 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiP4GEN: Text to Immersive Panorama 4D Scene Generation
Aug 17, 2025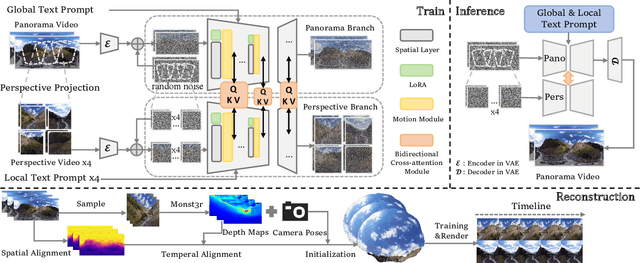
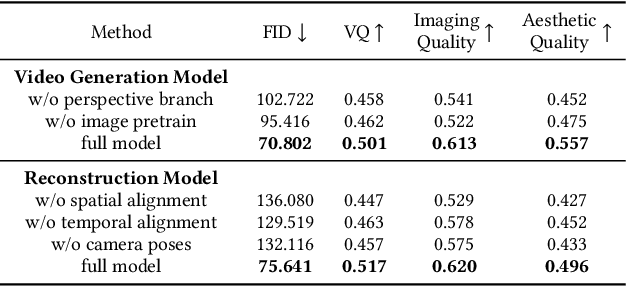
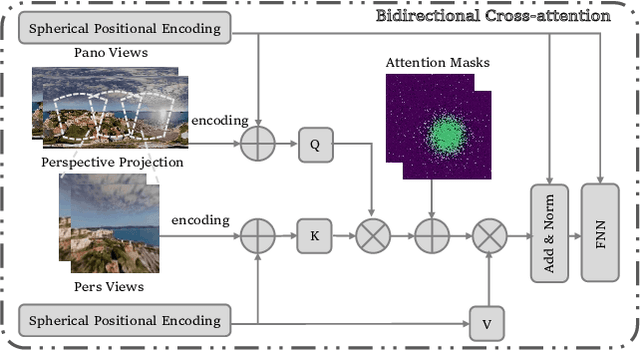
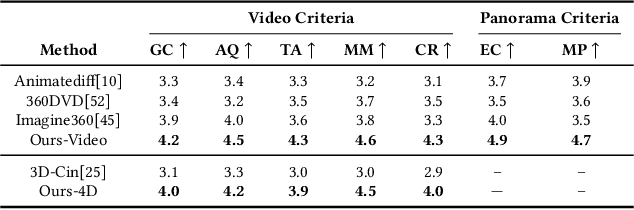
With the rapid advancement and widespread adoption of VR/AR technologies, there is a growing demand for the creation of high-quality, immersive dynamic scenes. However, existing generation works predominantly concentrate on the creation of static scenes or narrow perspective-view dynamic scenes, falling short of delivering a truly 360-degree immersive experience from any viewpoint. In this paper, we introduce \textbf{TiP4GEN}, an advanced text-to-dynamic panorama scene generation framework that enables fine-grained content control and synthesizes motion-rich, geometry-consistent panoramic 4D scenes. TiP4GEN integrates panorama video generation and dynamic scene reconstruction to create 360-degree immersive virtual environments. For video generation, we introduce a \textbf{Dual-branch Generation Model} consisting of a panorama branch and a perspective branch, responsible for global and local view generation, respectively. A bidirectional cross-attention mechanism facilitates comprehensive information exchange between the branches. For scene reconstruction, we propose a \textbf{Geometry-aligned Reconstruction Model} based on 3D Gaussian Splatting. By aligning spatial-temporal point clouds using metric depth maps and initializing scene cameras with estimated poses, our method ensures geometric consistency and temporal coherence for the reconstructed scenes. Extensive experiments demonstrate the effectiveness of our proposed designs and the superiority of TiP4GEN in generating visually compelling and motion-coherent dynamic panoramic scenes. Our project page is at https://ke-xing.github.io/TiP4GEN/.
