 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we achieve robustness from data alone?
Paper and Code
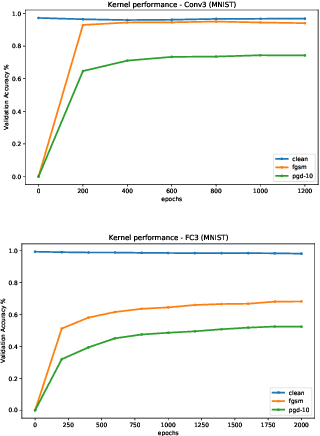
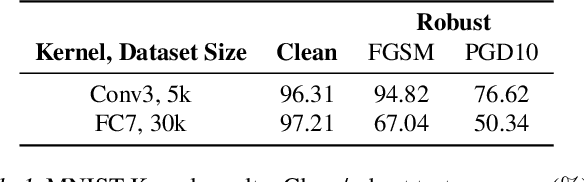


Adversarial training and its variants have come to be the prevailing methods to achieve adversarially robust classification using neural networks. However, its increased computational cost together with the significant gap between standard and robust performance hinder progress and beg the question of whether we can do better. In this work, we take a step back and ask: Can models achieve robustness via standard training on a suitably optimized set? To this end, we devise a meta-learning method for robust classification, that optimizes the dataset prior to its deployment in a principled way, and aims to effectively remove the non-robust parts of the data. We cast our optimization method as a multi-step PGD procedure on kernel regression, with a class of kernels that describe infinitely wide neural nets (Neural Tangent Kernels - NTKs). Experiments on MNIST and CIFAR-10 demonstrate that the datasets we produce enjoy very high robustness against PGD attacks, when deployed in both kernel regression classifiers and neural networks. However, this robustness is somewhat fallacious, as alternative attacks manage to fool the models, which we find to be the case for previous similar works in the literature as well. We discuss potential reasons for this and outline further avenues of research.