 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Mar 24, 2021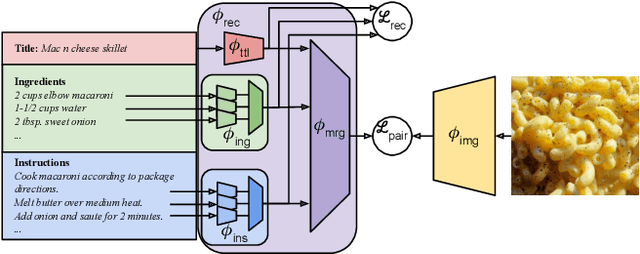
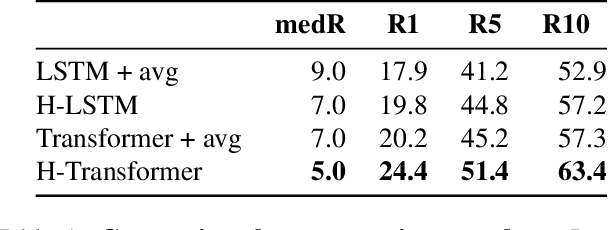

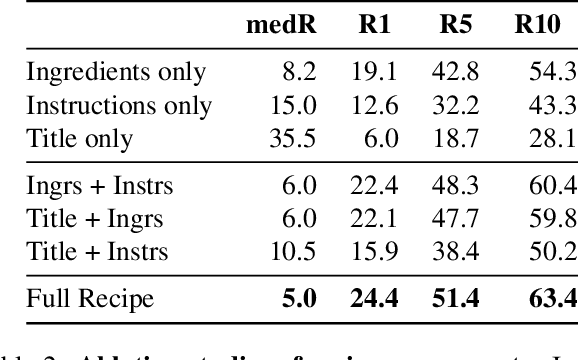
Cross-modal recipe retrieval has recently gained substantial attention due to the importance of food in people's lives, as well as the availability of vast amounts of digital cooking recipes and food images to train machine learning models. In this work, we revisit existing approaches for cross-modal recipe retrieval and propose a simplified end-to-end model based on well established and high performing encoders for text and images. We introduce a hierarchical recipe Transformer which attentively encodes individual recipe components (titles, ingredients and instructions). Further, we propose a self-supervised loss function computed on top of pairs of individual recipe components, which is able to leverage semantic relationships within recipes, and enables training using both image-recipe and recipe-only samples. We conduct a thorough analysis and ablation studies to validate our design choices. As a result, our proposed method achieves state-of-the-art performance in the cross-modal recipe retrieval task on the Recipe1M dataset. We make code and models publicly available.
Mask-guided sample selection for Semi-Supervised Instance Segmentation
Aug 25, 2020


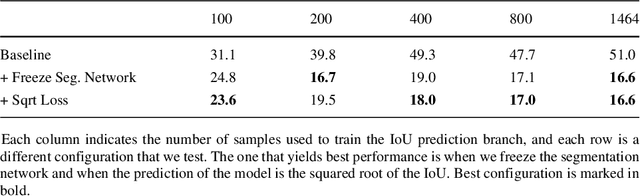
Image segmentation methods are usually trained with pixel-level annotations, which require significant human effort to collect. The most common solution to address this constraint is to implement weakly-supervised pipelines trained with lower forms of supervision, such as bounding boxes or scribbles. Another option are semi-supervised methods, which leverage a large amount of unlabeled data and a limited number of strongly-labeled samples. In this second setup, samples to be strongly-annotated can be selected randomly or with an active learning mechanism that chooses the ones that will maximize the model performance. In this work, we propose a sample selection approach to decide which samples to annotate for semi-supervised instance segmentation. Our method consists in first predicting pseudo-masks for the unlabeled pool of samples, together with a score predicting the quality of the mask. This score is an estimate of the Intersection Over Union (IoU) of the segment with the ground truth mask. We study which samples are better to annotate given the quality score, and show how our approach outperforms a random selection, leading to improved performance for semi-supervised instance segmentation with low annotation budgets.
