 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe P$^3$ dataset: Pixels, Points and Polygons for Multimodal Building Vectorization
May 21, 2025



We present the P$^3$ dataset, a large-scale multimodal benchmark for building vectorization, constructed from aerial LiDAR point clouds, high-resolution aerial imagery, and vectorized 2D building outlines, collected across three continents. The dataset contains over 10 billion LiDAR points with decimeter-level accuracy and RGB images at a ground sampling distance of 25 centimeter. While many existing datasets primarily focus on the image modality, P$^3$ offers a complementary perspective by also incorporating dense 3D information. We demonstrate that LiDAR point clouds serve as a robust modality for predicting building polygons, both in hybrid and end-to-end learning frameworks. Moreover, fusing aerial LiDAR and imagery further improves accuracy and geometric quality of predicted polygons. The P$^3$ dataset is publicly available, along with code and pretrained weights of three state-of-the-art models for building polygon prediction at https://github.com/raphaelsulzer/PixelsPointsPolygons .
Input Similarity from the Neural Network Perspective
Feb 10, 2021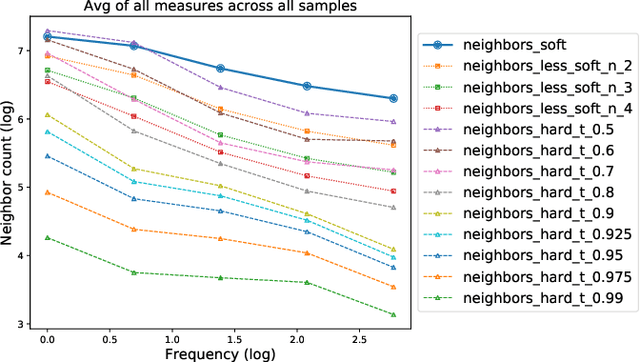

We first exhibit a multimodal image registration task, for which a neural network trained on a dataset with noisy labels reaches almost perfect accuracy, far beyond noise variance. This surprising auto-denoising phenomenon can be explained as a noise averaging effect over the labels of similar input examples. This effect theoretically grows with the number of similar examples; the question is then to define and estimate the similarity of examples. We express a proper definition of similarity, from the neural network perspective, i.e. we quantify how undissociable two inputs $A$ and $B$ are, taking a machine learning viewpoint: how much a parameter variation designed to change the output for $A$ would impact the output for $B$ as well? We study the mathematical properties of this similarity measure, and show how to use it on a trained network to estimate sample density, in low complexity, enabling new types of statistical analysis for neural networks. We analyze data by retrieving samples perceived as similar by the network, and are able to quantify the denoising effect without requiring true labels. We also propose, during training, to enforce that examples known to be similar should also be seen as similar by the network, and notice speed-up training effects for certain datasets.
Polygonal Building Segmentation by Frame Field Learning
Apr 30, 2020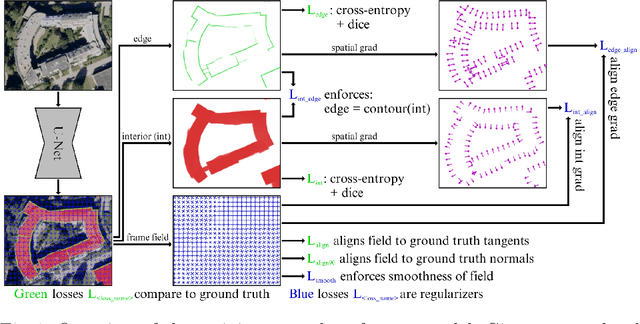
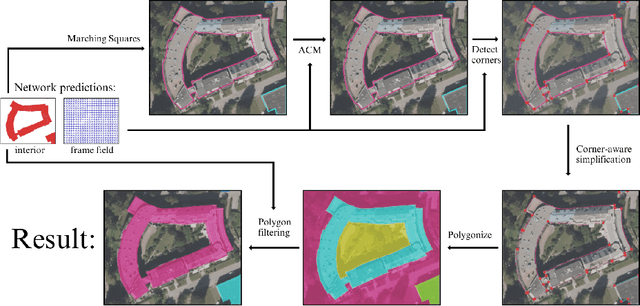

