 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reward Was in Your Data All Along: Correcting Flow Matching with Discriminator-Guided RL
Jun 17, 2026Score- and flow-matching models often rely on preference-based reinforcement learning for two purposes: aligning with subjective preferences and, surprisingly, recovering properties such as visual realism and coherent object structure that matching-based training is intended to learn from the data itself. We argue that this reflects a structural mismatch. Matching losses measure $\ell_2$ regression error on the velocity or score field under training-time marginals, a proxy poorly aligned with the visual and semantic properties that determine sample quality at inference. Given a reward aligned with these properties, RL sidesteps the mismatch by evaluating the model on its own samples and following the reward landscape directly. The challenge is to obtain such a reward without relying on human preferences, which are expensive and conflate data realism with annotator inclinations. We propose Discriminator-Guided RL (DRL). DRL trains a discriminator to separate data from base-model samples in a pretrained representation space and uses its logit as the reward in KL-regularized RL. The pretrained space restricts the discriminator to perceptually meaningful directions, and the logit estimates the log-likelihood ratio between data and model, which is the optimal reward for targeting the data distribution. Across SiT, JiT, REPA, and RAE, DRL reduces guidance-free FID (e.g., $9.38 \to 2.62$ on SiT) and semantic-space FD (e.g., $88.2 \to 19.3$ on DINOv3 for SiT), with consistent gains across all backbones, and improves human-preference rewards without training on them. It also yields a better Pareto frontier between preference reward and image fidelity under subsequent preference-based post-training, increasing alignment while reducing low-level artifacts such as oversaturation and excessive brightness.
PGT: Procedurally Generated Tasks for improving visual grounding in MLLMs
May 22, 2026Despite remarkable progress in Multimodal Large Language Models (MLLMs), these models still struggle with fine-grained understanding tasks. In this work, we propose Procedurally Generated Tasks (PGT), a simple data-driven framework that serves a dual purpose: inducing fine-grained visual understanding and acting as a low-cost diagnostic tool to identify the source of perception failures. By overlaying unambiguous geometric primitives on images, PGT generate additional dense supervision that disentangles visual grounding capability from semantic priors. Extensive experiments on relational, quantitative, and 3D/depth understanding benchmarks show that PGT yields remarkable gains across diverse architectures. Instruction tuning MLLMs on LLaVA-v1.5-Instruct augmented with PGT data results in improvements of up to +20% on the What'sUp benchmark and +13.3% on CV-Bench-2D, while maintaining general perception capabilities. Moreover, finetuning state-of-the-art MLLMs on PGT data leads to boosts of up to +5.5% on What'sUp and +8.3% on CV-Bench-2D. These findings demonstrate that PGT effectively address the bottleneck of fine-grained perception, revealing that many spatial reasoning deficits stem from inadequate supervision signals rather than inherent architectural or resolution limitations.
GASS: Geometry-Aware Spherical Sampling for Disentangled Diversity Enhancement in Text-to-Image Generation
Feb 19, 2026Despite high semantic alignment, modern text-to-image (T2I) generative models still struggle to synthesize diverse images from a given prompt. This lack of diversity not only restricts user choice, but also risks amplifying societal biases. In this work, we enhance the T2I diversity through a geometric lens. Unlike most existing methods that rely primarily on entropy-based guidance to increase sample dissimilarity, we introduce Geometry-Aware Spherical Sampling (GASS) to enhance diversity by explicitly controlling both prompt-dependent and prompt-independent sources of variation. Specifically, we decompose the diversity measure in CLIP embeddings using two orthogonal directions: the text embedding, which captures semantic variation related to the prompt, and an identified orthogonal direction that captures prompt-independent variation (e.g., backgrounds). Based on this decomposition, GASS increases the geometric projection spread of generated image embeddings along both axes and guides the T2I sampling process via expanded predictions along the generation trajectory. Our experiments on different frozen T2I backbones (U-Net and DiT, diffusion and flow) and benchmarks demonstrate the effectiveness of disentangled diversity enhancement with minimal impact on image fidelity and semantic alignment.
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
Multi-Modal Language Models as Text-to-Image Model Evaluators
May 01, 2025The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.
Entropy Rectifying Guidance for Diffusion and Flow Models
Apr 18, 2025Guidance techniques are commonly used in diffusion and flow models to improve image quality and consistency for conditional generative tasks such as class-conditional and text-to-image generation. In particular, classifier-free guidance (CFG) -- the most widely adopted guidance technique -- contrasts conditional and unconditional predictions to improve the generated images. This results, however, in trade-offs across quality, diversity and consistency, improving some at the expense of others. While recent work has shown that it is possible to disentangle these factors to some extent, such methods come with an overhead of requiring an additional (weaker) model, or require more forward passes per sampling step. In this paper, we propose Entropy Rectifying Guidance (ERG), a simple and effective guidance mechanism based on inference-time changes in the attention mechanism of state-of-the-art diffusion transformer architectures, which allows for simultaneous improvements over image quality, diversity and prompt consistency. ERG is more general than CFG and similar guidance techniques, as it extends to unconditional sampling. ERG results in significant improvements in various generation tasks such as text-to-image, class-conditional and unconditional image generation. We also show that ERG can be seamlessly combined with other recent guidance methods such as CADS and APG, further boosting generation performance.