WiCV 2019: The Sixth Women In Computer Vision Workshop
Sep 23, 2019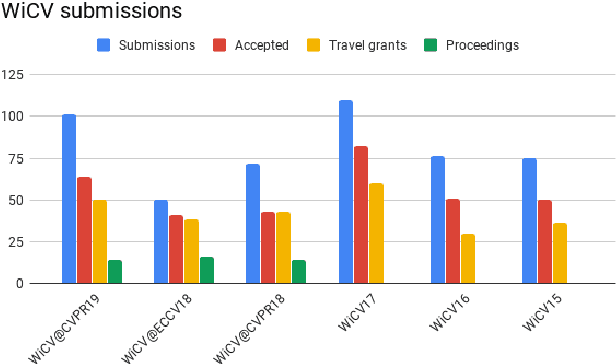
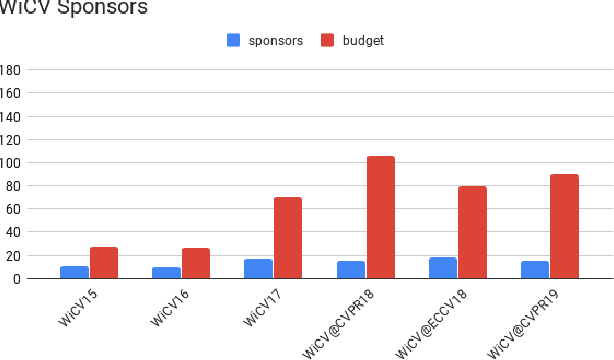
In this paper we present the Women in Computer Vision Workshop - WiCV 2019, organized in conjunction with CVPR 2019. This event is meant for increasing the visibility and inclusion of women researchers in the computer vision field. Computer vision and machine learning have made incredible progress over the past years, but the number of female researchers is still low both in academia and in industry. WiCV is organized especially for the following reason: to raise visibility of female researchers, to increase collaborations between them, and to provide mentorship to female junior researchers in the field. In this paper, we present a report of trends over the past years, along with a summary of statistics regarding presenters, attendees, and sponsorship for the current workshop.
* Report of the Sixth Women In Computer Vision Workshop
Budget-aware Semi-Supervised Semantic and Instance Segmentation
May 23, 2019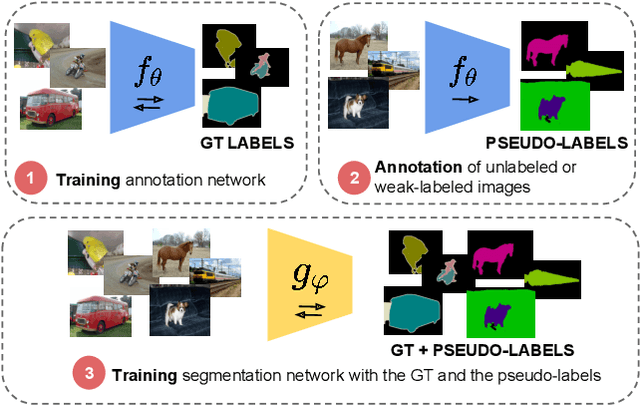


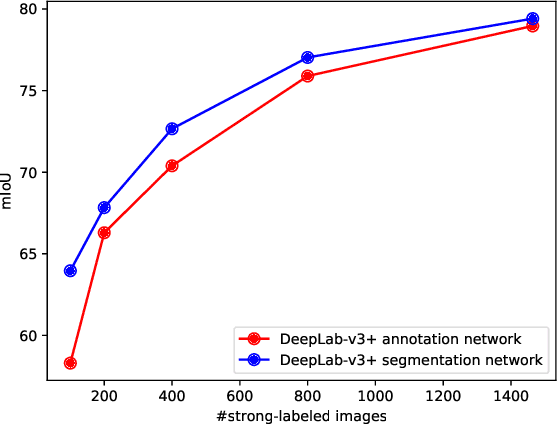
Methods that move towards less supervised scenarios are key for image segmentation, as dense labels demand significant human intervention. Generally, the annotation burden is mitigated by labeling datasets with weaker forms of supervision, e.g. image-level labels or bounding boxes. Another option are semi-supervised settings, that commonly leverage a few strong annotations and a huge number of unlabeled/weakly-labeled data. In this paper, we revisit semi-supervised segmentation schemes and narrow down significantly the annotation budget (in terms of total labeling time of the training set) compared to previous approaches. With a very simple pipeline, we demonstrate that at low annotation budgets, semi-supervised methods outperform by a wide margin weakly-supervised ones for both semantic and instance segmentation. Our approach also outperforms previous semi-supervised works at a much reduced labeling cost. We present results for the Pascal VOC benchmark and unify weakly and semi-supervised approaches by considering the total annotation budget, thus allowing a fairer comparison between methods.
