 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D hierarchical optimization for Multi-view depth map coding
Nov 01, 2019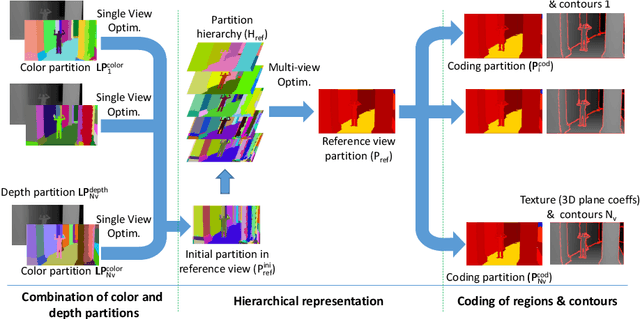
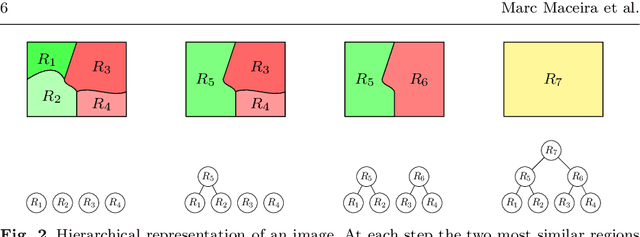


Depth data has a widespread use since the popularity of high-resolution 3D sensors. In multi-view sequences, depth information is used to supplement the color data of each view. This article proposes a joint encoding of multiple depth maps with a unique representation. Color and depth images of each view are segmented independently and combined in an optimal Rate-Distortion fashion. The resulting partitions are projected to a reference view where a coherent hierarchy for the multiple views is built. A Rate-Distortionoptimization is applied to obtain the final segmentation choosing nodes of the hierarchy. The consistent segmentation is used to robustly encode depth maps of multiple views obtaining competitive results with HEVC coding standards. Available at: http://link.springer.com/article/10.1007/s11042-017-5409-z
RVOS: End-to-End Recurrent Network for Video Object Segmentation
Mar 13, 2019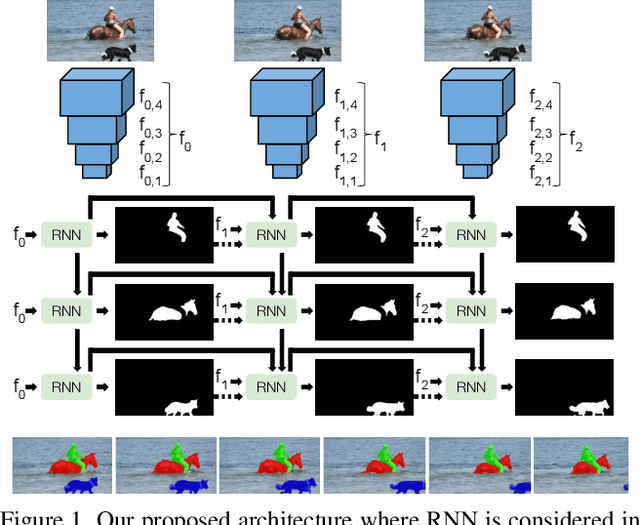
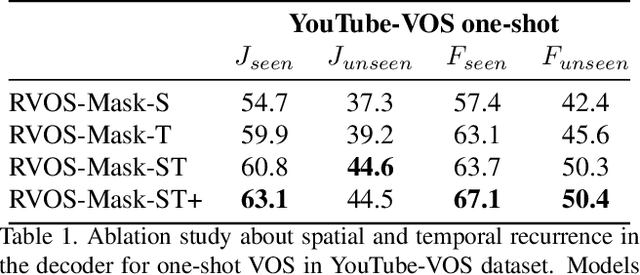
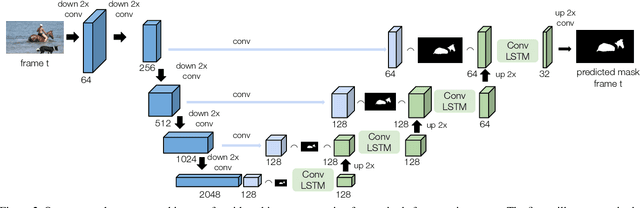
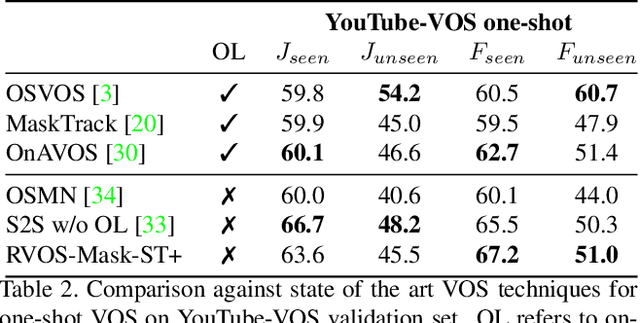
Multiple object video object segmentation is a challenging task, specially for the zero-shot case, when no object mask is given at the initial frame and the model has to find the objects to be segmented along the sequence. In our work, we propose a Recurrent network for multiple object Video Object Segmentation (RVOS) that is fully end-to-end trainable. Our model incorporates recurrence on two different domains: (i) the spatial, which allows to discover the different object instances within a frame, and (ii) the temporal, which allows to keep the coherence of the segmented objects along time. We train RVOS for zero-shot video object segmentation and are the first ones to report quantitative results for DAVIS-2017 and YouTube-VOS benchmarks. Further, we adapt RVOS for one-shot video object segmentation by using the masks obtained in previous time steps as inputs to be processed by the recurrent module. Our model reaches comparable results to state-of-the-art techniques in YouTube-VOS benchmark and outperforms all previous video object segmentation methods not using online learning in the DAVIS-2017 benchmark. Moreover, our model achieves faster inference runtimes than previous methods, reaching 44ms/frame on a P100 GPU.
