 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrightearth roads: Towards fully automatic road network extraction from satellite imagery
Jun 21, 2024



The modern road network topology comprises intricately designed structures that introduce complexity when automatically reconstructing road networks. While open resources like OpenStreetMap (OSM) offer road networks with well-defined topology, they may not always be up to date worldwide. In this paper, we propose a fully automated pipeline for extracting road networks from very-high-resolution (VHR) satellite imagery. Our approach directly generates road line-strings that are seamlessly connected and precisely positioned. The process involves three key modules: a CNN-based neural network for road segmentation, a graph optimization algorithm to convert road predictions into vector line-strings, and a machine learning model for classifying road materials. Compared to OSM data, our results demonstrate significant potential for providing the latest road layouts and precise positions of road segments.
3D detection of roof sections from a single satellite image and application to LOD2-building reconstruction
Jul 11, 2023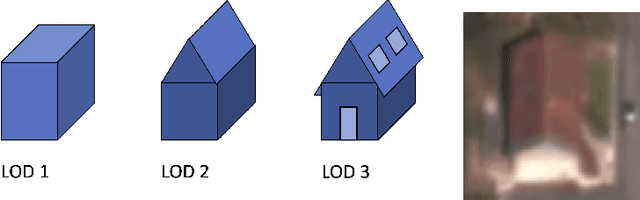
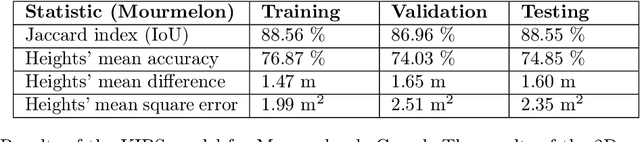
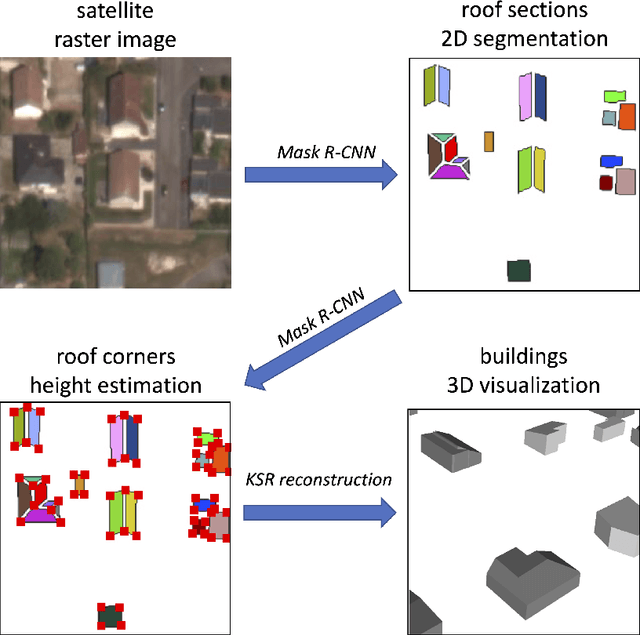

Reconstructing urban areas in 3D out of satellite raster images has been a long-standing and challenging goal of both academical and industrial research. The rare methods today achieving this objective at a Level Of Details $2$ rely on procedural approaches based on geometry, and need stereo images and/or LIDAR data as input. We here propose a method for urban 3D reconstruction named KIBS(\textit{Keypoints Inference By Segmentation}), which comprises two novel features: i) a full deep learning approach for the 3D detection of the roof sections, and ii) only one single (non-orthogonal) satellite raster image as model input. This is achieved in two steps: i) by a Mask R-CNN model performing a 2D segmentation of the buildings' roof sections, and after blending these latter segmented pixels within the RGB satellite raster image, ii) by another identical Mask R-CNN model inferring the heights-to-ground of the roof sections' corners via panoptic segmentation, unto full 3D reconstruction of the buildings and city. We demonstrate the potential of the KIBS method by reconstructing different urban areas in a few minutes, with a Jaccard index for the 2D segmentation of individual roof sections of $88.55\%$ and $75.21\%$ on our two data sets resp., and a height's mean error of such correctly segmented pixels for the 3D reconstruction of $1.60$ m and $2.06$ m on our two data sets resp., hence within the LOD2 precision range.
