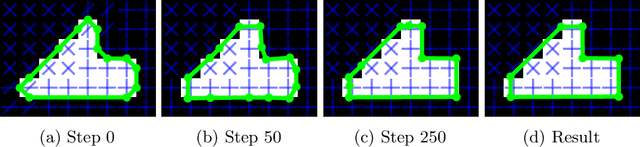
While state of the art image segmentation models typically output segmentations in raster format, applications in geographic information systems often require vector polygons. We propose adding a frame field output to a deep image segmentation model for extracting buildings from remote sensing images. This improves segmentation quality and provides structural information, facilitating more accurate polygonization. To this end, we train a deep neural network, which aligns a predicted frame field to ground truth contour data. In addition to increasing performance by leveraging multi-task learning, our method produces more regular segmentations. We also introduce a new polygonization algorithm, which is guided by the frame field corresponding to the raster segmentation.
Deep Parametric Shape Predictions using Distance Fields
Apr 18, 2019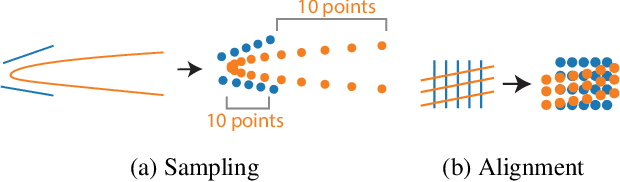



Many tasks in graphics and vision demand machinery for converting shapes into representations with sparse sets of parameters; these representations facilitate rendering, editing, and storage. When the source data is noisy or ambiguous, however, artists and engineers often manually construct such representations, a tedious and potentially time-consuming process. While advances in deep learning have been successfully applied to noisy geometric data, the task of generating parametric shapes has so far been difficult for these methods. Hence, we propose a new framework for predicting parametric shape primitives using deep learning. We use distance fields to transition between shape parameters like control points and input data on a raster grid. We demonstrate efficacy on 2D and 3D tasks, including font vectorization and surface abstraction.