 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeg to Differ: Understanding Reasoning-Answer Misalignment Across Languages
Dec 27, 2025Large language models demonstrate strong reasoning capabilities through chain-of-thought prompting, but whether this reasoning quality transfers across languages remains underexplored. We introduce a human-validated framework to evaluate whether model-generated reasoning traces logically support their conclusions across languages. Analyzing 65k reasoning traces from GlobalMMLU questions across 6 languages and 6 frontier models, we uncover a critical blind spot: while models achieve high task accuracy, their reasoning can fail to support their conclusions. Reasoning traces in non-Latin scripts show at least twice as much misalignment between their reasoning and conclusions than those in Latin scripts. We develop an error taxonomy through human annotation to characterize these failures, finding they stem primarily from evidential errors (unsupported claims, ambiguous facts) followed by illogical reasoning steps. Our findings demonstrate that current multilingual evaluation practices provide an incomplete picture of model reasoning capabilities and highlight the need for reasoning-aware evaluation frameworks.
Cross-Tokenizer Likelihood Scoring Algorithms for Language Model Distillation
Dec 16, 2025Computing next-token likelihood ratios between two language models (LMs) is a standard task in training paradigms such as knowledge distillation. Since this requires both models to share the same probability space, it becomes challenging when the teacher and student LMs use different tokenizers, for instance, when edge-device deployment necessitates a smaller vocabulary size to lower memory overhead. In this work, we address this vocabulary misalignment problem by uncovering an implicit recursive structure in the commonly deployed Byte-Pair Encoding (BPE) algorithm and utilizing it to create a probabilistic framework for cross-tokenizer likelihood scoring. Our method enables sequence likelihood evaluation for vocabularies different from the teacher model native tokenizer, addressing two specific scenarios: when the student vocabulary is a subset of the teacher vocabulary, and the general case where it is arbitrary. In the subset regime, our framework computes exact likelihoods and provides next-token probabilities for sequential sampling with only O(1) model evaluations per token. When used for distillation, this yields up to a 12% reduction in memory footprint for the Qwen2.5-1.5B model while also improving baseline performance up to 4% on the evaluated tasks. For the general case, we introduce a rigorous lossless procedure that leverages BPE recursive structure, complemented by a fast approximation that keeps large-vocabulary settings practical. Applied to distillation for mathematical reasoning, our approach improves GSM8K accuracy by more than 2% over the current state of the art.
DIMCIM: A Quantitative Evaluation Framework for Default-mode Diversity and Generalization in Text-to-Image Generative Models
Jun 05, 2025Recent advances in text-to-image (T2I) models have achieved impressive quality and consistency. However, this has come at the cost of representation diversity. While automatic evaluation methods exist for benchmarking model diversity, they either require reference image datasets or lack specificity about the kind of diversity measured, limiting their adaptability and interpretability. To address this gap, we introduce the Does-it/Can-it framework, DIM-CIM, a reference-free measurement of default-mode diversity ("Does" the model generate images with expected attributes?) and generalization capacity ("Can" the model generate diverse attributes for a particular concept?). We construct the COCO-DIMCIM benchmark, which is seeded with COCO concepts and captions and augmented by a large language model. With COCO-DIMCIM, we find that widely-used models improve in generalization at the cost of default-mode diversity when scaling from 1.5B to 8.1B parameters. DIMCIM also identifies fine-grained failure cases, such as attributes that are generated with generic prompts but are rarely generated when explicitly requested. Finally, we use DIMCIM to evaluate the training data of a T2I model and observe a correlation of 0.85 between diversity in training images and default-mode diversity. Our work provides a flexible and interpretable framework for assessing T2I model diversity and generalization, enabling a more comprehensive understanding of model performance.
Aligned Multi Objective Optimization
Feb 19, 2025To date, the multi-objective optimization literature has mainly focused on conflicting objectives, studying the Pareto front, or requiring users to balance tradeoffs. Yet, in machine learning practice, there are many scenarios where such conflict does not take place. Recent findings from multi-task learning, reinforcement learning, and LLMs training show that diverse related tasks can enhance performance across objectives simultaneously. Despite this evidence, such phenomenon has not been examined from an optimization perspective. This leads to a lack of generic gradient-based methods that can scale to scenarios with a large number of related objectives. To address this gap, we introduce the Aligned Multi-Objective Optimization framework, propose new algorithms for this setting, and provide theoretical guarantees of their superior performance compared to naive approaches.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
Oct 11, 2024



Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as "tokenization bias''. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.
Mission Impossible: A Statistical Perspective on Jailbreaking LLMs
Aug 02, 2024Large language models (LLMs) are trained on a deluge of text data with limited quality control. As a result, LLMs can exhibit unintended or even harmful behaviours, such as leaking information, fake news or hate speech. Countermeasures, commonly referred to as preference alignment, include fine-tuning the pretrained LLMs with carefully crafted text examples of desired behaviour. Even then, empirical evidence shows preference aligned LLMs can be enticed to harmful behaviour. This so called jailbreaking of LLMs is typically achieved by adversarially modifying the input prompt to the LLM. Our paper provides theoretical insights into the phenomenon of preference alignment and jailbreaking from a statistical perspective. Under our framework, we first show that pretrained LLMs will mimic harmful behaviour if present in the training corpus. Under that same framework, we then introduce a statistical notion of alignment, and lower-bound the jailbreaking probability, showing that it is unpreventable under reasonable assumptions. Based on our insights, we propose an alteration to the currently prevalent alignment strategy RLHF. Specifically, we introduce a simple modification to the RLHF objective, we call E-RLHF, that aims to increase the likelihood of safe responses. E-RLHF brings no additional training cost, and is compatible with other methods. Empirically, we demonstrate that E-RLHF outperforms RLHF on all alignment problems put forward by the AdvBench and HarmBench project without sacrificing model performance as measured by the MT-Bench project.
End-To-End Causal Effect Estimation from Unstructured Natural Language Data
Jul 09, 2024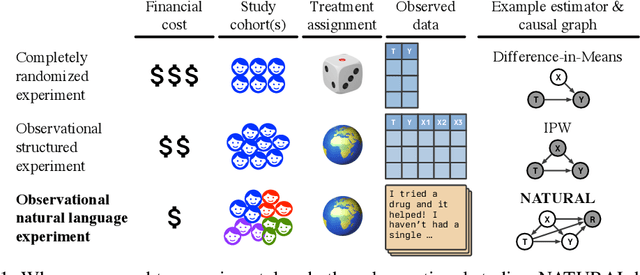
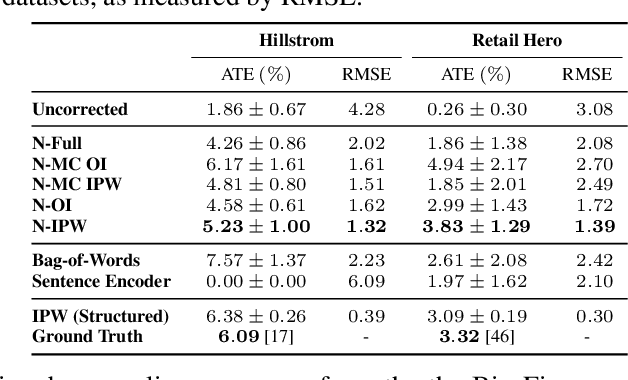
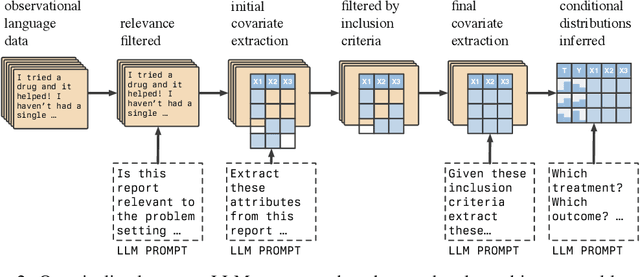

Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce NATURAL, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
Understanding and Mitigating Tokenization Bias in Language Models
Jun 24, 2024


State-of-the-art language models are autoregressive and operate on subword units known as tokens. Specifically, one must encode the conditioning string into a list of tokens before passing to the language models for next-token prediction. We show that, for encoding schemes such as maximum prefix matching, tokenization induces a sampling bias that cannot be mitigated with more training or data. To counter this universal problem, we propose a novel algorithm to obtain unbiased estimates from a model that was trained on tokenized data. Our method does not require finetuning the model, and its complexity, defined as the number of model runs, scales linearly with the sequence length. As a consequence, we show that one can simulate token-free behavior from a tokenized language model. We empirically verify the correctness of our method through a Markov-chain setup, where it accurately recovers the transition probabilities, as opposed to the conventional method of directly prompting tokens into the language model.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.