Input Similarity from the Neural Network Perspective
Feb 10, 2021

We first exhibit a multimodal image registration task, for which a neural network trained on a dataset with noisy labels reaches almost perfect accuracy, far beyond noise variance. This surprising auto-denoising phenomenon can be explained as a noise averaging effect over the labels of similar input examples. This effect theoretically grows with the number of similar examples; the question is then to define and estimate the similarity of examples. We express a proper definition of similarity, from the neural network perspective, i.e. we quantify how undissociable two inputs $A$ and $B$ are, taking a machine learning viewpoint: how much a parameter variation designed to change the output for $A$ would impact the output for $B$ as well? We study the mathematical properties of this similarity measure, and show how to use it on a trained network to estimate sample density, in low complexity, enabling new types of statistical analysis for neural networks. We analyze data by retrieving samples perceived as similar by the network, and are able to quantify the denoising effect without requiring true labels. We also propose, during training, to enforce that examples known to be similar should also be seen as similar by the network, and notice speed-up training effects for certain datasets.
Deep Neural Networks for automatic extraction of features in time series satellite images
Aug 17, 2020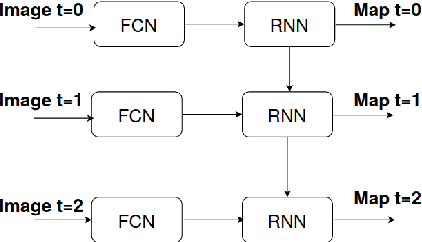


Many earth observation programs such as Landsat, Sentinel, SPOT, and Pleiades produce huge volume of medium to high resolution multi-spectral images every day that can be organized in time series. In this work, we exploit both temporal and spatial information provided by these images to generate land cover maps. For this purpose, we combine a fully convolutional neural network with a convolutional long short-term memory. Implementation details of the proposed spatio-temporal neural network architecture are provided. Experimental results show that the temporal information provided by time series images allows increasing the accuracy of land cover classification, thus producing up-to-date maps that can help in identifying changes on earth.
DAugNet: Unsupervised, Multi-source, Multi-target, and Life-long Domain Adaptation for Semantic Segmentation of Satellite Images
Jun 07, 2020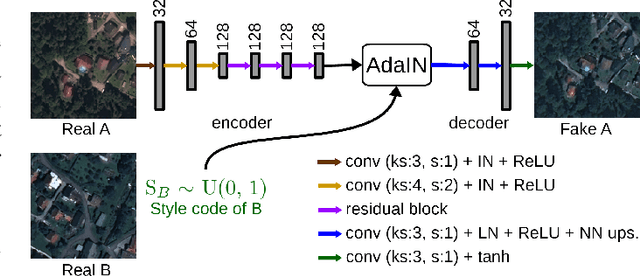
