 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMission Impossible: A Statistical Perspective on Jailbreaking LLMs
Aug 02, 2024Large language models (LLMs) are trained on a deluge of text data with limited quality control. As a result, LLMs can exhibit unintended or even harmful behaviours, such as leaking information, fake news or hate speech. Countermeasures, commonly referred to as preference alignment, include fine-tuning the pretrained LLMs with carefully crafted text examples of desired behaviour. Even then, empirical evidence shows preference aligned LLMs can be enticed to harmful behaviour. This so called jailbreaking of LLMs is typically achieved by adversarially modifying the input prompt to the LLM. Our paper provides theoretical insights into the phenomenon of preference alignment and jailbreaking from a statistical perspective. Under our framework, we first show that pretrained LLMs will mimic harmful behaviour if present in the training corpus. Under that same framework, we then introduce a statistical notion of alignment, and lower-bound the jailbreaking probability, showing that it is unpreventable under reasonable assumptions. Based on our insights, we propose an alteration to the currently prevalent alignment strategy RLHF. Specifically, we introduce a simple modification to the RLHF objective, we call E-RLHF, that aims to increase the likelihood of safe responses. E-RLHF brings no additional training cost, and is compatible with other methods. Empirically, we demonstrate that E-RLHF outperforms RLHF on all alignment problems put forward by the AdvBench and HarmBench project without sacrificing model performance as measured by the MT-Bench project.
On the Robustness of Neural Collapse and the Neural Collapse of Robustness
Nov 13, 2023Neural Collapse refers to the curious phenomenon in the end of training of a neural network, where feature vectors and classification weights converge to a very simple geometrical arrangement (a simplex). While it has been observed empirically in various cases and has been theoretically motivated, its connection with crucial properties of neural networks, like their generalization and robustness, remains unclear. In this work, we study the stability properties of these simplices. We find that the simplex structure disappears under small adversarial attacks, and that perturbed examples "leap" between simplex vertices. We further analyze the geometry of networks that are optimized to be robust against adversarial perturbations of the input, and find that Neural Collapse is a pervasive phenomenon in these cases as well, with clean and perturbed representations forming aligned simplices, and giving rise to a robust simple nearest-neighbor classifier. By studying the propagation of the amount of collapse inside the network, we identify novel properties of both robust and non-robust machine learning models, and show that earlier, unlike later layers maintain reliable simplices on perturbed data.
Wavelets Beat Monkeys at Adversarial Robustness
Apr 19, 2023Research on improving the robustness of neural networks to adversarial noise - imperceptible malicious perturbations of the data - has received significant attention. The currently uncontested state-of-the-art defense to obtain robust deep neural networks is Adversarial Training (AT), but it consumes significantly more resources compared to standard training and trades off accuracy for robustness. An inspiring recent work [Dapello et al.] aims to bring neurobiological tools to the question: How can we develop Neural Nets that robustly generalize like human vision? [Dapello et al.] design a network structure with a neural hidden first layer that mimics the primate primary visual cortex (V1), followed by a back-end structure adapted from current CNN vision models. It seems to achieve non-trivial adversarial robustness on standard vision benchmarks when tested on small perturbations. Here we revisit this biologically inspired work, and ask whether a principled parameter-free representation with inspiration from physics is able to achieve the same goal. We discover that the wavelet scattering transform can replace the complex V1-cortex and simple uniform Gaussian noise can take the role of neural stochasticity, to achieve adversarial robustness. In extensive experiments on the CIFAR-10 benchmark with adaptive adversarial attacks we show that: 1) Robustness of VOneBlock architectures is relatively weak (though non-zero) when the strength of the adversarial attack radius is set to commonly used benchmarks. 2) Replacing the front-end VOneBlock by an off-the-shelf parameter-free Scatternet followed by simple uniform Gaussian noise can achieve much more substantial adversarial robustness without adversarial training. Our work shows how physically inspired structures yield new insights into robustness that were previously only thought possible by meticulously mimicking the human cortex.
On the Connection between Invariant Learning and Adversarial Training for Out-of-Distribution Generalization
Dec 18, 2022Despite impressive success in many tasks, deep learning models are shown to rely on spurious features, which will catastrophically fail when generalized to out-of-distribution (OOD) data. Invariant Risk Minimization (IRM) is proposed to alleviate this issue by extracting domain-invariant features for OOD generalization. Nevertheless, recent work shows that IRM is only effective for a certain type of distribution shift (e.g., correlation shift) while it fails for other cases (e.g., diversity shift). Meanwhile, another thread of method, Adversarial Training (AT), has shown better domain transfer performance, suggesting that it has the potential to be an effective candidate for extracting domain-invariant features. This paper investigates this possibility by exploring the similarity between the IRM and AT objectives. Inspired by this connection, we propose Domainwise Adversarial Training (DAT), an AT-inspired method for alleviating distribution shift by domain-specific perturbations. Extensive experiments show that our proposed DAT can effectively remove domain-varying features and improve OOD generalization under both correlation shift and diversity shift.
Can we achieve robustness from data alone?