Recurrent Neural Networks for Semantic Instance Segmentation
Sep 03, 2018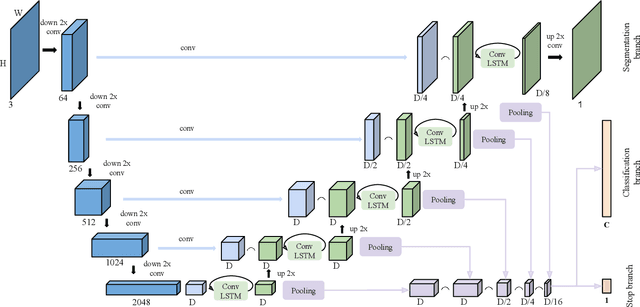

We present a recurrent model for semantic instance segmentation that sequentially generates binary masks and their associated class probabilities for every object in an image. Our proposed system is trainable end-to-end from an input image to a sequence of labeled masks and, compared to methods relying on object proposals, does not require post-processing steps on its output. We study the suitability of our recurrent model on three different instance segmentation benchmarks, namely Pascal VOC 2012, CVPPP Plant Leaf Segmentation and Cityscapes. Further, we analyze the object sorting patterns generated by our model and observe that it learns to follow a consistent pattern, which correlates with the activations learned in the encoder part of our network. Source code and models are available at https://imatge-upc.github.io/rsis/
Hierarchical Object Detection with Deep Reinforcement Learning
Nov 25, 2016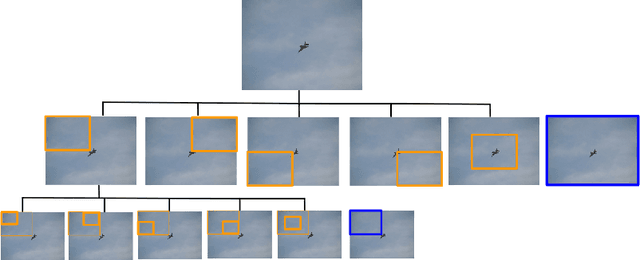
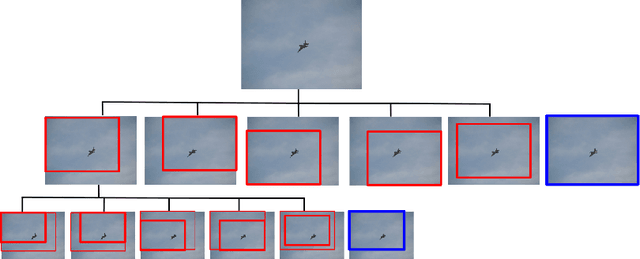


We present a method for performing hierarchical object detection in images guided by a deep reinforcement learning agent. The key idea is to focus on those parts of the image that contain richer information and zoom on them. We train an intelligent agent that, given an image window, is capable of deciding where to focus the attention among five different predefined region candidates (smaller windows). This procedure is iterated providing a hierarchical image analysis.We compare two different candidate proposal strategies to guide the object search: with and without overlap. Moreover, our work compares two different strategies to extract features from a convolutional neural network for each region proposal: a first one that computes new feature maps for each region proposal, and a second one that computes the feature maps for the whole image to later generate crops for each region proposal. Experiments indicate better results for the overlapping candidate proposal strategy and a loss of performance for the cropped image features due to the loss of spatial resolution. We argue that, while this loss seems unavoidable when working with large amounts of object candidates, the much more reduced amount of region proposals generated by our reinforcement learning agent allows considering to extract features for each location without sharing convolutional computation among regions.
