 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
Path-RAG: Knowledge-Guided Key Region Retrieval for Open-ended Pathology Visual Question Answering
Nov 26, 2024



Accurate diagnosis and prognosis assisted by pathology images are essential for cancer treatment selection and planning. Despite the recent trend of adopting deep-learning approaches for analyzing complex pathology images, they fall short as they often overlook the domain-expert understanding of tissue structure and cell composition. In this work, we focus on a challenging Open-ended Pathology VQA (PathVQA-Open) task and propose a novel framework named Path-RAG, which leverages HistoCartography to retrieve relevant domain knowledge from pathology images and significantly improves performance on PathVQA-Open. Admitting the complexity of pathology image analysis, Path-RAG adopts a human-centered AI approach by retrieving domain knowledge using HistoCartography to select the relevant patches from pathology images. Our experiments suggest that domain guidance can significantly boost the accuracy of LLaVA-Med from 38% to 47%, with a notable gain of 28% for H&E-stained pathology images in the PathVQA-Open dataset. For longer-form question and answer pairs, our model consistently achieves significant improvements of 32.5% in ARCH-Open PubMed and 30.6% in ARCH-Open Books on H\&E images. Our code and dataset is available here (https://github.com/embedded-robotics/path-rag).
Subjective and Objective Quality-of-Experience Evaluation Study for Live Video Streaming
Sep 26, 2024



In recent years, live video streaming has gained widespread popularity across various social media platforms. Quality of experience (QoE), which reflects end-users' satisfaction and overall experience, plays a critical role for media service providers to optimize large-scale live compression and transmission strategies to achieve perceptually optimal rate-distortion trade-off. Although many QoE metrics for video-on-demand (VoD) have been proposed, there remain significant challenges in developing QoE metrics for live video streaming. To bridge this gap, we conduct a comprehensive study of subjective and objective QoE evaluations for live video streaming. For the subjective QoE study, we introduce the first live video streaming QoE dataset, TaoLive QoE, which consists of $42$ source videos collected from real live broadcasts and $1,155$ corresponding distorted ones degraded due to a variety of streaming distortions, including conventional streaming distortions such as compression, stalling, as well as live streaming-specific distortions like frame skipping, variable frame rate, etc. Subsequently, a human study was conducted to derive subjective QoE scores of videos in the TaoLive QoE dataset. For the objective QoE study, we benchmark existing QoE models on the TaoLive QoE dataset as well as publicly available QoE datasets for VoD scenarios, highlighting that current models struggle to accurately assess video QoE, particularly for live content. Hence, we propose an end-to-end QoE evaluation model, Tao-QoE, which integrates multi-scale semantic features and optical flow-based motion features to predicting a retrospective QoE score, eliminating reliance on statistical quality of service (QoS) features.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Dec 07, 2023



Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the SfM points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency. To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians into a more efficient and compact format. Drawing inspiration from the concept of Network Pruning, LightGaussian identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a pruning and recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects. Additionally, LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower degree, allowing knowledge transfer to more compact representations while maintaining reflectance. Furthermore, we propose a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth representations with minimal accuracy losses. In summary, LightGaussian achieves an averaged compression rate over 15x while boosting the FPS from 139 to 215, enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank and Temple datasets. Project website: https://lightgaussian.github.io/
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Dec 06, 2023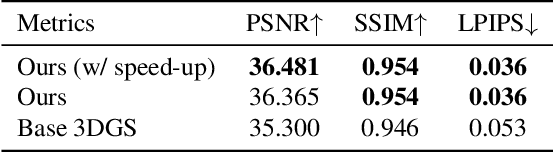
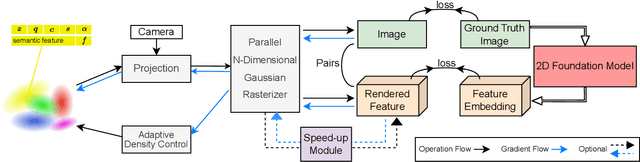
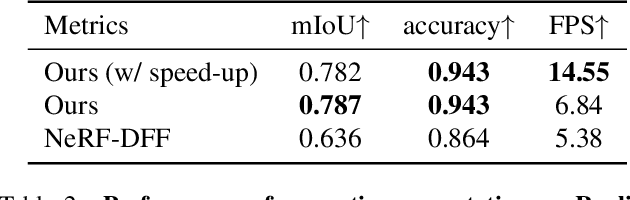
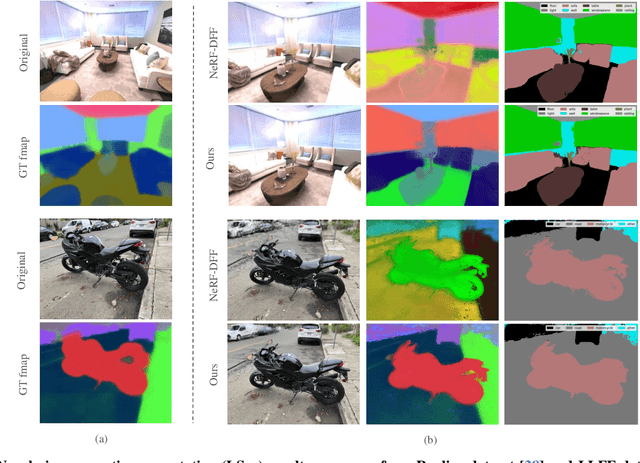
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework leads to warp-level divergence. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
Dec 01, 2023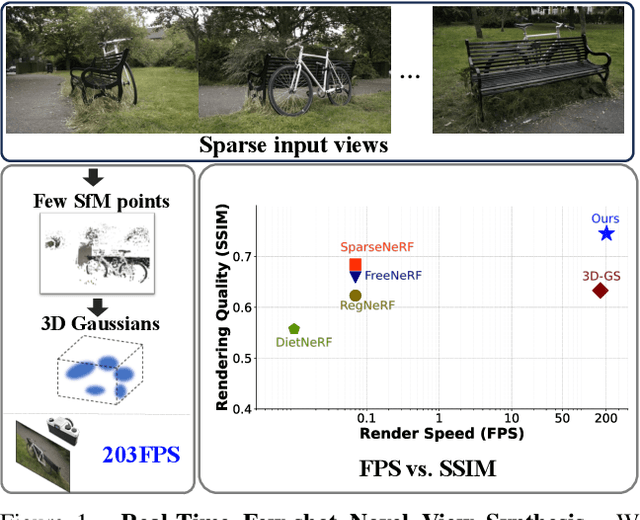



Novel view synthesis from limited observations remains an important and persistent task. However, high efficiency in existing NeRF-based few-shot view synthesis is often compromised to obtain an accurate 3D representation. To address this challenge, we propose a few-shot view synthesis framework based on 3D Gaussian Splatting that enables real-time and photo-realistic view synthesis with as few as three training views. The proposed method, dubbed FSGS, handles the extremely sparse initialized SfM points with a thoughtfully designed Gaussian Unpooling process. Our method iteratively distributes new Gaussians around the most representative locations, subsequently infilling local details in vacant areas. We also integrate a large-scale pre-trained monocular depth estimator within the Gaussians optimization process, leveraging online augmented views to guide the geometric optimization towards an optimal solution. Starting from sparse points observed from limited input viewpoints, our FSGS can accurately grow into unseen regions, comprehensively covering the scene and boosting the rendering quality of novel views. Overall, FSGS achieves state-of-the-art performance in both accuracy and rendering efficiency across diverse datasets, including LLFF, Mip-NeRF360, and Blender. Project website: https://zehaozhu.github.io/FSGS/.