Elucidating image-to-set prediction: An analysis of models, losses and datasets
Apr 11, 2019
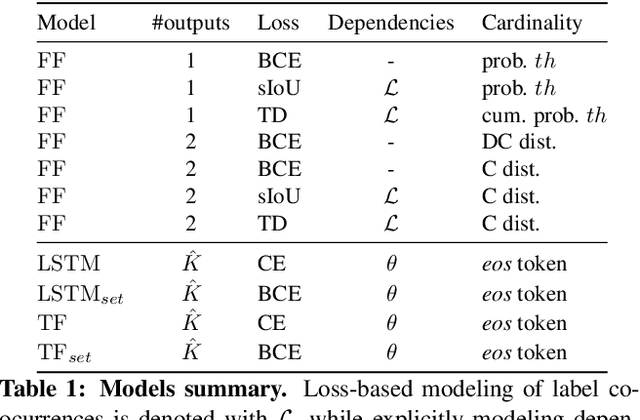
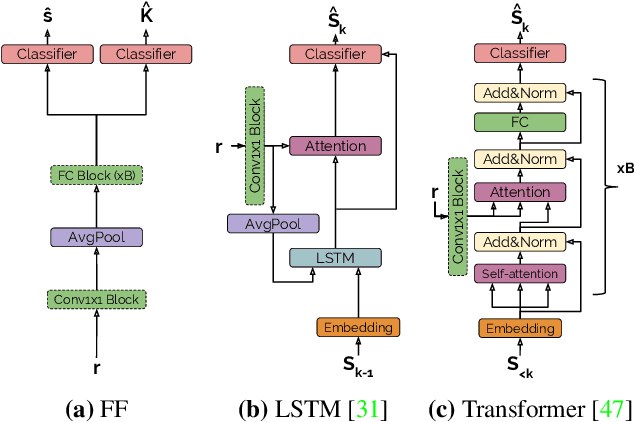

In recent years, we have experienced a flurry of contributions in the multi-label classification literature. This problem has been framed under different perspectives, from predicting independent labels, to modeling label co-occurrences via architectural and/or loss function design. Despite great progress, it is still unclear which modeling choices are best suited to address this task, partially due to the lack of well defined benchmarks. Therefore, in this paper, we provide an in-depth analysis on five different computer vision datasets of increasing task complexity that are suitable for multi-label clasification (VOC, COCO, NUS-WIDE, ADE20k and Recipe1M). Our results show that (1) modeling label co-occurrences and predicting the number of labels that appear in the image is important, especially in high-dimensional output spaces; (2) carefully tuning hyper-parameters for very simple baselines leads to significant improvements, comparable to previously reported results; and (3) as a consequence of our analysis, we achieve state-of-the-art results on 3 datasets for which a fair comparison to previously published methods is feasible.
Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
Mar 25, 2019
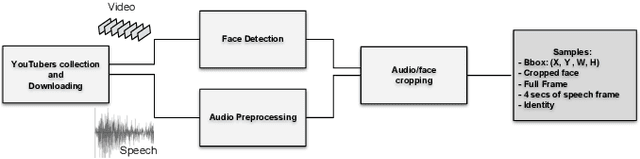


Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding). Our model is trained in a self-supervised approach by exploiting the audio and visual signals naturally aligned in videos. With the purpose of training from video data, we present a novel dataset collected for this work, with high-quality videos of youtubers with notable expressiveness in both the speech and visual signals.