Faster R-CNN Features for Instance Search
Apr 29, 2016
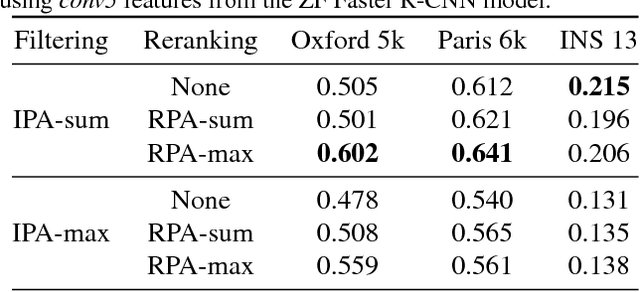
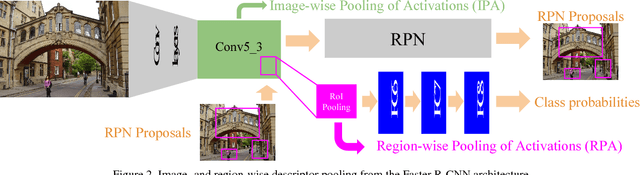

Image representations derived from pre-trained Convolutional Neural Networks (CNNs) have become the new state of the art in computer vision tasks such as instance retrieval. This work explores the suitability for instance retrieval of image- and region-wise representations pooled from an object detection CNN such as Faster R-CNN. We take advantage of the object proposals learned by a Region Proposal Network (RPN) and their associated CNN features to build an instance search pipeline composed of a first filtering stage followed by a spatial reranking. We further investigate the suitability of Faster R-CNN features when the network is fine-tuned for the same objects one wants to retrieve. We assess the performance of our proposed system with the Oxford Buildings 5k, Paris Buildings 6k and a subset of TRECVid Instance Search 2013, achieving competitive results.
Bags of Local Convolutional Features for Scalable Instance Search
Apr 15, 2016
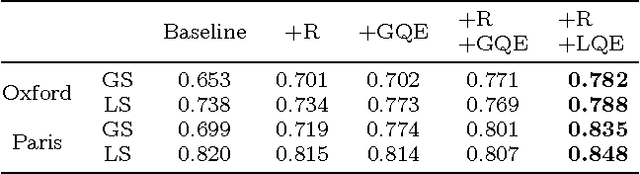


This work proposes a simple instance retrieval pipeline based on encoding the convolutional features of CNN using the bag of words aggregation scheme (BoW). Assigning each local array of activations in a convolutional layer to a visual word produces an \textit{assignment map}, a compact representation that relates regions of an image with a visual word. We use the assignment map for fast spatial reranking, obtaining object localizations that are used for query expansion. We demonstrate the suitability of the BoW representation based on local CNN features for instance retrieval, achieving competitive performance on the Oxford and Paris buildings benchmarks. We show that our proposed system for CNN feature aggregation with BoW outperforms state-of-the-art techniques using sum pooling at a subset of the challenging TRECVid INS benchmark.
Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation
Mar 01, 2016
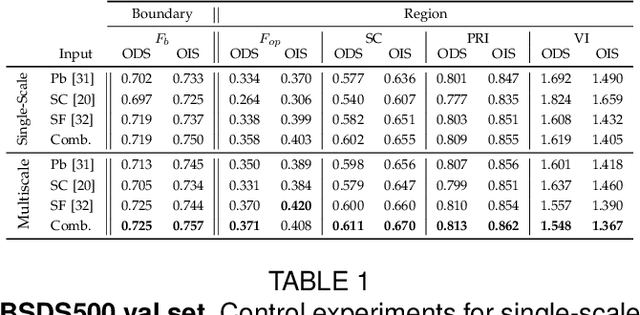
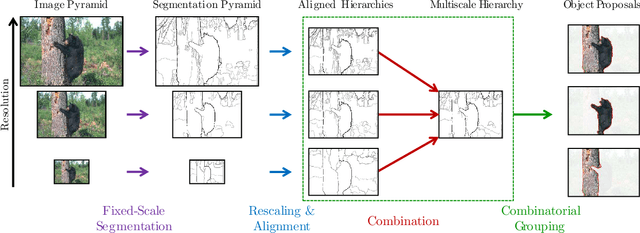
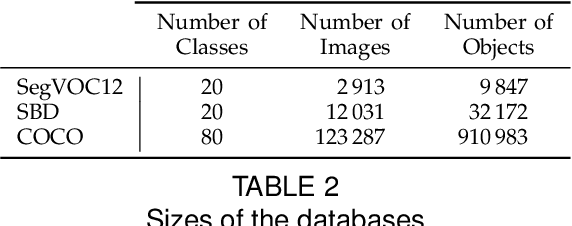
We propose a unified approach for bottom-up hierarchical image segmentation and object proposal generation for recognition, called Multiscale Combinatorial Grouping (MCG). For this purpose, we first develop a fast normalized cuts algorithm. We then propose a high-performance hierarchical segmenter that makes effective use of multiscale information. Finally, we propose a grouping strategy that combines our multiscale regions into highly-accurate object proposals by exploring efficiently their combinatorial space. We also present Single-scale Combinatorial Grouping (SCG), a faster version of MCG that produces competitive proposals in under five second per image. We conduct an extensive and comprehensive empirical validation on the BSDS500, SegVOC12, SBD, and COCO datasets, showing that MCG produces state-of-the-art contours, hierarchical regions, and object proposals.
Multiresolution hierarchy co-clustering for semantic segmentation in sequences with small variations
Oct 16, 2015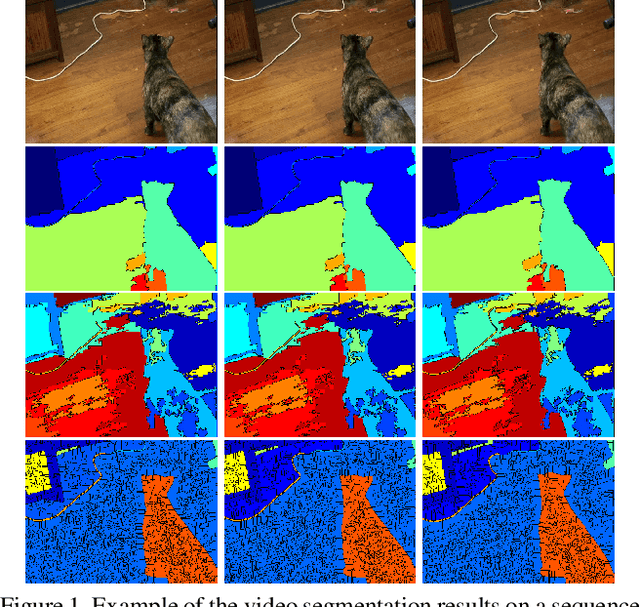
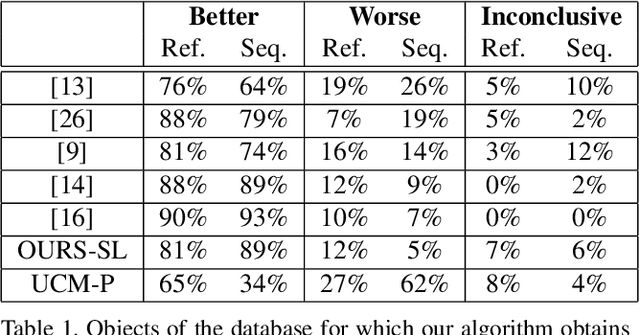
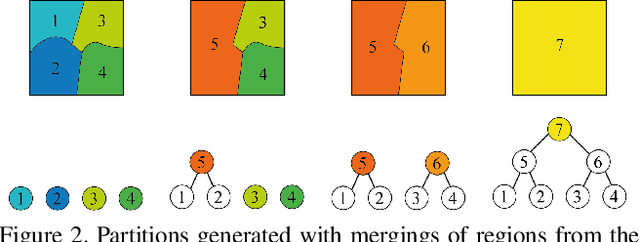

This paper presents a co-clustering technique that, given a collection of images and their hierarchies, clusters nodes from these hierarchies to obtain a coherent multiresolution representation of the image collection. We formalize the co-clustering as a Quadratic Semi-Assignment Problem and solve it with a linear programming relaxation approach that makes effective use of information from hierarchies. Initially, we address the problem of generating an optimal, coherent partition per image and, afterwards, we extend this method to a multiresolution framework. Finally, we particularize this framework to an iterative multiresolution video segmentation algorithm in sequences with small variations. We evaluate the algorithm on the Video Occlusion/Object Boundary Detection Dataset, showing that it produces state-of-the-art results in these scenarios.