 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoProx: Evaluating MLLMs on Egocentric 3D Proximity Reasoning Across a Cognitive Hierarchy
May 26, 2026Humans constantly reason about 3D proximity, the relations between their body and surrounding objects, to guide perception and action in daily life. Whether multimodal large language models (MLLMs) can perform such embodied 3D reasoning remains unclear. To this end, we introduce EgoProx, a benchmark for egocentric 3D proximity reasoning. We organize our tasks along a cognitive chain, covering intention, exploration, exploitation, and chain-of-actions reasoning. We also design an agent based data engine that produces diverse and consistent QA pairs at scale. We benchmark prevailing MLLMs on EgoProx and conduct additional analyses with dataset specific and task specific instruction tuning. We observe large cross-domain gains, indicating that current MLLMs contain some spatial knowledge; however, they still struggle to effectively leverage it for spatial reasoning VQA.
IPIBench: Evaluating Interactive Proactive Intelligence of MLLMs under Continuous Streams
May 26, 2026Recent multimodal large language models (MLLMs) achieve strong performance on reactive question answering, but real-world streaming assistants require proactive reasoning over continuous visual inputs. Existing benchmarks mainly study reactive or proactive interactions in isolated single-turn settings, overlooking dynamic multi-turn scenarios where users may add, modify, or cancel proactive requests alongside interleaved reactive queries. To address this gap, we introduce IPIBench, the first benchmark for evaluating Interactive Proactive Intelligence of MLLMs under streaming video settings. IPIBench covers proactive monitoring, proactive task management, and interleaved reactive-proactive requests. Evaluations on representative MLLMs reveal two major limitations: unstable proactive triggering and weak coordination between reactive and proactive behaviors. We further propose IPI-Agent, a training-free agentic framework with an interaction-control policy and a temporal-gating mechanism for stabilizing proactive triggering and coordinating multi-turn interactions. Experiments show that IPI-Agent consistently improves existing MLLMs across all benchmark settings.
Thinking in Dynamics: How Multimodal Large Language Models Perceive, Track, and Reason Dynamics in Physical 4D World
Mar 13, 2026Humans inhabit a physical 4D world where geometric structure and semantic content evolve over time, constituting a dynamic 4D reality (spatial with temporal dimension). While current Multimodal Large Language Models (MLLMs) excel in static visual understanding, can they also be adept at "thinking in dynamics", i.e., perceive, track and reason about spatio-temporal dynamics in evolving scenes? To systematically assess their spatio-temporal reasoning and localized dynamics perception capabilities, we introduce Dyn-Bench, a large-scale benchmark built from diverse real-world and synthetic video datasets, enabling robust and scalable evaluation of spatio-temporal understanding. Through multi-stage filtering from massive 2D and 4D data sources, Dyn-Bench provides a high-quality collection of dynamic scenes, comprising 1k videos, 7k visual question answering (VQA) pairs, and 3k dynamic object grounding pairs. We probe general, spatial and region-level MLLMs to express how they think in dynamics both linguistically and visually, and find that existing models cannot simultaneously maintain strong performance in both spatio-temporal reasoning and dynamic object grounding, often producing inconsistent interpretations of motion and interaction. Notably, conventional prompting strategies (e.g., chain-of-thought or caption-based hints) provide limited improvement, whereas structured integration approaches, including Mask-Guided Fusion and Spatio-Temporal Textual Cognitive Map (ST-TCM), significantly enhance MLLMs' dynamics perception and spatio-temporal reasoning in the physical 4D world. Code and benchmark are available at https://dyn-bench.github.io/.
Martian World Models: Controllable Video Synthesis with Physically Accurate 3D Reconstructions
Jul 10, 2025



Synthesizing realistic Martian landscape videos is crucial for mission rehearsal and robotic simulation. However, this task poses unique challenges due to the scarcity of high-quality Martian data and the significant domain gap between Martian and terrestrial imagery. To address these challenges, we propose a holistic solution composed of two key components: 1) A data curation pipeline Multimodal Mars Synthesis (M3arsSynth), which reconstructs 3D Martian environments from real stereo navigation images, sourced from NASA's Planetary Data System (PDS), and renders high-fidelity multiview 3D video sequences. 2) A Martian terrain video generator, MarsGen, which synthesizes novel videos visually realistic and geometrically consistent with the 3D structure encoded in the data. Our M3arsSynth engine spans a wide range of Martian terrains and acquisition dates, enabling the generation of physically accurate 3D surface models at metric-scale resolution. MarsGen, fine-tuned on M3arsSynth data, synthesizes videos conditioned on an initial image frame and, optionally, camera trajectories or textual prompts, allowing for video generation in novel environments. Experimental results show that our approach outperforms video synthesis models trained on terrestrial datasets, achieving superior visual fidelity and 3D structural consistency.