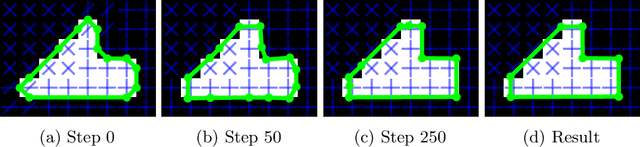
While state of the art image segmentation models typically output segmentations in raster format, applications in geographic information systems often require vector polygons. We propose adding a frame field output to a deep image segmentation model for extracting buildings from remote sensing images. This improves segmentation quality and provides structural information, facilitating more accurate polygonization. To this end, we train a deep neural network, which aligns a predicted frame field to ground truth contour data. In addition to increasing performance by leveraging multi-task learning, our method produces more regular segmentations. We also introduce a new polygonization algorithm, which is guided by the frame field corresponding to the raster segmentation.
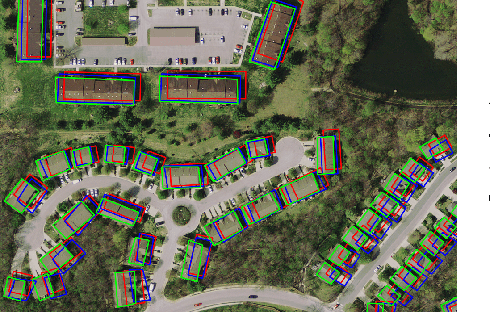
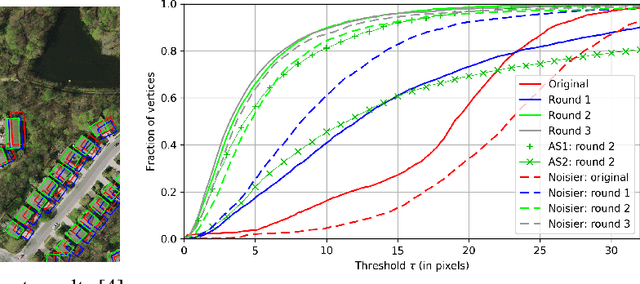
Noisy Supervision for Correcting Misaligned Cadaster Maps Without Perfect Ground Truth Data
Mar 12, 2019

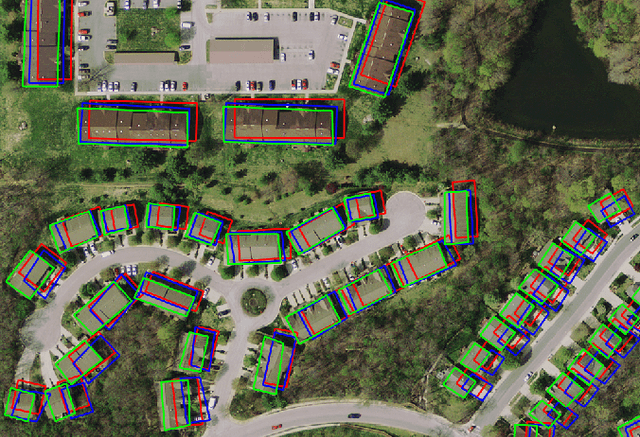

In machine learning the best performance on a certain task is achieved by fully supervised methods when perfect ground truth labels are available. However, labels are often noisy, especially in remote sensing where manually curated public datasets are rare. We study the multi-modal cadaster map alignment problem for which available annotations are mis-aligned polygons, resulting in noisy supervision. We subsequently set up a multiple-rounds training scheme which corrects the ground truth annotations at each round to better train the model at the next round. We show that it is possible to reduce the noise of the dataset by iteratively training a better alignment model to correct the annotation alignment.