RVOS: End-to-End Recurrent Network for Video Object Segmentation
Mar 13, 2019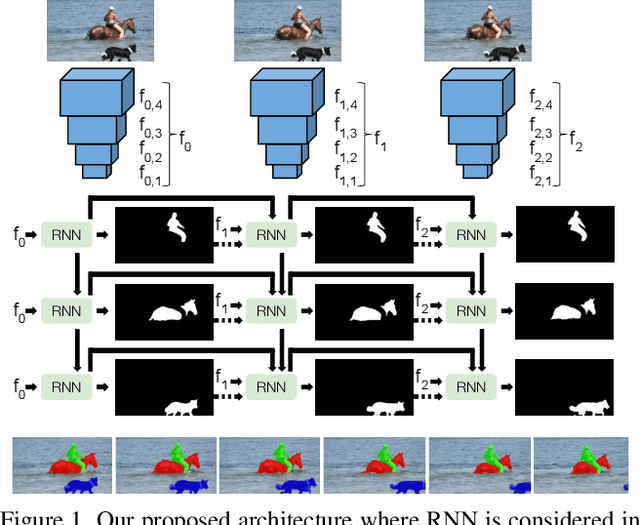
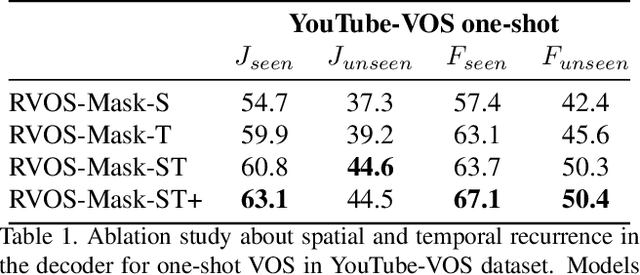
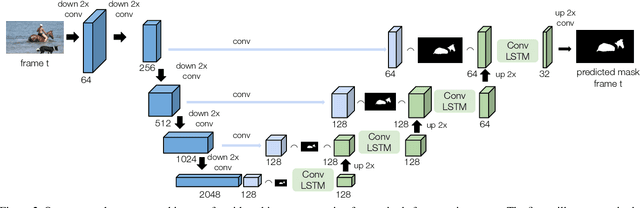
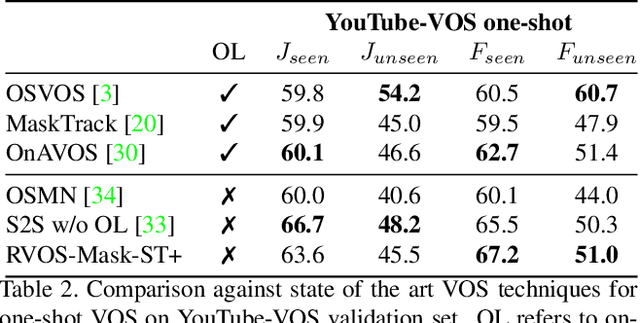
Multiple object video object segmentation is a challenging task, specially for the zero-shot case, when no object mask is given at the initial frame and the model has to find the objects to be segmented along the sequence. In our work, we propose a Recurrent network for multiple object Video Object Segmentation (RVOS) that is fully end-to-end trainable. Our model incorporates recurrence on two different domains: (i) the spatial, which allows to discover the different object instances within a frame, and (ii) the temporal, which allows to keep the coherence of the segmented objects along time. We train RVOS for zero-shot video object segmentation and are the first ones to report quantitative results for DAVIS-2017 and YouTube-VOS benchmarks. Further, we adapt RVOS for one-shot video object segmentation by using the masks obtained in previous time steps as inputs to be processed by the recurrent module. Our model reaches comparable results to state-of-the-art techniques in YouTube-VOS benchmark and outperforms all previous video object segmentation methods not using online learning in the DAVIS-2017 benchmark. Moreover, our model achieves faster inference runtimes than previous methods, reaching 44ms/frame on a P100 GPU.
