 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIskra: A System for Inverse Geometry Processing
Feb 12, 2026We propose a system for differentiating through solutions to geometry processing problems. Our system differentiates a broad class of geometric algorithms, exploiting existing fast problem-specific schemes common to geometry processing, including local-global and ADMM solvers. It is compatible with machine learning frameworks, opening doors to new classes of inverse geometry processing applications. We marry the scatter-gather approach to mesh processing with tensor-based workflows and rely on the adjoint method applied to user-specified imperative code to generate an efficient backward pass behind the scenes. We demonstrate our approach by differentiating through mean curvature flow, spectral conformal parameterization, geodesic distance computation, and as-rigid-as-possible deformation, examining usability and performance on these applications. Our system allows practitioners to differentiate through existing geometry processing algorithms without needing to reformulate them, resulting in low implementation effort, fast runtimes, and lower memory requirements than differentiable optimization tools not tailored to geometry processing.
Locality in Image Diffusion Models Emerges from Data Statistics
Sep 11, 2025



Among generative models, diffusion models are uniquely intriguing due to the existence of a closed-form optimal minimizer of their training objective, often referred to as the optimal denoiser. However, diffusion using this optimal denoiser merely reproduces images in the training set and hence fails to capture the behavior of deep diffusion models. Recent work has attempted to characterize this gap between the optimal denoiser and deep diffusion models, proposing analytical, training-free models that can generate images that resemble those generated by a trained UNet. The best-performing method hypothesizes that shift equivariance and locality inductive biases of convolutional neural networks are the cause of the performance gap, hence incorporating these assumptions into its analytical model. In this work, we present evidence that the locality in deep diffusion models emerges as a statistical property of the image dataset, not due to the inductive bias of convolutional neural networks. Specifically, we demonstrate that an optimal parametric linear denoiser exhibits similar locality properties to the deep neural denoisers. We further show, both theoretically and experimentally, that this locality arises directly from the pixel correlations present in natural image datasets. Finally, we use these insights to craft an analytical denoiser that better matches scores predicted by a deep diffusion model than the prior expert-crafted alternative.
Low-Rank Adaptation of Neural Fields
Apr 22, 2025Processing visual data often involves small adjustments or sequences of changes, such as in image filtering, surface smoothing, and video storage. While established graphics techniques like normal mapping and video compression exploit redundancy to encode such small changes efficiently, the problem of encoding small changes to neural fields (NF) -- neural network parameterizations of visual or physical functions -- has received less attention. We propose a parameter-efficient strategy for updating neural fields using low-rank adaptations (LoRA). LoRA, a method from the parameter-efficient fine-tuning LLM community, encodes small updates to pre-trained models with minimal computational overhead. We adapt LoRA to instance-specific neural fields, avoiding the need for large pre-trained models yielding a pipeline suitable for low-compute hardware. We validate our approach with experiments in image filtering, video compression, and geometry editing, demonstrating its effectiveness and versatility for representing neural field updates.
Through the Looking Glass: Mirror Schrödinger Bridges
Oct 09, 2024



Resampling from a target measure whose density is unknown is a fundamental problem in mathematical statistics and machine learning. A setting that dominates the machine learning literature consists of learning a map from an easy-to-sample prior, such as the Gaussian distribution, to a target measure. Under this model, samples from the prior are pushed forward to generate a new sample on the target measure, which is often difficult to sample from directly. In this paper, we propose a new model for conditional resampling called mirror Schr\"odinger bridges. Our key observation is that solving the Schr\"odinger bridge problem between a distribution and itself provides a natural way to produce new samples from conditional distributions, giving in-distribution variations of an input data point. We show how to efficiently solve this largely overlooked version of the Schr\"odinger bridge problem. We prove that our proposed method leads to significant algorithmic simplifications over existing alternatives, in addition to providing control over in-distribution variation. Empirically, we demonstrate how these benefits can be leveraged to produce proximal samples in a number of application domains.
Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead
Jun 17, 2024



Fine-tuning large language models (LLMs) with low-rank adapters (LoRAs) has become common practice, often yielding numerous copies of the same LLM differing only in their LoRA updates. This paradigm presents challenges for systems that serve real-time responses to queries that each involve a different LoRA. Prior works optimize the design of such systems but still require continuous loading and offloading of LoRAs, as it is infeasible to store thousands of LoRAs in GPU memory. To mitigate this issue, we investigate the efficacy of compression when serving LoRA adapters. We consider compressing adapters individually via SVD and propose a method for joint compression of LoRAs into a shared basis paired with LoRA-specific scaling matrices. Our experiments with up to 500 LoRAs demonstrate that compressed LoRAs preserve performance while offering major throughput gains in realistic serving scenarios with over a thousand LoRAs, maintaining 75% of the throughput of serving a single LoRA.
Slicing Mutual Information Generalization Bounds for Neural Networks
Jun 06, 2024



The ability of machine learning (ML) algorithms to generalize well to unseen data has been studied through the lens of information theory, by bounding the generalization error with the input-output mutual information (MI), i.e., the MI between the training data and the learned hypothesis. Yet, these bounds have limited practicality for modern ML applications (e.g., deep learning), due to the difficulty of evaluating MI in high dimensions. Motivated by recent findings on the compressibility of neural networks, we consider algorithms that operate by slicing the parameter space, i.e., trained on random lower-dimensional subspaces. We introduce new, tighter information-theoretic generalization bounds tailored for such algorithms, demonstrating that slicing improves generalization. Our bounds offer significant computational and statistical advantages over standard MI bounds, as they rely on scalable alternative measures of dependence, i.e., disintegrated mutual information and $k$-sliced mutual information. Then, we extend our analysis to algorithms whose parameters do not need to exactly lie on random subspaces, by leveraging rate-distortion theory. This strategy yields generalization bounds that incorporate a distortion term measuring model compressibility under slicing, thereby tightening existing bounds without compromising performance or requiring model compression. Building on this, we propose a regularization scheme enabling practitioners to control generalization through compressibility. Finally, we empirically validate our results and achieve the computation of non-vacuous information-theoretic generalization bounds for neural networks, a task that was previously out of reach.
Robust Biharmonic Skinning Using Geometric Fields
Jun 01, 2024



