 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompress then Serve: Serving Thousands of LoRA Adapters with Little Overhead
Jun 17, 2024



Fine-tuning large language models (LLMs) with low-rank adapters (LoRAs) has become common practice, often yielding numerous copies of the same LLM differing only in their LoRA updates. This paradigm presents challenges for systems that serve real-time responses to queries that each involve a different LoRA. Prior works optimize the design of such systems but still require continuous loading and offloading of LoRAs, as it is infeasible to store thousands of LoRAs in GPU memory. To mitigate this issue, we investigate the efficacy of compression when serving LoRA adapters. We consider compressing adapters individually via SVD and propose a method for joint compression of LoRAs into a shared basis paired with LoRA-specific scaling matrices. Our experiments with up to 500 LoRAs demonstrate that compressed LoRAs preserve performance while offering major throughput gains in realistic serving scenarios with over a thousand LoRAs, maintaining 75% of the throughput of serving a single LoRA.
Deep Augmentation: Enhancing Self-Supervised Learning through Transformations in Higher Activation Space
Mar 25, 2023



We introduce Deep Augmentation, an approach to data augmentation using dropout to dynamically transform a targeted layer within a neural network, with the option to use the stop-gradient operation, offering significant improvements in model performance and generalization. We demonstrate the efficacy of Deep Augmentation through extensive experiments on contrastive learning tasks in computer vision and NLP domains, where we observe substantial performance gains with ResNets and Transformers as the underlying models. Our experimentation reveals that targeting deeper layers with Deep Augmentation outperforms augmenting the input data, and the simple network- and data-agnostic nature of this approach enables its seamless integration into computer vision and NLP pipelines.
Rewiring with Positional Encodings for Graph Neural Networks
Feb 02, 2022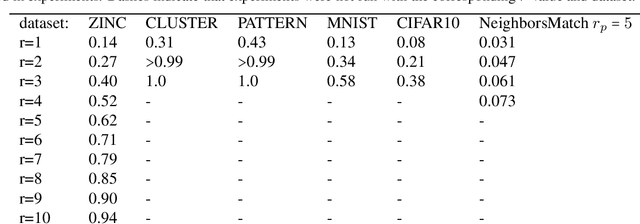
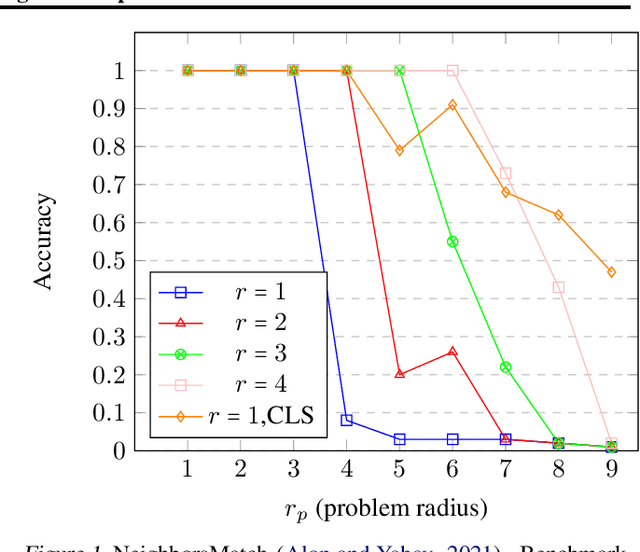
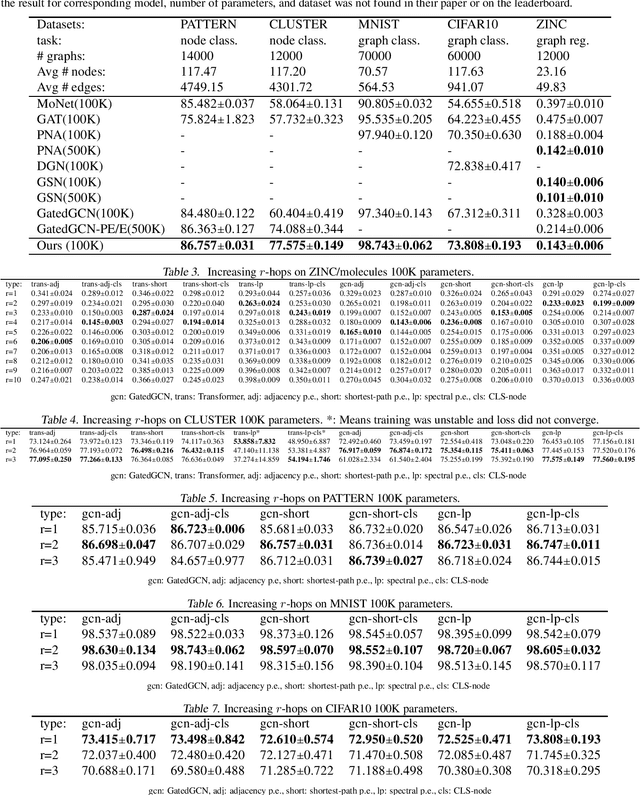
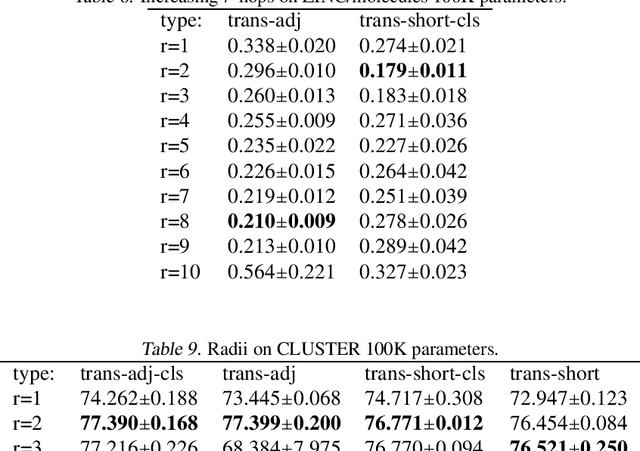
Several recent works use positional encodings to extend the receptive fields of graph neural network (GNN) layers equipped with attention mechanisms. These techniques, however, extend receptive fields to the complete graph, at substantial computational cost and risking a change in the inductive biases of conventional GNNs, or require complex architecture adjustments. As a conservative alternative, we use positional encodings to expand receptive fields to any r-ring. Our method augments the input graph with additional nodes/edges and uses positional encodings as node and/or edge features. Thus, it is