Improving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025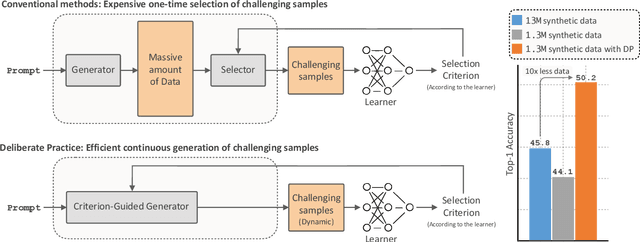
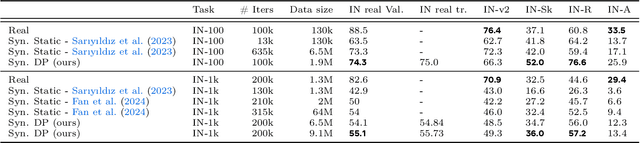
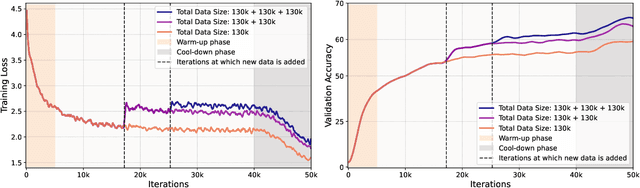

Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
Object-centric Binding in Contrastive Language-Image Pretraining
Feb 19, 2025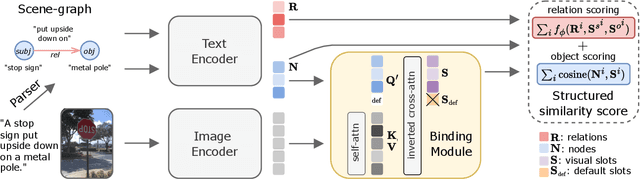
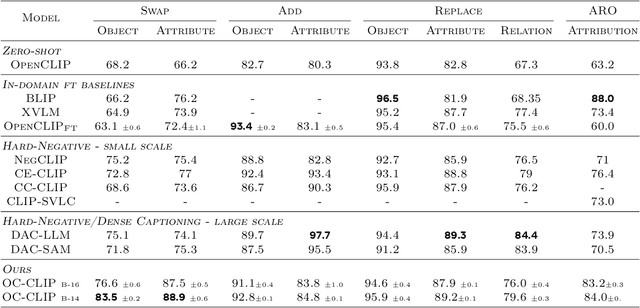
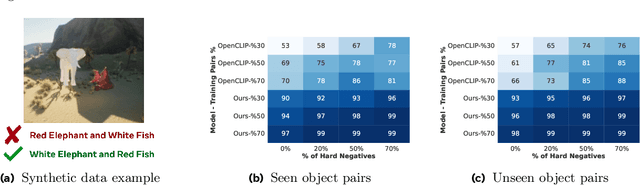
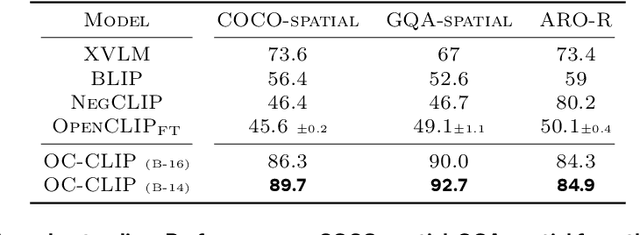
Recent advances in vision language models (VLM) have been driven by contrastive models such as CLIP, which learn to associate visual information with their corresponding text descriptions. However, these models have limitations in understanding complex compositional scenes involving multiple objects and their spatial relationships. To address these challenges, we propose a novel approach that diverges from commonly used strategies, which rely on the design of hard-negative augmentations. Instead, our work focuses on integrating inductive biases into pre-trained CLIP-like models to improve their compositional understanding without using any additional hard-negatives. To that end, we introduce a binding module that connects a scene graph, derived from a text description, with a slot-structured image representation, facilitating a structured similarity assessment between the two modalities. We also leverage relationships as text-conditioned visual constraints, thereby capturing the intricate interactions between objects and their contextual relationships more effectively. Our resulting model not only enhances the performance of CLIP-based models in multi-object compositional understanding but also paves the way towards more accurate and sample-efficient image-text matching of complex scenes.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.