Skinning is a popular way to rig and deform characters for animation, to compute reduced-order simulations, and to define features for geometry processing. Methods built on skinning rely on weight functions that distribute the influence of each degree of freedom across the mesh. Automatic skinning methods generate these weight functions with minimal user input, usually by solving a variational problem on a mesh whose boundary is the skinned surface. This formulation necessitates tetrahedralizing the volume inside the surface, which brings with it meshing artifacts, the possibility of tetrahedralization failure, and the impossibility of generating weights for surfaces that are not closed. We introduce a mesh-free and robust automatic skinning method that generates high-quality skinning weights comparable to the current state of the art without volumetric meshes. Our method reliably works even on open surfaces and triangle soups where current methods fail. We achieve this through the use of a Lagrangian representation for skinning weights, which circumvents the need for finite elements while optimizing the biharmonic energy.
Score Distillation via Reparametrized DDIM
May 24, 2024While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.
Nuclear Norm Regularization for Deep Learning
May 23, 2024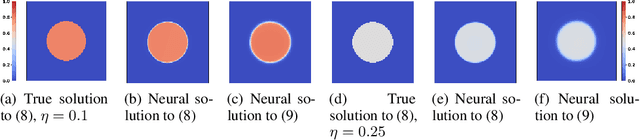
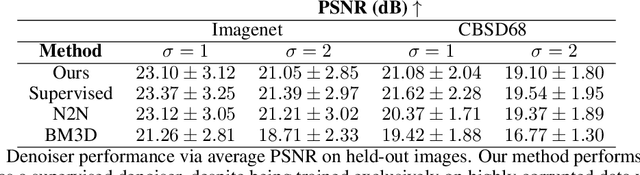
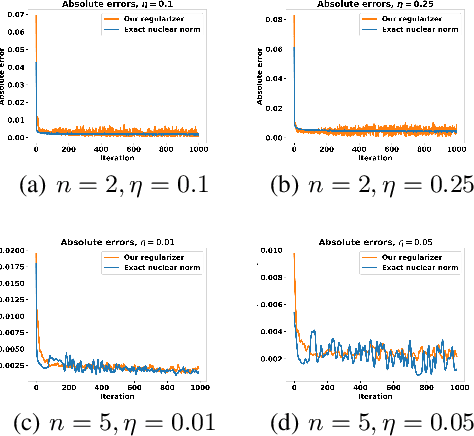
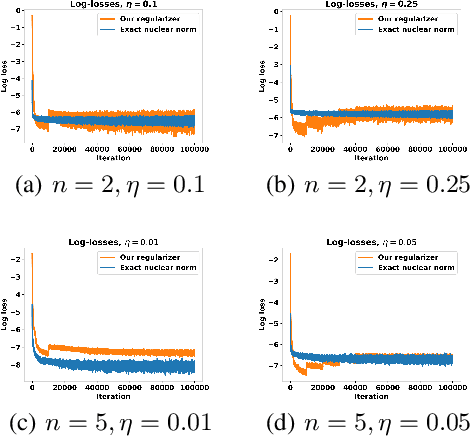
Penalizing the nuclear norm of a function's Jacobian encourages it to locally behave like a low-rank linear map. Such functions vary locally along only a handful of directions, making the Jacobian nuclear norm a natural regularizer for machine learning problems. However, this regularizer is intractable for high-dimensional problems, as it requires computing a large Jacobian matrix and taking its singular value decomposition. We show how to efficiently penalize the Jacobian nuclear norm using techniques tailor-made for deep learning. We prove that for functions parametrized as compositions $f = g \circ h$, one may equivalently penalize the average squared Frobenius norm of $Jg$ and $Jh$. We then propose a denoising-style approximation that avoids the Jacobian computations altogether. Our method is simple, efficient, and accurate, enabling Jacobian nuclear norm regularization to scale to high-dimensional deep learning problems. We complement our theory with an empirical study of our regularizer's performance and investigate applications to denoising and representation learning.
Asymmetry in Low-Rank Adapters of Foundation Models
Feb 27, 2024



Parameter-efficient fine-tuning optimizes large, pre-trained foundation models by updating a subset of parameters; in this class, Low-Rank Adaptation (LoRA) is particularly effective. Inspired by an effort to investigate the different roles of LoRA matrices during fine-tuning, this paper characterizes and leverages unexpected asymmetry in the importance of low-rank adapter matrices. Specifically, when updating the parameter matrices of a neural network by adding a product $BA$, we observe that the $B$ and $A$ matrices have distinct functions: $A$ extracts features from the input, while $B$ uses these features to create the desired output. Based on this observation, we demonstrate that fine-tuning $B$ is inherently more effective than fine-tuning $A$, and that a random untrained $A$ should perform nearly as well as a fine-tuned one. Using an information-theoretic lens, we also bound the generalization of low-rank adapters, showing that the parameter savings of exclusively training $B$ improves the bound. We support our conclusions with experiments on RoBERTa, BART-Large, LLaMA-2, and ViTs.