HardTests: Synthesizing High-Quality Test Cases for LLM Coding
May 30, 2025Verifiers play a crucial role in large language model (LLM) reasoning, needed by post-training techniques such as reinforcement learning. However, reliable verifiers are hard to get for difficult coding problems, because a well-disguised wrong solution may only be detected by carefully human-written edge cases that are difficult to synthesize. To address this issue, we propose HARDTESTGEN, a pipeline for high-quality test synthesis using LLMs. With this pipeline, we curate a comprehensive competitive programming dataset HARDTESTS with 47k problems and synthetic high-quality tests. Compared with existing tests, HARDTESTGEN tests demonstrate precision that is 11.3 percentage points higher and recall that is 17.5 percentage points higher when evaluating LLM-generated code. For harder problems, the improvement in precision can be as large as 40 points. HARDTESTS also proves to be more effective for model training, measured by downstream code generation performance. We will open-source our dataset and synthesis pipeline at https://leililab.github.io/HardTests/.
RAGME: Retrieval Augmented Video Generation for Enhanced Motion Realism
Apr 09, 2025



Video generation is experiencing rapid growth, driven by advances in diffusion models and the development of better and larger datasets. However, producing high-quality videos remains challenging due to the high-dimensional data and the complexity of the task. Recent efforts have primarily focused on enhancing visual quality and addressing temporal inconsistencies, such as flickering. Despite progress in these areas, the generated videos often fall short in terms of motion complexity and physical plausibility, with many outputs either appearing static or exhibiting unrealistic motion. In this work, we propose a framework to improve the realism of motion in generated videos, exploring a complementary direction to much of the existing literature. Specifically, we advocate for the incorporation of a retrieval mechanism during the generation phase. The retrieved videos act as grounding signals, providing the model with demonstrations of how the objects move. Our pipeline is designed to apply to any text-to-video diffusion model, conditioning a pretrained model on the retrieved samples with minimal fine-tuning. We demonstrate the superiority of our approach through established metrics, recently proposed benchmarks, and qualitative results, and we highlight additional applications of the framework.
Can Test-Time Scaling Improve World Foundation Model?
Mar 31, 2025World foundation models, which simulate the physical world by predicting future states from current observations and inputs, have become central to many applications in physical intelligence, including autonomous driving and robotics. However, these models require substantial computational resources for pretraining and are further constrained by available data during post-training. As such, scaling computation at test time emerges as both a critical and practical alternative to traditional model enlargement or re-training. In this work, we introduce SWIFT, a test-time scaling framework tailored for WFMs. SWIFT integrates our extensible WFM evaluation toolkit with process-level inference strategies, including fast tokenization, probability-based Top-K pruning, and efficient beam search. Empirical results on the COSMOS model demonstrate that test-time scaling exists even in a compute-optimal way. Our findings reveal that test-time scaling laws hold for WFMs and that SWIFT provides a scalable and effective pathway for improving WFM inference without retraining or increasing model size. The code is available at https://github.com/Mia-Cong/SWIFT.git.
Feature4X: Bridging Any Monocular Video to 4D Agentic AI with Versatile Gaussian Feature Fields
Mar 26, 2025Recent advancements in 2D and multimodal models have achieved remarkable success by leveraging large-scale training on extensive datasets. However, extending these achievements to enable free-form interactions and high-level semantic operations with complex 3D/4D scenes remains challenging. This difficulty stems from the limited availability of large-scale, annotated 3D/4D or multi-view datasets, which are crucial for generalizable vision and language tasks such as open-vocabulary and prompt-based segmentation, language-guided editing, and visual question answering (VQA). In this paper, we introduce Feature4X, a universal framework designed to extend any functionality from 2D vision foundation model into the 4D realm, using only monocular video input, which is widely available from user-generated content. The "X" in Feature4X represents its versatility, enabling any task through adaptable, model-conditioned 4D feature field distillation. At the core of our framework is a dynamic optimization strategy that unifies multiple model capabilities into a single representation. Additionally, to the best of our knowledge, Feature4X is the first method to distill and lift the features of video foundation models (e.g. SAM2, InternVideo2) into an explicit 4D feature field using Gaussian Splatting. Our experiments showcase novel view segment anything, geometric and appearance scene editing, and free-form VQA across all time steps, empowered by LLMs in feedback loops. These advancements broaden the scope of agentic AI applications by providing a foundation for scalable, contextually and spatiotemporally aware systems capable of immersive dynamic 4D scene interaction.
Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
Oct 14, 2024In recent years there have been remarkable breakthroughs in image-to-video generation. However, the 3D consistency and camera controllability of generated frames have remained unsolved. Recent studies have attempted to incorporate camera control into the generation process, but their results are often limited to simple trajectories or lack the ability to generate consistent videos from multiple distinct camera paths for the same scene. To address these limitations, we introduce Cavia, a novel framework for camera-controllable, multi-view video generation, capable of converting an input image into multiple spatiotemporally consistent videos. Our framework extends the spatial and temporal attention modules into view-integrated attention modules, improving both viewpoint and temporal consistency. This flexible design allows for joint training with diverse curated data sources, including scene-level static videos, object-level synthetic multi-view dynamic videos, and real-world monocular dynamic videos. To our best knowledge, Cavia is the first of its kind that allows the user to precisely specify camera motion while obtaining object motion. Extensive experiments demonstrate that Cavia surpasses state-of-the-art methods in terms of geometric consistency and perceptual quality. Project Page: https://ir1d.github.io/Cavia/
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024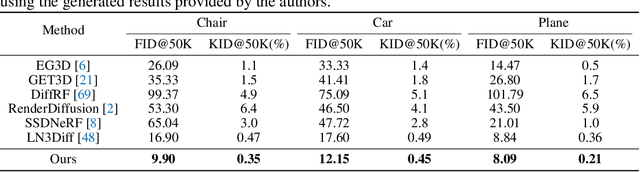
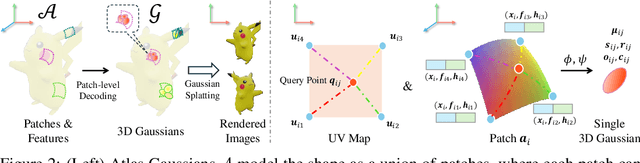
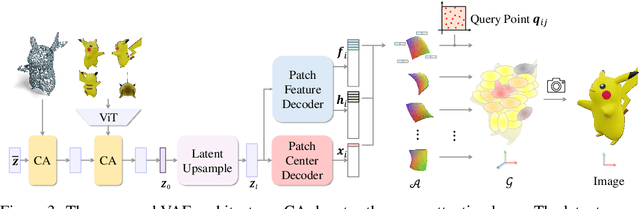
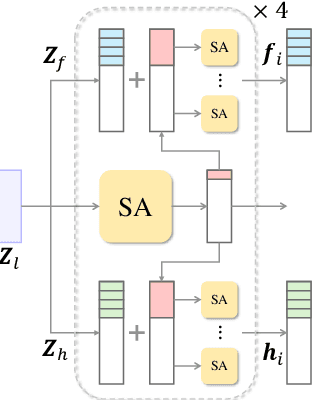
Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.