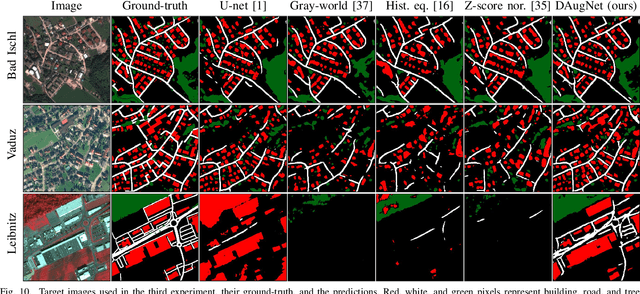

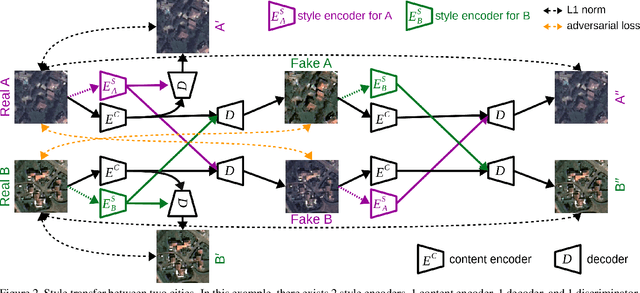
The domain adaptation of satellite images has recently gained an increasing attention to overcome the limited generalization abilities of machine learning models when segmenting large-scale satellite images. Most of the existing approaches seek for adapting the model from one domain to another. However, such single-source and single-target setting prevents the methods from being scalable solutions, since nowadays multiple source and target domains having different data distributions are usually available. Besides, the continuous proliferation of satellite images necessitates the classifiers to adapt to continuously increasing data. We propose a novel approach, coined DAugNet, for unsupervised, multi-source, multi-target, and life-long domain adaptation of satellite images. It consists of a classifier and a data augmentor. The data augmentor, which is a shallow network, is able to perform style transfer between multiple satellite images in an unsupervised manner, even when new data are added over the time. In each training iteration, it provides the classifier with diversified data, which makes the classifier robust to large data distribution difference between the domains. Our extensive experiments prove that DAugNet significantly better generalizes to new geographic locations than the existing approaches.
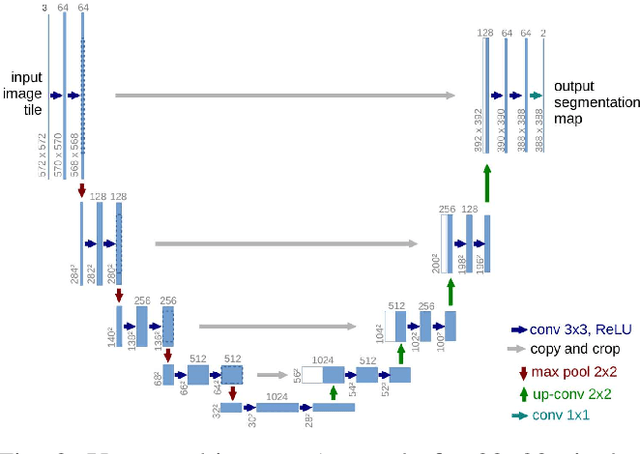
Polygonal Building Segmentation by Frame Field Learning
Apr 30, 2020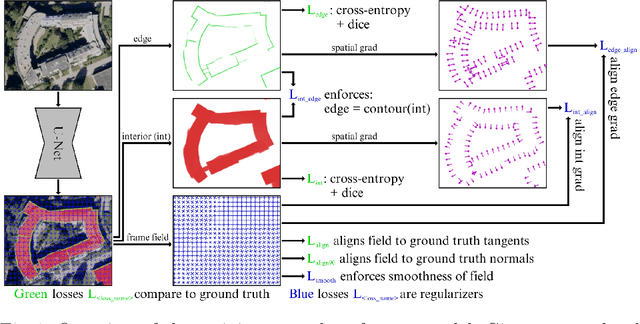
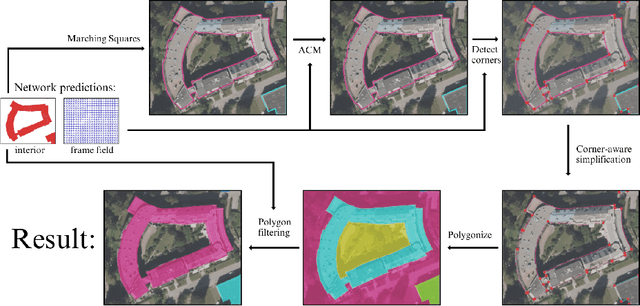

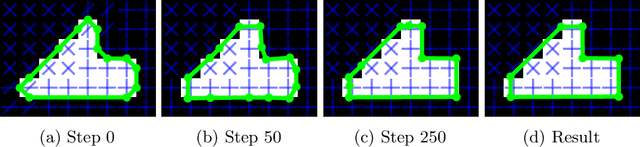
While state of the art image segmentation models typically output segmentations in raster format, applications in geographic information systems often require vector polygons. We propose adding a frame field output to a deep image segmentation model for extracting buildings from remote sensing images. This improves segmentation quality and provides structural information, facilitating more accurate polygonization. To this end, we train a deep neural network, which aligns a predicted frame field to ground truth contour data. In addition to increasing performance by leveraging multi-task learning, our method produces more regular segmentations. We also introduce a new polygonization algorithm, which is guided by the frame field corresponding to the raster segmentation.