compatible with many existing GNN architectures. We also provide examples of positional encodings that are non-invasive, i.e., there is a one-to-one map between the original and the modified graphs. Our experiments demonstrate that extending receptive fields via positional encodings and a virtual fully-connected node significantly improves GNN performance and alleviates over-squashing using small r. We obtain improvements across models, showing state-of-the-art performance even using older architectures than recent Transformer models adapted to graphs.
Relative Position Prediction as Pre-training for Text Encoders
Feb 02, 2022
Meaning is defined by the company it keeps. However, company is two-fold: It's based on the identity of tokens and also on their position (topology). We argue that a position-centric perspective is more general and useful. The classic MLM and CLM objectives in NLP are easily phrased as position predictions over the whole vocabulary. Adapting the relative position encoding paradigm in NLP to create relative labels for self-supervised learning, we seek to show superior pre-training judged by performance on downstream tasks.
Universal Function Approximation on Graphs using Multivalued Functions
Mar 14, 2020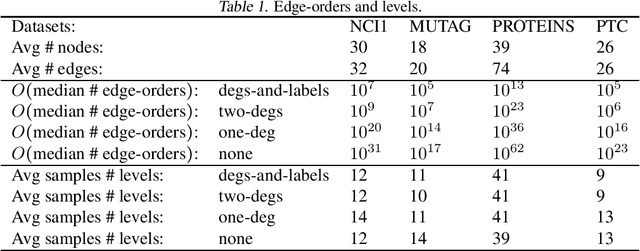
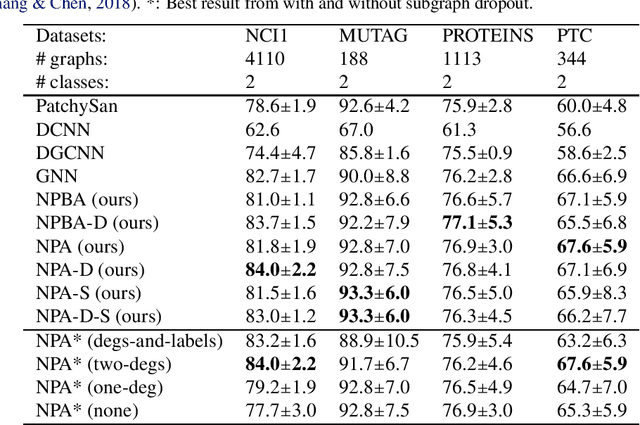
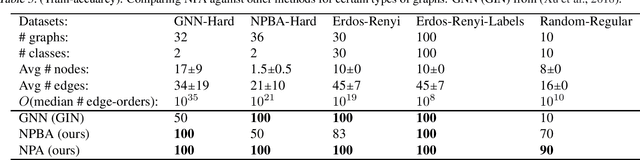
In this work we produce a framework for constructing universal function approximators on graph isomorphism classes. Additionally, we prove how this framework comes with a collection of theoretically desirable properties and enables novel analysis. We show how this allows us to outperform state of the art on four different well known datasets in graph classification and how our method can separate classes of graphs that other graph-learning methods cannot. Our approach is inspired by persistence homology, dependency parsing for Natural Language Processing, and multivalued functions. The complexity of the underlying algorithm is O(mn) and code is publicly available.
A Topology Layer for Machine Learning
May 29, 2019



Topology applied to real world data using persistent homology has started to find applications within machine learning, including deep learning. We present a differentiable topology layer that computes persistent homology based on level set filtrations and distance-bases filtrations. We present three novel applications: the topological layer can (i) serve as a regularizer directly on data or the weights of machine learning models, (ii) construct a loss on the output of a deep generative network to incorporate topological priors, and (iii) perform topological adversarial attacks on deep networks trained with persistence features. The code is publicly available and we hope its availability will facilitate the use of persistent homology in deep learning and other gradient based applications.