Inverse Cooking: Recipe Generation from Food Images
Dec 14, 2018



People enjoy food photography because they appreciate food. Behind each meal there is a story described in a complex recipe and, unfortunately, by simply looking at a food image we do not have access to its preparation process. Therefore, in this paper we introduce an inverse cooking system that recreates cooking recipes given food images. Our system predicts ingredients as sets by means of a novel architecture, modeling their dependencies without imposing any order, and then generates cooking instructions by attending to both image and its inferred ingredients simultaneously. We extensively evaluate the whole system on the large-scale Recipe1M dataset and show that (1) we improve performance w.r.t. previous baselines for ingredient prediction; (2) we are able to obtain high quality recipes by leveraging both image and ingredients; (3) our system is able to produce more compelling recipes than retrieval-based approaches according to human judgment.
Recipe1M: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images
Oct 14, 2018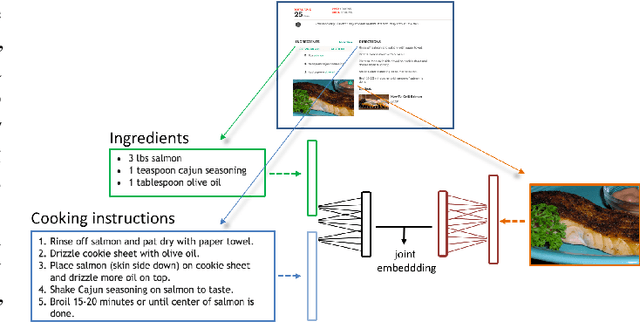
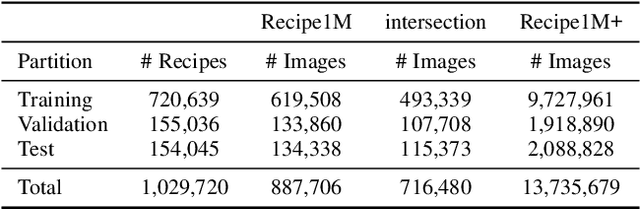

In this paper, we introduce Recipe1M, a new large-scale, structured corpus of over one million cooking recipes and 13 million food images. As the largest publicly available collection of recipe data, Recipe1M affords the ability to train high-capacity models on aligned, multi-modal data. Using these data, we train a neural network to learn a joint embedding of recipes and images that yields impressive results on an image-recipe retrieval task. Moreover, we demonstrate that regularization via the addition of a high-level classification objective both improves retrieval performance to rival that of humans and enables semantic vector arithmetic. We postulate that these embeddings will provide a basis for further exploration of the Recipe1M dataset and food and cooking in general. Code, data and models are publicly available.
Recurrent Neural Networks for Semantic Instance Segmentation
Sep 03, 2018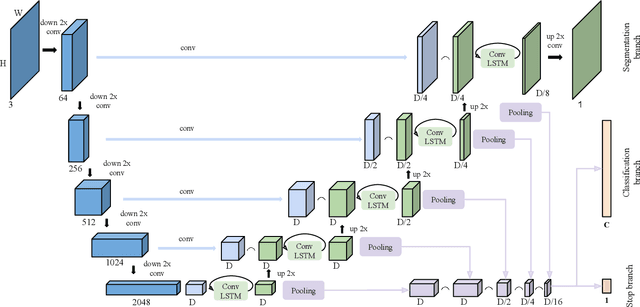

We present a recurrent model for semantic instance segmentation that sequentially generates binary masks and their associated class probabilities for every object in an image. Our proposed system is trainable end-to-end from an input image to a sequence of labeled masks and, compared to methods relying on object proposals, does not require post-processing steps on its output. We study the suitability of our recurrent model on three different instance segmentation benchmarks, namely Pascal VOC 2012, CVPPP Plant Leaf Segmentation and Cityscapes. Further, we analyze the object sorting patterns generated by our model and observe that it learns to follow a consistent pattern, which correlates with the activations learned in the encoder part of our network. Source code and models are available at https://imatge-upc.github.io/rsis/