 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLACID: Identity-Preserving Multi-Object Compositing via Video Diffusion with Synthetic Trajectories
Jan 30, 2026Recent advances in generative AI have dramatically improved photorealistic image synthesis, yet they fall short for studio-level multi-object compositing. This task demands simultaneous (i) near-perfect preservation of each item's identity, (ii) precise background and color fidelity, (iii) layout and design elements control, and (iv) complete, appealing displays showcasing all objects. However, current state-of-the-art models often alter object details, omit or duplicate objects, and produce layouts with incorrect relative sizing or inconsistent item presentations. To bridge this gap, we introduce PLACID, a framework that transforms a collection of object images into an appealing multi-object composite. Our approach makes two main contributions. First, we leverage a pretrained image-to-video (I2V) diffusion model with text control to preserve objects consistency, identities, and background details by exploiting temporal priors from videos. Second, we propose a novel data curation strategy that generates synthetic sequences where randomly placed objects smoothly move to their target positions. This synthetic data aligns with the video model's temporal priors during training. At inference, objects initialized at random positions consistently converge into coherent layouts guided by text, with the final frame serving as the composite image. Extensive quantitative evaluations and user studies demonstrate that PLACID surpasses state-of-the-art methods in multi-object compositing, achieving superior identity, background, and color preservation, with less omitted objects and visually appealing results.
A Vision Check-up for Language Models
Jan 03, 2024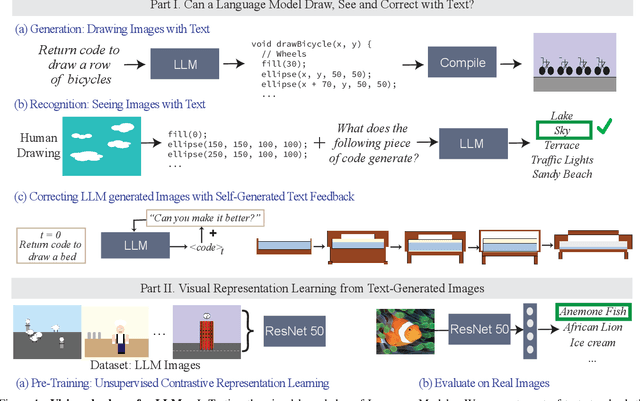
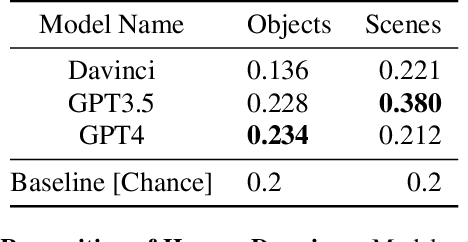

What does learning to model relationships between strings teach large language models (LLMs) about the visual world? We systematically evaluate LLMs' abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world. Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs.
Background Prompting for Improved Object Depth
Jun 08, 2023Estimating the depth of objects from a single image is a valuable task for many vision, robotics, and graphics applications. However, current methods often fail to produce accurate depth for objects in diverse scenes. In this work, we propose a simple yet effective Background Prompting strategy that adapts the input object image with a learned background. We learn the background prompts only using small-scale synthetic object datasets. To infer object depth on a real image, we place the segmented object into the learned background prompt and run off-the-shelf depth networks. Background Prompting helps the depth networks focus on the foreground object, as they are made invariant to background variations. Moreover, Background Prompting minimizes the domain gap between synthetic and real object images, leading to better sim2real generalization than simple finetuning. Results on multiple synthetic and real datasets demonstrate consistent improvements in real object depths for a variety of existing depth networks. Code and optimized background prompts can be found at: https://mbaradad.github.io/depth_prompt.
Deep Augmentation: Enhancing Self-Supervised Learning through Transformations in Higher Activation Space
Mar 25, 2023