StandardGAN: Multi-source Domain Adaptation for Semantic Segmentation of Very High Resolution Satellite Images by Data Standardization
Apr 14, 2020
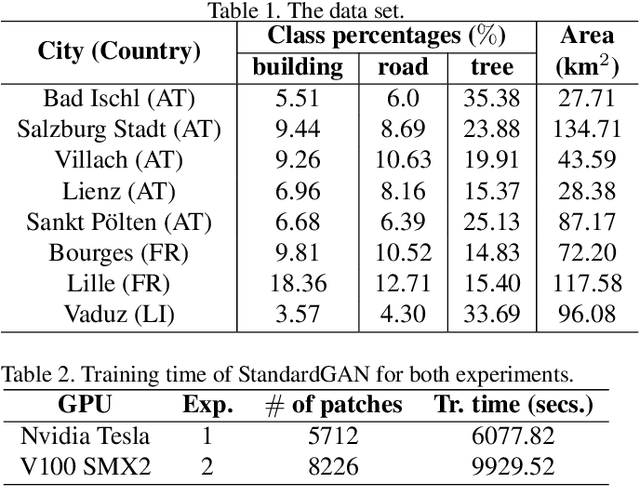
Domain adaptation for semantic segmentation has recently been actively studied to increase the generalization capabilities of deep learning models. The vast majority of the domain adaptation methods tackle single-source case, where the model trained on a single source domain is adapted to a target domain. However, these methods have limited practical real world applications, since usually one has multiple source domains with different data distributions. In this work, we deal with the multi-source domain adaptation problem. Our method, namely StandardGAN, standardizes each source and target domains so that all the data have similar data distributions. We then use the standardized source domains to train a classifier and segment the standardized target domain. We conduct extensive experiments on two remote sensing data sets, in which the first one consists of multiple cities from a single country, and the other one contains multiple cities from different countries. Our experimental results show that the standardized data generated by StandardGAN allow the classifiers to generate significantly better segmentation.
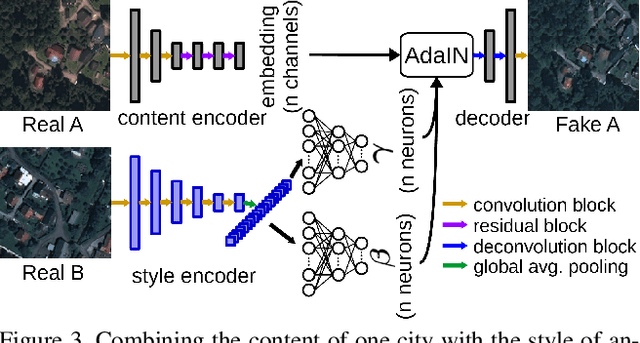
SemI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data
Feb 21, 2020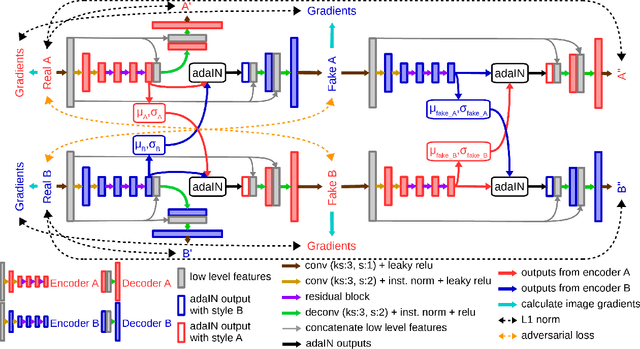
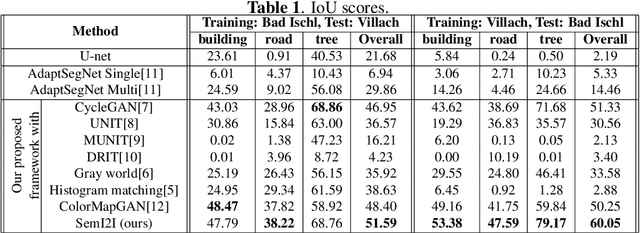

Although convolutional neural networks have been proven to be an effective tool to generate high quality maps from remote sensing images, their performance significantly deteriorates when there exists a large domain shift between training and test data. To address this issue, we propose a new data augmentation approach that transfers the style of test data to training data using generative adversarial networks. Our semantic segmentation framework consists in first training a U-net from the real training data and then fine-tuning it on the test stylized fake training data generated by the proposed approach. Our experimental results prove that our framework outperforms the existing domain adaptation methods.
ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks
Jul 30, 2019
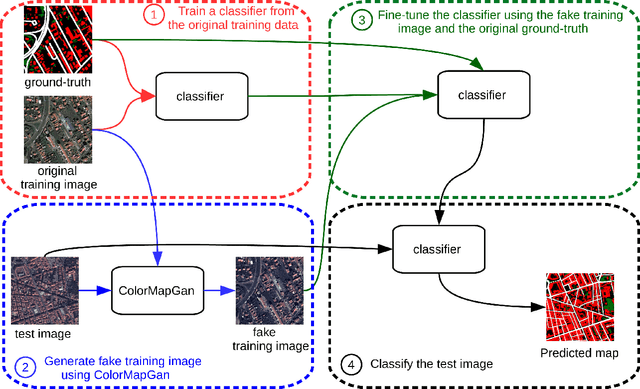
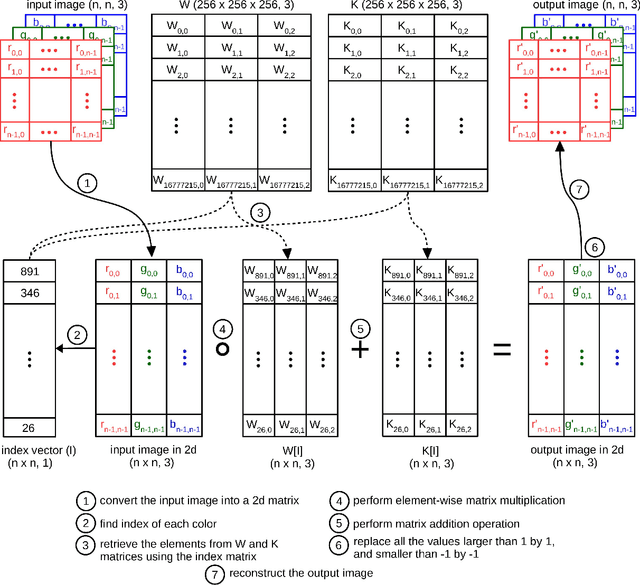
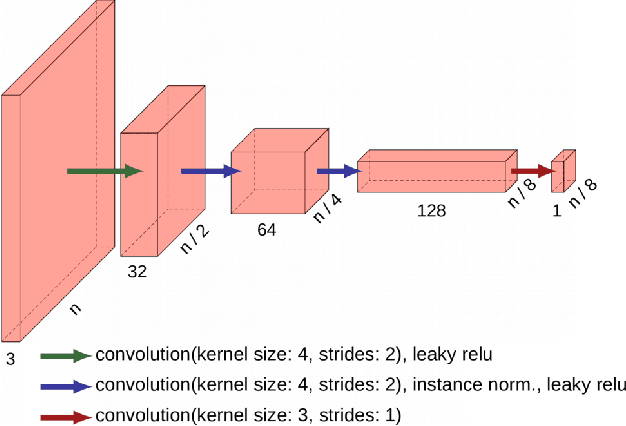
Due to the various reasons such as atmospheric effects and differences in acquisition, it is often the case that there exists a large difference between spectral bands of satellite images collected from different geographic locations. The large shift between spectral distributions of training and test data causes the current state of the art supervised learning approaches to output poor maps. We present a novel end to end semantic segmentation framework that is robust to such shift. The key component of the proposed framework is Color Mapping Generative Adversarial Networks (ColorMapGAN), which can generate fake training images that are semantically exactly the same as training images, but whose spectral distribution is similar to the distribution of the test images. We then use the fake images and the ground-truth for the training images to fine-tune the already trained classifier. Contrary to the existing Generative Adversarial Networks (GAN), the generator in ColorMapGAN does not have any convolutional or pooling layers. It learns to transform the colors of the training