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023
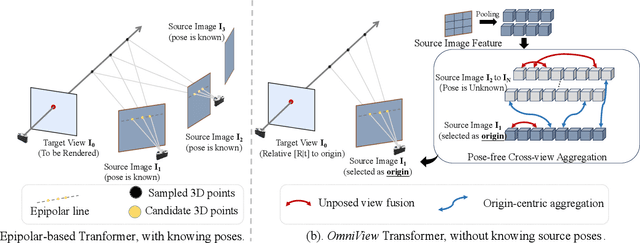
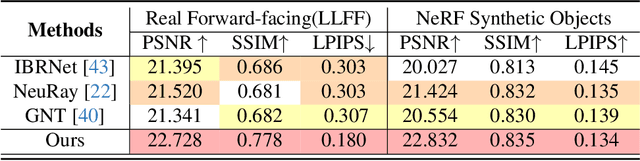
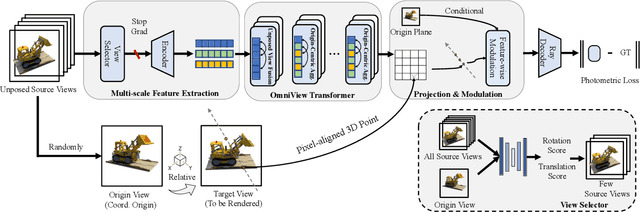
We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.
ContactArt: Learning 3D Interaction Priors for Category-level Articulated Object and Hand Poses Estimation
May 02, 2023
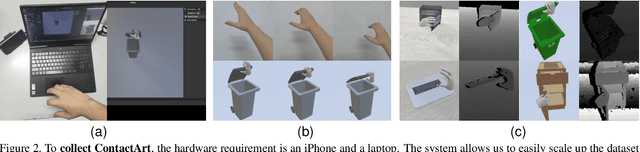
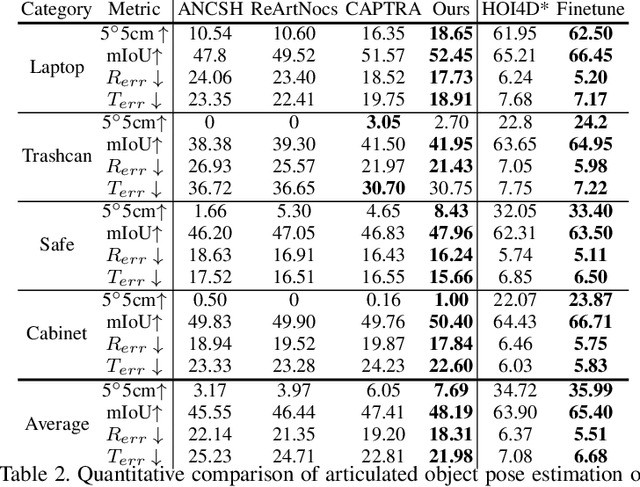
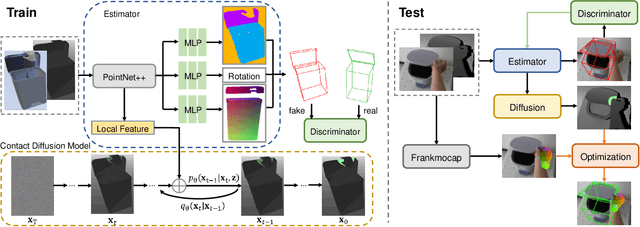
We propose a new dataset and a novel approach to learning hand-object interaction priors for hand and articulated object pose estimation. We first collect a dataset using visual teleoperation, where the human operator can directly play within a physical simulator to manipulate the articulated objects. We record the data and obtain free and accurate annotations on object poses and contact information from the simulator. Our system only requires an iPhone to record human hand motion, which can be easily scaled up and largely lower the costs of data and annotation collection. With this data, we learn 3D interaction priors including a discriminator (in a GAN) capturing the distribution of how object parts are arranged, and a diffusion model which generates the contact regions on articulated objects, guiding the hand pose estimation. Such structural and contact priors can easily transfer to real-world data with barely any domain gap. By using our data and learned priors, our method significantly improves the performance on joint hand and articulated object poses estimation over the existing state-of-the-art methods. The project is available at https://zehaozhu.github.io/ContactArt/ .