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Jun 18, 2025Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Jun 05, 2025We introduce PartCrafter, the first structured 3D generative model that jointly synthesizes multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. Unlike existing methods that either produce monolithic 3D shapes or follow two-stage pipelines, i.e., first segmenting an image and then reconstructing each segment, PartCrafter adopts a unified, compositional generation architecture that does not rely on pre-segmented inputs. Conditioned on a single image, it simultaneously denoises multiple 3D parts, enabling end-to-end part-aware generation of both individual objects and complex multi-object scenes. PartCrafter builds upon a pretrained 3D mesh diffusion transformer (DiT) trained on whole objects, inheriting the pretrained weights, encoder, and decoder, and introduces two key innovations: (1) A compositional latent space, where each 3D part is represented by a set of disentangled latent tokens; (2) A hierarchical attention mechanism that enables structured information flow both within individual parts and across all parts, ensuring global coherence while preserving part-level detail during generation. To support part-level supervision, we curate a new dataset by mining part-level annotations from large-scale 3D object datasets. Experiments show that PartCrafter outperforms existing approaches in generating decomposable 3D meshes, including parts that are not directly visible in input images, demonstrating the strength of part-aware generative priors for 3D understanding and synthesis. Code and training data will be released.
JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
Apr 05, 2025



Vision-centric perception systems struggle with unpredictable and coupled weather degradations in the wild. Current solutions are often limited, as they either depend on specific degradation priors or suffer from significant domain gaps. To enable robust and autonomous operation in real-world conditions, we propose JarvisIR, a VLM-powered agent that leverages the VLM as a controller to manage multiple expert restoration models. To further enhance system robustness, reduce hallucinations, and improve generalizability in real-world adverse weather, JarvisIR employs a novel two-stage framework consisting of supervised fine-tuning and human feedback alignment. Specifically, to address the lack of paired data in real-world scenarios, the human feedback alignment enables the VLM to be fine-tuned effectively on large-scale real-world data in an unsupervised manner. To support the training and evaluation of JarvisIR, we introduce CleanBench, a comprehensive dataset consisting of high-quality and large-scale instruction-responses pairs, including 150K synthetic entries and 80K real entries. Extensive experiments demonstrate that JarvisIR exhibits superior decision-making and restoration capabilities. Compared with existing methods, it achieves a 50% improvement in the average of all perception metrics on CleanBench-Real. Project page: https://cvpr2025-jarvisir.github.io/.
DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
Jan 28, 2025Recent advancements in 3D content generation from text or a single image struggle with limited high-quality 3D datasets and inconsistency from 2D multi-view generation. We introduce DiffSplat, a novel 3D generative framework that natively generates 3D Gaussian splats by taming large-scale text-to-image diffusion models. It differs from previous 3D generative models by effectively utilizing web-scale 2D priors while maintaining 3D consistency in a unified model. To bootstrap the training, a lightweight reconstruction model is proposed to instantly produce multi-view Gaussian splat grids for scalable dataset curation. In conjunction with the regular diffusion loss on these grids, a 3D rendering loss is introduced to facilitate 3D coherence across arbitrary views. The compatibility with image diffusion models enables seamless adaptions of numerous techniques for image generation to the 3D realm. Extensive experiments reveal the superiority of DiffSplat in text- and image-conditioned generation tasks and downstream applications. Thorough ablation studies validate the efficacy of each critical design choice and provide insights into the underlying mechanism.
