 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Object Tracking from appearance by hierarchically clustering tracklets
Oct 07, 2022
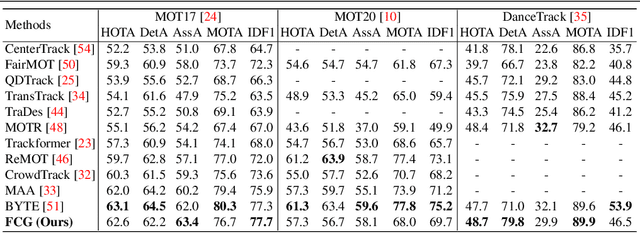

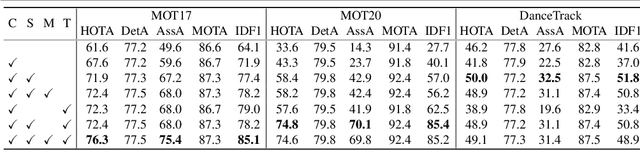
Current approaches in Multiple Object Tracking (MOT) rely on the spatio-temporal coherence between detections combined with object appearance to match objects from consecutive frames. In this work, we explore MOT using object appearances as the main source of association between objects in a video, using spatial and temporal priors as weighting factors. We form initial tracklets by leveraging on the idea that instances of an object that are close in time should be similar in appearance, and build the final object tracks by fusing the tracklets in a hierarchical fashion. We conduct extensive experiments that show the effectiveness of our method over three different MOT benchmarks, MOT17, MOT20, and DanceTrack, being competitive in MOT17 and MOT20 and establishing state-of-the-art results in DanceTrack.
Multiple Object Tracking with Mixture Density Networks for Trajectory Estimation
Jun 22, 2021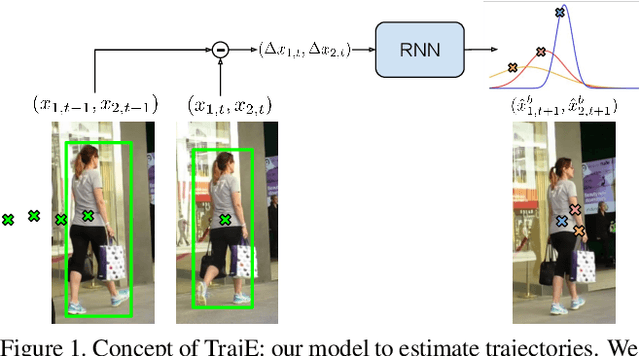
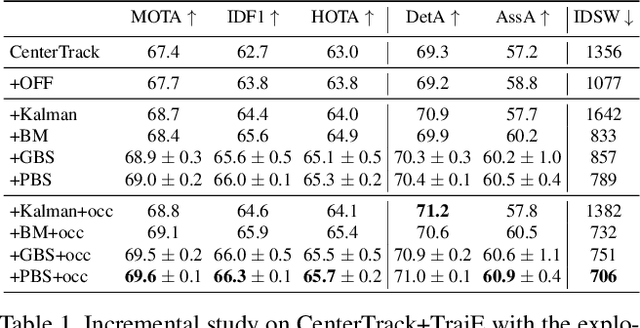

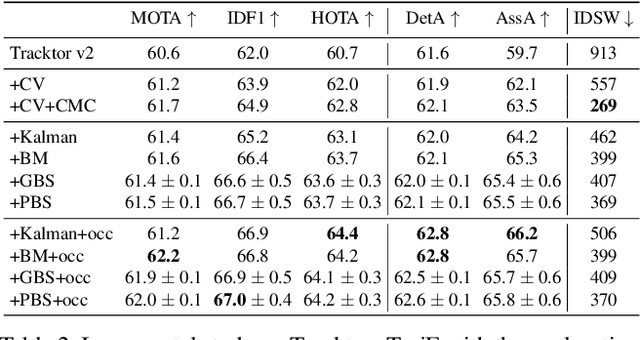
Multiple object tracking faces several challenges that may be alleviated with trajectory information. Knowing the posterior locations of an object helps disambiguating and solving situations such as occlusions, re-identification, and identity switching. In this work, we show that trajectory estimation can become a key factor for tracking, and present TrajE, a trajectory estimator based on recurrent mixture density networks, as a generic module that can be added to existing object trackers. To provide several trajectory hypotheses, our method uses beam search. Also, relying on the same estimated