4K4DGen: Panoramic 4D Generation at 4K Resolution
Jun 19, 2024
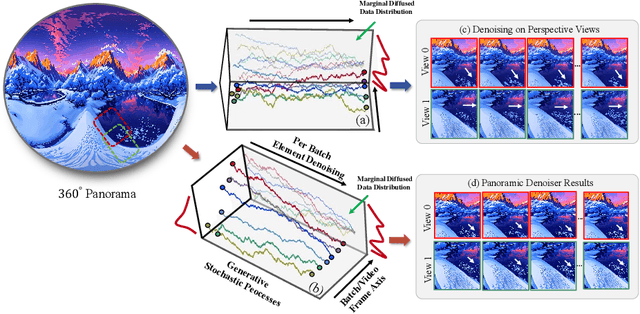

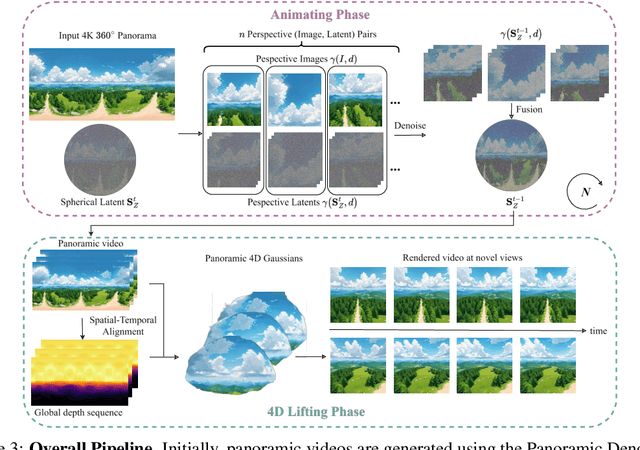
The blooming of virtual reality and augmented reality (VR/AR) technologies has driven an increasing demand for the creation of high-quality, immersive, and dynamic environments. However, existing generative techniques either focus solely on dynamic objects or perform outpainting from a single perspective image, failing to meet the needs of VR/AR applications. In this work, we tackle the challenging task of elevating a single panorama to an immersive 4D experience. For the first time, we demonstrate the capability to generate omnidirectional dynamic scenes with 360-degree views at 4K resolution, thereby providing an immersive user experience. Our method introduces a pipeline that facilitates natural scene animations and optimizes a set of 4D Gaussians using efficient splatting techniques for real-time exploration. To overcome the lack of scene-scale annotated 4D data and models, especially in panoramic formats, we propose a novel Panoramic Denoiser that adapts generic 2D diffusion priors to animate consistently in 360-degree images, transforming them into panoramic videos with dynamic scenes at targeted regions. Subsequently, we elevate the panoramic video into a 4D immersive environment while preserving spatial and temporal consistency. By transferring prior knowledge from 2D models in the perspective domain to the panoramic domain and the 4D lifting with spatial appearance and geometry regularization, we achieve high-quality Panorama-to-4D generation at a resolution of (4096 $\times$ 2048) for the first time. See the project website at https://4k4dgen.github.io.
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Jun 04, 2024


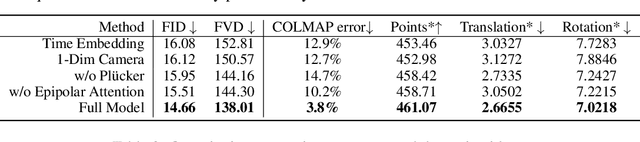
Recently video diffusion models have emerged as expressive generative tools for high-quality video content creation readily available to general users. However, these models often do not offer precise control over camera poses for video generation, limiting the expression of cinematic language and user control. To address this issue, we introduce CamCo, which allows fine-grained Camera pose Control for image-to-video generation. We equip a pre-trained image-to-video generator with accurately parameterized camera pose input using Pl\"ucker coordinates. To enhance 3D consistency in the videos produced, we integrate an epipolar attention module in each attention block that enforces epipolar constraints to the feature maps. Additionally, we fine-tune CamCo on real-world videos with camera poses estimated through structure-from-motion algorithms to better synthesize object motion. Our experiments show that CamCo significantly improves 3D consistency and camera control capabilities compared to previous models while effectively generating plausible object motion. Project page: https://ir1d.github.io/CamCo/
LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
May 30, 2024



Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.