Jul 24, 2022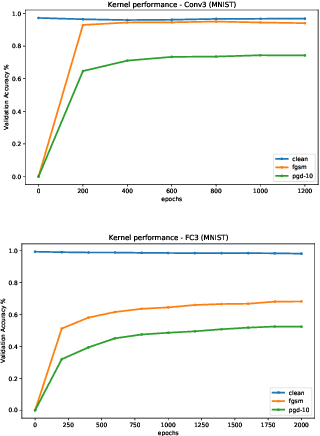
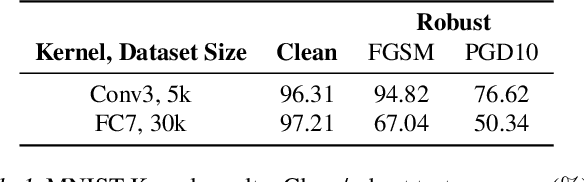


Adversarial training and its variants have come to be the prevailing methods to achieve adversarially robust classification using neural networks. However, its increased computational cost together with the significant gap between standard and robust performance hinder progress and beg the question of whether we can do better. In this work, we take a step back and ask: Can models achieve robustness via standard training on a suitably optimized set? To this end, we devise a meta-learning method for robust classification, that optimizes the dataset prior to its deployment in a principled way, and aims to effectively remove the non-robust parts of the data. We cast our optimization method as a multi-step PGD procedure on kernel regression, with a class of kernels that describe infinitely wide neural nets (Neural Tangent Kernels - NTKs). Experiments on MNIST and CIFAR-10 demonstrate that the datasets we produce enjoy very high robustness against PGD attacks, when deployed in both kernel regression classifiers and neural networks. However, this robustness is somewhat fallacious, as alternative attacks manage to fool the models, which we find to be the case for previous similar works in the literature as well. We discuss potential reasons for this and outline further avenues of research.
Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot
Sep 22, 2020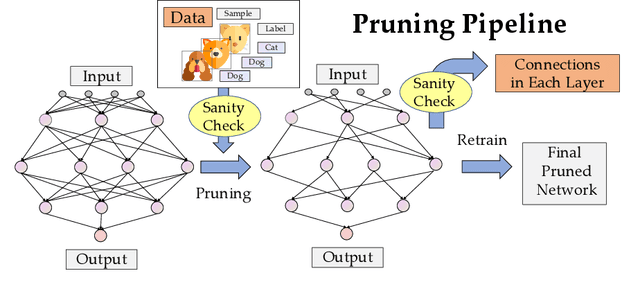
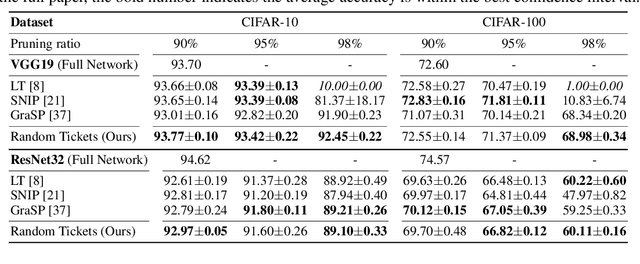
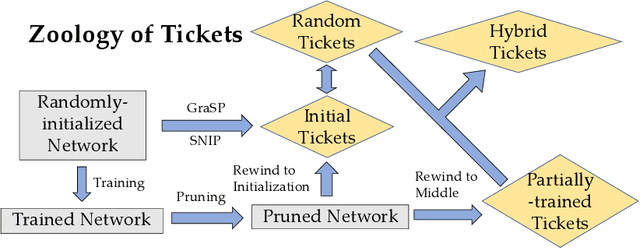
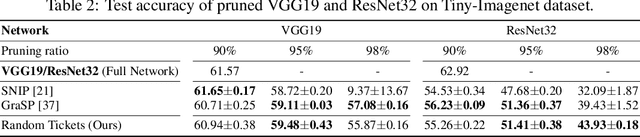
Network pruning is a method for reducing test-time computational resource requirements with minimal performance degradation. Conventional wisdom of pruning algorithms suggests that: (1) Pruning methods exploit information from training data to find good subnetworks; (2) The architecture of the pruned network is crucial for good performance. In this paper, we conduct sanity checks for the above beliefs on several recent unstructured pruning methods and surprisingly find that: (1) A set of methods which aims to find good subnetworks of the randomly-initialized network (which we call "initial tickets"), hardly exploits any information from the training data; (2) For the pruned networks obtained by these methods, randomly changing the preserved weights in each layer, while keeping the total number of preserved weights unchanged per layer, does not affect the final performance. These findings inspire us to choose a series of simple \emph{data-independent} prune ratios for each layer, and randomly prune each layer accordingly to get a subnetwork (which we call "random tickets"). Experimental results show that our zero-shot random tickets outperforms or attains similar performance compared to existing "initial tickets". In addition, we identify one existing pruning method that passes our sanity checks. We hybridize the ratios in our random ticket with this method and propose a new method called "hybrid tickets", which achieves further improvement.