 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating image-to-set prediction: An analysis of models, losses and datasets
Paper and Code

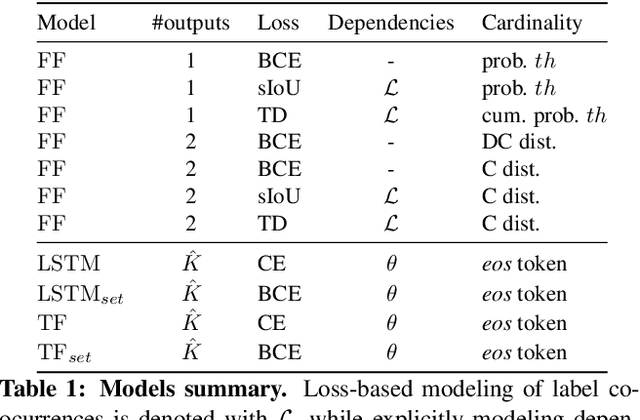
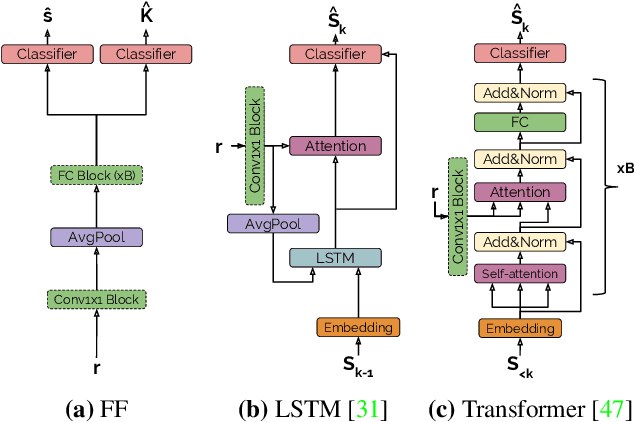

In recent years, we have experienced a flurry of contributions in the multi-label classification literature. This problem has been framed under different perspectives, from predicting independent labels, to modeling label co-occurrences via architectural and/or loss function design. Despite great progress, it is still unclear which modeling choices are best suited to address this task, partially due to the lack of well defined benchmarks. Therefore, in this paper, we provide an in-depth analysis on five different computer vision datasets of increasing task complexity that are suitable for multi-label clasification (VOC, COCO, NUS-WIDE, ADE20k and Recipe1M). Our results show that (1) modeling label co-occurrences and predicting the number of labels that appear in the image is important, especially in high-dimensional output spaces; (2) carefully tuning hyper-parameters for very simple baselines leads to significant improvements, comparable to previously reported results; and (3) as a consequence of our analysis, we achieve state-of-the-art results on 3 datasets for which a fair comparison to previously published methods is feasible.