Multi-modal Relation Distillation for Unified 3D Representation Learning
Jul 19, 2024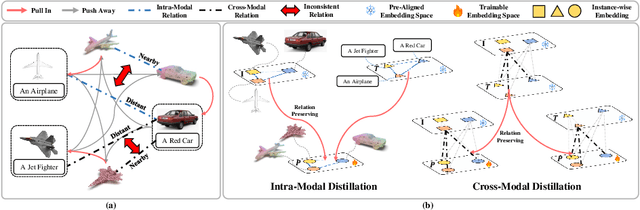

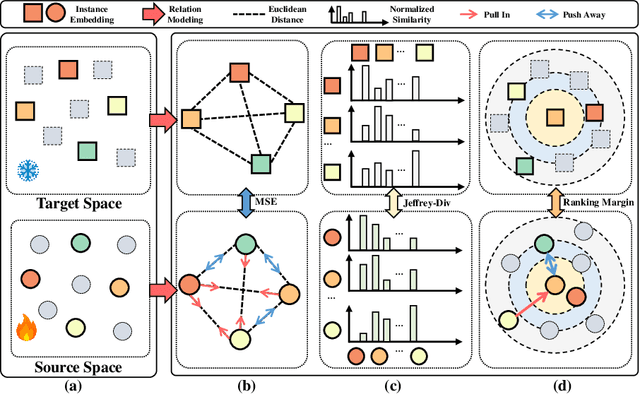

Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
InstructLayout: Instruction-Driven 2D and 3D Layout Synthesis with Semantic Graph Prior
Jul 11, 2024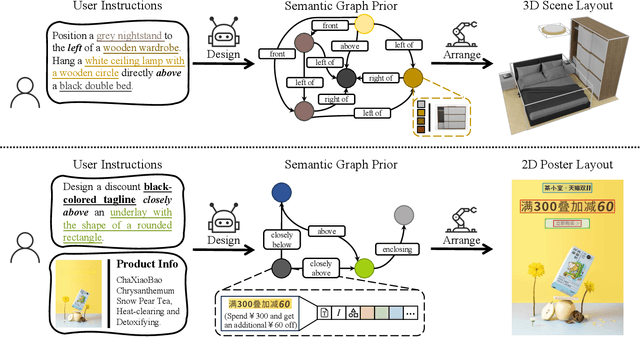
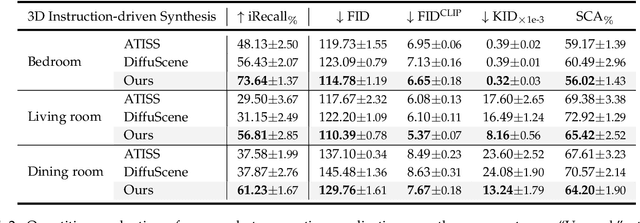
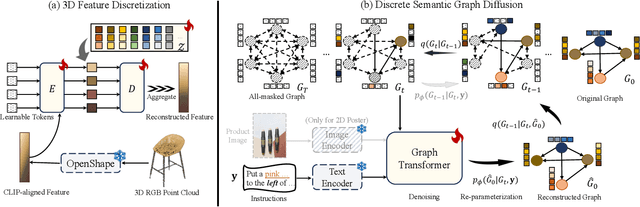
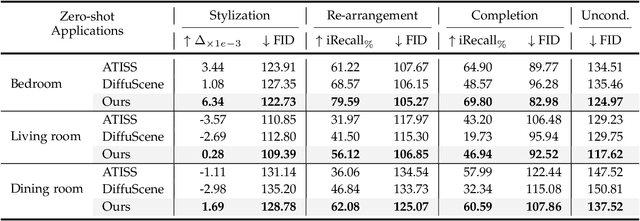
Comprehending natural language instructions is a charming property for both 2D and 3D layout synthesis systems. Existing methods implicitly model object joint distributions and express object relations, hindering generation's controllability. We introduce InstructLayout, a novel generative framework that integrates a semantic graph prior and a layout decoder to improve controllability and fidelity for 2D and 3D layout synthesis. The proposed semantic graph prior learns layout appearances and object distributions simultaneously, demonstrating versatility across various downstream tasks in a zero-shot manner. To facilitate the benchmarking for text-driven 2D and 3D scene synthesis, we respectively curate two high-quality datasets of layout-instruction pairs from public Internet resources with large language and multimodal models. Extensive experimental results reveal that the proposed method outperforms existing state-of-the-art approaches by a large margin in both 2D and 3D layout synthesis tasks. Thorough ablation studies confirm the efficacy of crucial design components.