data to the colors of the test data by performing only one element-wise matrix multiplication and one matrix addition operations. Thanks to the architecturally simple but powerful design of ColorMapGAN, the proposed framework outperforms the existing approaches with a large margin in terms of both accuracy and computational complexity.
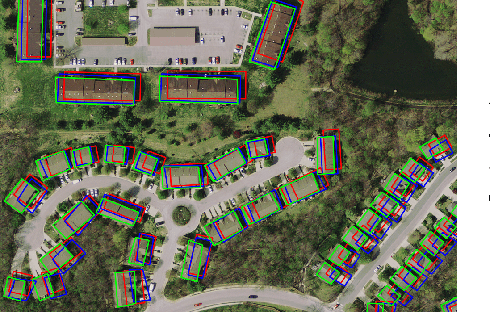
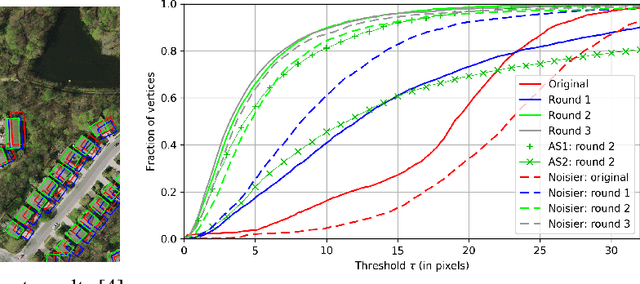
Noisy Supervision for Correcting Misaligned Cadaster Maps Without Perfect Ground Truth Data
Mar 12, 2019

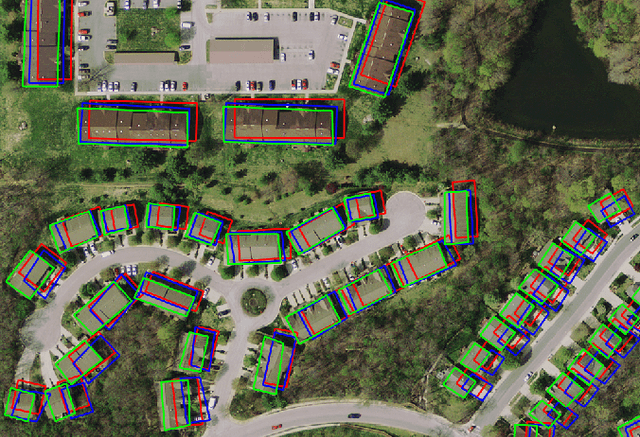

In machine learning the best performance on a certain task is achieved by fully supervised methods when perfect ground truth labels are available. However, labels are often noisy, especially in remote sensing where manually curated public datasets are rare. We study the multi-modal cadaster map alignment problem for which available annotations are mis-aligned polygons, resulting in noisy supervision. We subsequently set up a multiple-rounds training scheme which corrects the ground truth annotations at each round to better train the model at the next round. We show that it is possible to reduce the noise of the dataset by iteratively training a better alignment model to correct the annotation alignment.