trajectory, we propose to reconstruct a track after an occlusion occurs. We integrate TrajE into two state of the art tracking algorithms, CenterTrack [63] and Tracktor [3]. Their respective performances in the MOTChallenge 2017 test set are boosted 6.3 and 0.3 points in MOTA score, and 1.8 and 3.1 in IDF1, setting a new state of the art for the CenterTrack+TrajE configuration
RVOS: End-to-End Recurrent Network for Video Object Segmentation
Mar 13, 2019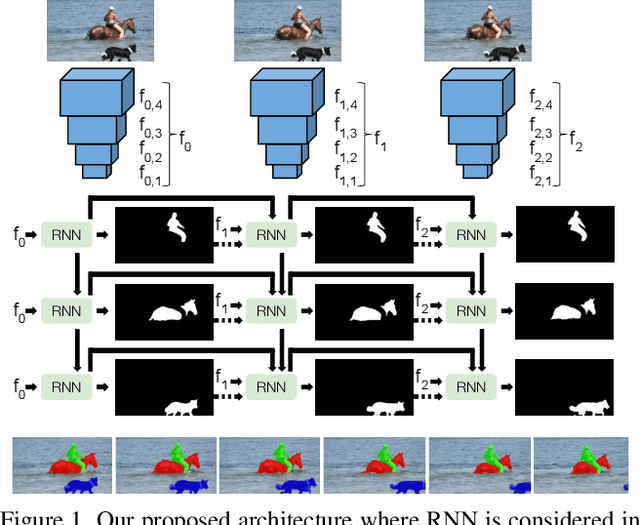
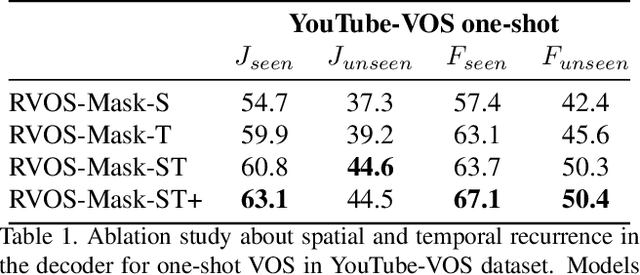
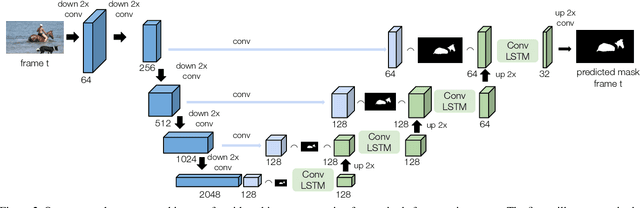
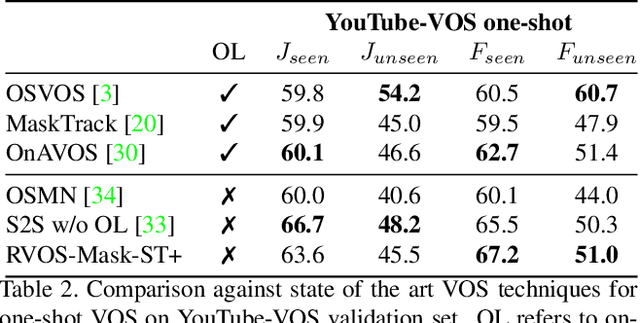
Multiple object video object segmentation is a challenging task, specially for the zero-shot case, when no object mask is given at the initial frame and the model has to find the objects to be segmented along the sequence. In our work, we propose a Recurrent network for multiple object Video Object Segmentation (RVOS) that is fully end-to-end trainable. Our model incorporates recurrence on two different domains: (i) the spatial, which allows to discover the different object instances within a frame, and (ii) the temporal, which allows to keep the coherence of the segmented objects along time. We train RVOS for zero-shot video object segmentation and are the first ones to report quantitative results for DAVIS-2017 and YouTube-VOS benchmarks. Further, we adapt RVOS for one-shot video object segmentation by using the masks obtained in previous time steps as inputs to be processed by the recurrent module. Our model reaches comparable results to state-of-the-art techniques in YouTube-VOS benchmark and outperforms all previous video object segmentation methods not using online learning in the DAVIS-2017 benchmark. Moreover, our model achieves faster inference runtimes than previous methods, reaching 44ms/frame on a P100 GPU.