We introduce Deep Augmentation, an approach to data augmentation using dropout to dynamically transform a targeted layer within a neural network, with the option to use the stop-gradient operation, offering significant improvements in model performance and generalization. We demonstrate the efficacy of Deep Augmentation through extensive experiments on contrastive learning tasks in computer vision and NLP domains, where we observe substantial performance gains with ResNets and Transformers as the underlying models. Our experimentation reveals that targeting deeper layers with Deep Augmentation outperforms augmenting the input data, and the simple network- and data-agnostic nature of this approach enables its seamless integration into computer vision and NLP pipelines.
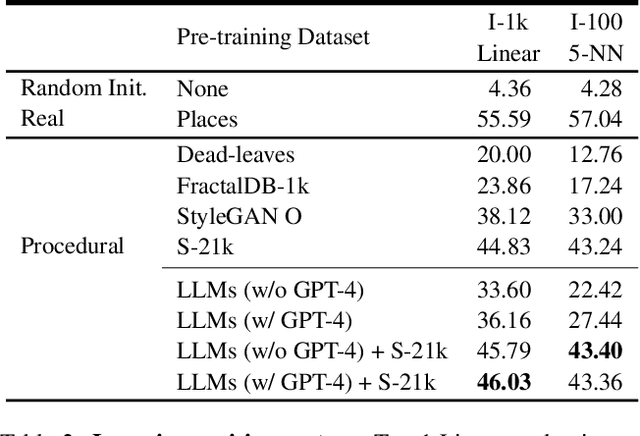
Procedural Image Programs for Representation Learning
Nov 29, 2022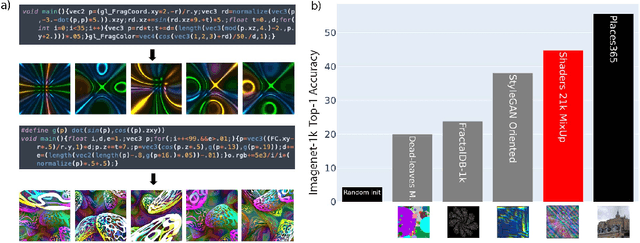
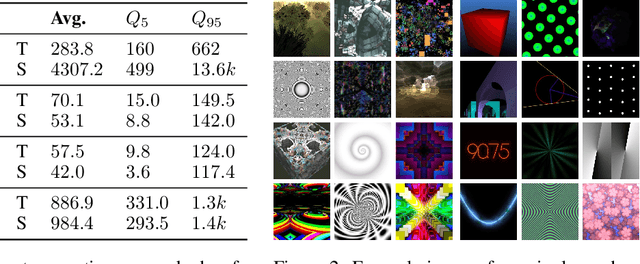
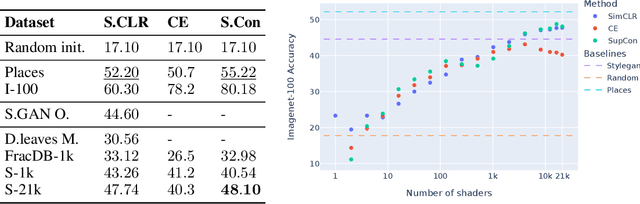
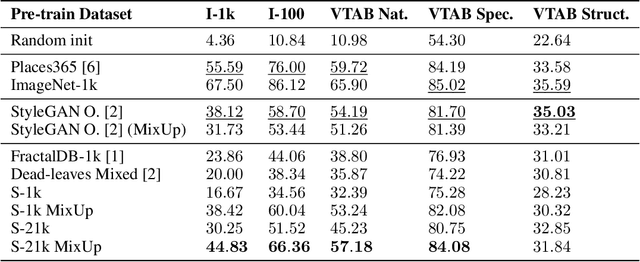
Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
Learning to See by Looking at Noise
Jun 10, 2021
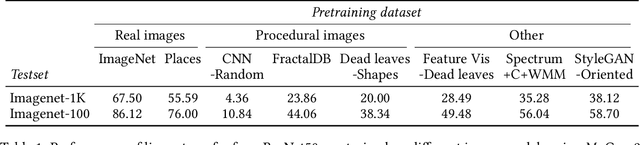

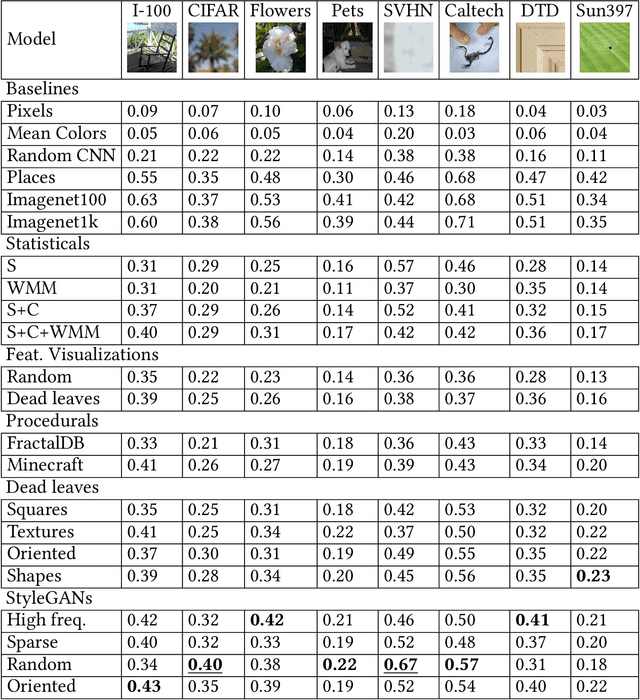
Current vision systems are trained on huge datasets, and these datasets come with costs: curation is expensive, they inherit human biases, and there are concerns over privacy and usage rights. To counter these costs, interest has surged in learning from cheaper data sources, such as unlabeled images. In this paper we go a step further and ask if we can do away with real image datasets entirely, instead learning from noise processes. We investigate a suite of image generation models that produce images from simple random processes. These are then used as training data for a visual representation learner with a contrastive loss. We study two types of noise processes, statistical image models and deep generative models under different random initializations. Our findings show that it is important for the noise to capture certain structural properties of real data but that good performance can be achieved even with processes that are far from realistic. We also find that diversity is a key property to learn good representations. Datasets, models, and code are available at https://mbaradad.github.io/learning_with_noise.
Recurrent Neural Networks for Semantic Instance Segmentation
Sep 03, 2018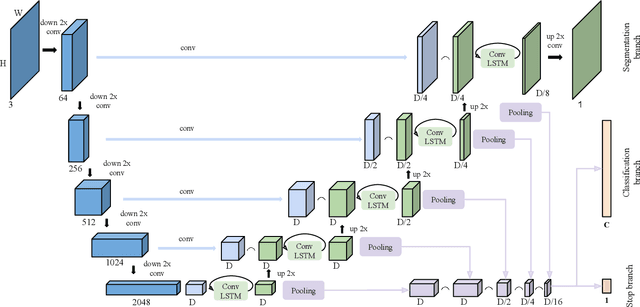

We present a recurrent model for semantic instance segmentation that sequentially generates binary masks and their associated class probabilities for every object in an image. Our proposed system is trainable end-to-end from an input image to a sequence of labeled masks and, compared to methods relying on object proposals, does not require post-processing steps on its output. We study the suitability of our recurrent model on three different instance segmentation benchmarks, namely Pascal VOC 2012, CVPPP Plant Leaf Segmentation and Cityscapes. Further, we analyze the object sorting patterns generated by our model and observe that it learns to follow a consistent pattern, which correlates with the activations learned in the encoder part of our network. Source code and models are available at https://imatge-upc.github.io/rsis/