 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuclear Norm Regularization for Deep Learning
Paper and Code
May 23, 2024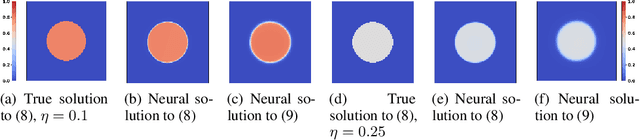
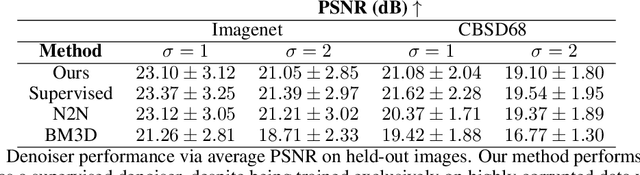
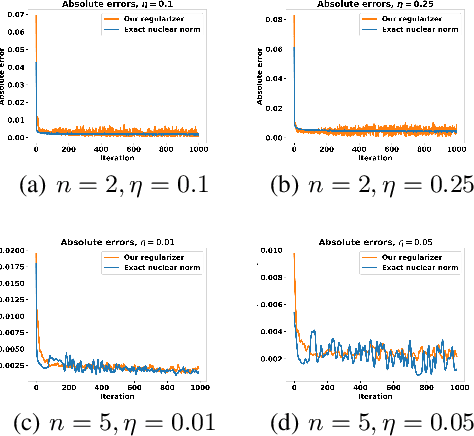
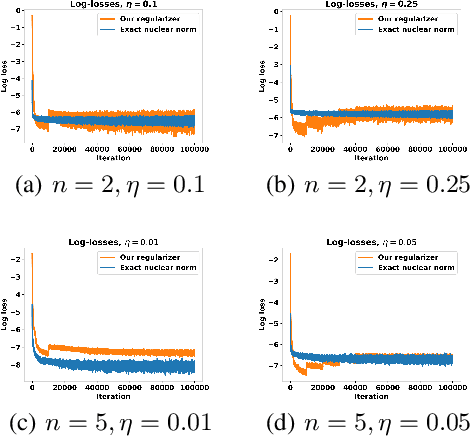
Penalizing the nuclear norm of a function's Jacobian encourages it to locally behave like a low-rank linear map. Such functions vary locally along only a handful of directions, making the Jacobian nuclear norm a natural regularizer for machine learning problems. However, this regularizer is intractable for high-dimensional problems, as it requires computing a large Jacobian matrix and taking its singular value decomposition. We show how to efficiently penalize the Jacobian nuclear norm using techniques tailor-made for deep learning. We prove that for functions parametrized as compositions $f = g \circ h$, one may equivalently penalize the average squared Frobenius norm of $Jg$ and $Jh$. We then propose a denoising-style approximation that avoids the Jacobian computations altogether. Our method is simple, efficient, and accurate, enabling Jacobian nuclear norm regularization to scale to high-dimensional deep learning problems. We complement our theory with an empirical study of our regularizer's performance and investigate applications to denoising and representation learning.