 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Mar 04, 2026Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π^3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.
VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Dec 17, 2025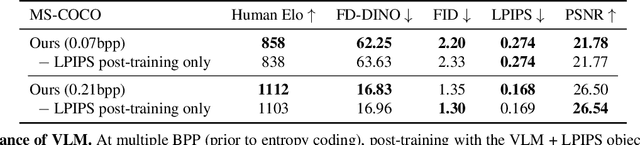

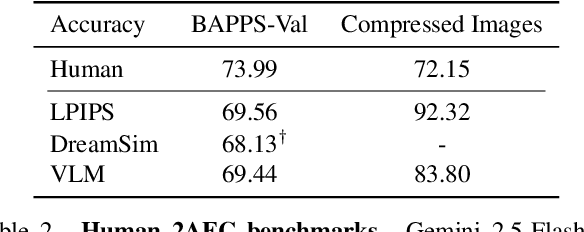
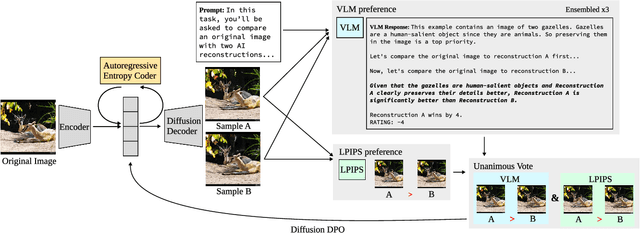
Evaluations of image compression performance which include human preferences have generally found that naive distortion functions such as MSE are insufficiently aligned to human perception. In order to align compression models to human perception, prior work has employed differentiable perceptual losses consisting of neural networks calibrated on large-scale datasets of human psycho-visual judgments. We show that, surprisingly, state-of-the-art vision-language models (VLMs) can replicate binary human two-alternative forced choice (2AFC) judgments zero-shot when asked to reason about the differences between pairs of images. Motivated to exploit the powerful zero-shot visual reasoning capabilities of VLMs, we propose Vision-Language Models for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments. VLIC leverages existing techniques for diffusion model post-training with preferences, rather than distilling the VLM judgments into a separate perceptual loss network. We show that calibrating this system on VLM judgments produces competitive or state-of-the-art performance on human-aligned visual compression depending on the dataset, according to perceptual metrics and large-scale user studies. We additionally conduct an extensive analysis of the VLM-based reward design and training procedure and share important insights. More visuals are available at https://kylesargent.github.io/vlic
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
SceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
Bolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024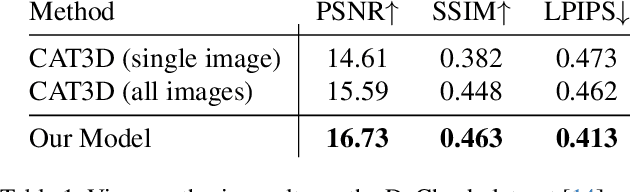



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
Nov 27, 2024



We present CAT4D, a method for creating 4D (dynamic 3D) scenes from monocular video. CAT4D leverages a multi-view video diffusion model trained on a diverse combination of datasets to enable novel view synthesis at any specified camera poses and timestamps. Combined with a novel sampling approach, this model can transform a single monocular video into a multi-view video, enabling robust 4D reconstruction via optimization of a deformable 3D Gaussian representation. We demonstrate competitive performance on novel view synthesis and dynamic scene reconstruction benchmarks, and highlight the creative capabilities for 4D scene generation from real or generated videos. See our project page for results and interactive demos: \url{cat-4d.github.io}.
Simpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion
Oct 25, 2024



Latent diffusion models have become the popular choice for scaling up diffusion models for high resolution image synthesis. Compared to pixel-space models that are trained end-to-end, latent models are perceived to be more efficient and to produce higher image quality at high resolution. Here we challenge these notions, and show that pixel-space models can in fact be very competitive to latent approaches both in quality and efficiency, achieving 1.5 FID on ImageNet512 and new SOTA results on ImageNet128 and ImageNet256. We present a simple recipe for scaling end-to-end pixel-space diffusion models to high resolutions. 1: Use the sigmoid loss (Kingma & Gao, 2023) with our prescribed hyper-parameters. 2: Use our simplified memory-efficient architecture with fewer skip-connections. 3: Scale the model to favor processing the image at high resolution with fewer parameters, rather than using more parameters but at a lower resolution. When combining these three steps with recently proposed tricks like guidance intervals, we obtain a family of pixel-space diffusion models we call Simple Diffusion v2 (SiD2).
Think Twice Before You Act: Improving Inverse Problem Solving With MCMC
Sep 13, 2024Recent studies demonstrate that diffusion models can serve as a strong prior for solving inverse problems. A prominent example is Diffusion Posterior Sampling (DPS), which approximates the posterior distribution of data given the measure using Tweedie's formula. Despite the merits of being versatile in solving various inverse problems without re-training, the performance of DPS is hindered by the fact that this posterior approximation can be inaccurate especially for high noise levels. Therefore, we propose \textbf{D}iffusion \textbf{P}osterior \textbf{MC}MC (\textbf{DPMC}), a novel inference algorithm based on Annealed MCMC to solve inverse problems with pretrained diffusion models. We define a series of intermediate distributions inspired by the approximated conditional distributions used by DPS. Through annealed MCMC sampling, we encourage the samples to follow each intermediate distribution more closely before moving to the next distribution at a lower noise level, and therefore reduce the accumulated error along the path. We test our algorithm in various inverse problems, including super resolution, Gaussian deblurring, motion deblurring, inpainting, and phase retrieval. Our algorithm outperforms DPS with less number of evaluations across nearly all tasks, and is competitive among existing approaches.
Generative Hierarchical Materials Search
Sep 10, 2024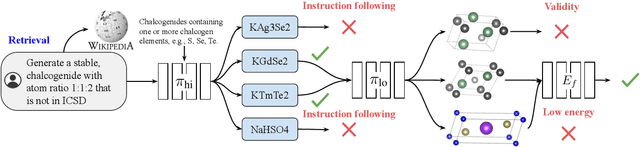



Generative models trained at scale can now produce text, video, and more recently, scientific data such as crystal structures. In applications of generative approaches to materials science, and in particular to crystal structures, the guidance from the domain expert in the form of high-level instructions can be essential for an automated system to output candidate crystals that are viable for downstream research. In this work, we formulate end-to-end language-to-structure generation as a multi-objective optimization problem, and propose Generative Hierarchical Materials Search (GenMS) for controllable generation of crystal structures. GenMS consists of (1) a language model that takes high-level natural language as input and generates intermediate textual information about a crystal (e.g., chemical formulae), and (2) a diffusion model that takes intermediate information as input and generates low-level continuous value crystal structures. GenMS additionally uses a graph neural network to predict properties (e.g., formation energy) from the generated crystal structures. During inference, GenMS leverages all three components to conduct a forward tree search over the space of possible structures. Experiments show that GenMS outperforms other alternatives of directly using language models to generate structures both in satisfying user request and in generating low-energy structures. We confirm that GenMS is able to generate common crystal structures such as double perovskites, or spinels, solely from natural language input, and hence can form the foundation for more complex structure generation in near future.