 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing
Oct 22, 2025Recent advances in multimodal models have demonstrated remarkable text-guided image editing capabilities, with systems like GPT-4o and Nano-Banana setting new benchmarks. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built from real images. We introduce Pico-Banana-400K, a comprehensive 400K-image dataset for instruction-based image editing. Our dataset is constructed by leveraging Nano-Banana to generate diverse edit pairs from real photographs in the OpenImages collection. What distinguishes Pico-Banana-400K from previous synthetic datasets is our systematic approach to quality and diversity. We employ a fine-grained image editing taxonomy to ensure comprehensive coverage of edit types while maintaining precise content preservation and instruction faithfulness through MLLM-based quality scoring and careful curation. Beyond single turn editing, Pico-Banana-400K enables research into complex editing scenarios. The dataset includes three specialized subsets: (1) a 72K-example multi-turn collection for studying sequential editing, reasoning, and planning across consecutive modifications; (2) a 56K-example preference subset for alignment research and reward model training; and (3) paired long-short editing instructions for developing instruction rewriting and summarization capabilities. By providing this large-scale, high-quality, and task-rich resource, Pico-Banana-400K establishes a robust foundation for training and benchmarking the next generation of text-guided image editing models.
AToken: A Unified Tokenizer for Vision
Sep 19, 2025We present AToken, the first unified visual tokenizer that achieves both high-fidelity reconstruction and semantic understanding across images, videos, and 3D assets. Unlike existing tokenizers that specialize in either reconstruction or understanding for single modalities, AToken encodes these diverse visual inputs into a shared 4D latent space, unifying both tasks and modalities in a single framework. Specifically, we introduce a pure transformer architecture with 4D rotary position embeddings to process visual inputs of arbitrary resolutions and temporal durations. To ensure stable training, we introduce an adversarial-free training objective that combines perceptual and Gram matrix losses, achieving state-of-the-art reconstruction quality. By employing a progressive training curriculum, AToken gradually expands from single images, videos, and 3D, and supports both continuous and discrete latent tokens. AToken achieves 0.21 rFID with 82.2% ImageNet accuracy for images, 3.01 rFVD with 40.2% MSRVTT retrieval for videos, and 28.28 PSNR with 90.9% classification accuracy for 3D.. In downstream applications, AToken enables both visual generation tasks (e.g., image generation with continuous and discrete tokens, text-to-video generation, image-to-3D synthesis) and understanding tasks (e.g., multimodal LLMs), achieving competitive performance across all benchmarks. These results shed light on the next-generation multimodal AI systems built upon unified visual tokenization.
STIV: Scalable Text and Image Conditioned Video Generation
Dec 10, 2024The field of video generation has made remarkable advancements, yet there remains a pressing need for a clear, systematic recipe that can guide the development of robust and scalable models. In this work, we present a comprehensive study that systematically explores the interplay of model architectures, training recipes, and data curation strategies, culminating in a simple and scalable text-image-conditioned video generation method, named STIV. Our framework integrates image condition into a Diffusion Transformer (DiT) through frame replacement, while incorporating text conditioning via a joint image-text conditional classifier-free guidance. This design enables STIV to perform both text-to-video (T2V) and text-image-to-video (TI2V) tasks simultaneously. Additionally, STIV can be easily extended to various applications, such as video prediction, frame interpolation, multi-view generation, and long video generation, etc. With comprehensive ablation studies on T2I, T2V, and TI2V, STIV demonstrate strong performance, despite its simple design. An 8.7B model with 512 resolution achieves 83.1 on VBench T2V, surpassing both leading open and closed-source models like CogVideoX-5B, Pika, Kling, and Gen-3. The same-sized model also achieves a state-of-the-art result of 90.1 on VBench I2V task at 512 resolution. By providing a transparent and extensible recipe for building cutting-edge video generation models, we aim to empower future research and accelerate progress toward more versatile and reliable video generation solutions.
Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
Oct 14, 2024In recent years there have been remarkable breakthroughs in image-to-video generation. However, the 3D consistency and camera controllability of generated frames have remained unsolved. Recent studies have attempted to incorporate camera control into the generation process, but their results are often limited to simple trajectories or lack the ability to generate consistent videos from multiple distinct camera paths for the same scene. To address these limitations, we introduce Cavia, a novel framework for camera-controllable, multi-view video generation, capable of converting an input image into multiple spatiotemporally consistent videos. Our framework extends the spatial and temporal attention modules into view-integrated attention modules, improving both viewpoint and temporal consistency. This flexible design allows for joint training with diverse curated data sources, including scene-level static videos, object-level synthetic multi-view dynamic videos, and real-world monocular dynamic videos. To our best knowledge, Cavia is the first of its kind that allows the user to precisely specify camera motion while obtaining object motion. Extensive experiments demonstrate that Cavia surpasses state-of-the-art methods in terms of geometric consistency and perceptual quality. Project Page: https://ir1d.github.io/Cavia/
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Dec 26, 2023



The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
Relit-NeuLF: Efficient Relighting and Novel View Synthesis via Neural 4D Light Field
Oct 23, 2023



In this paper, we address the problem of simultaneous relighting and novel view synthesis of a complex scene from multi-view images with a limited number of light sources. We propose an analysis-synthesis approach called Relit-NeuLF. Following the recent neural 4D light field network (NeuLF), Relit-NeuLF first leverages a two-plane light field representation to parameterize each ray in a 4D coordinate system, enabling efficient learning and inference. Then, we recover the spatially-varying bidirectional reflectance distribution function (SVBRDF) of a 3D scene in a self-supervised manner. A DecomposeNet learns to map each ray to its SVBRDF components: albedo, normal, and roughness. Based on the decomposed BRDF components and conditioning light directions, a RenderNet learns to synthesize the color of the ray. To self-supervise the SVBRDF decomposition, we encourage the predicted ray color to be close to the physically-based rendering result using the microfacet model. Comprehensive experiments demonstrate that the proposed method is efficient and effective on both synthetic data and real-world human face data, and outperforms the state-of-the-art results. We publicly released our code on GitHub. You can find it here: https://github.com/oppo-us-research/RelitNeuLF
Efficient-3DiM: Learning a Generalizable Single-image Novel-view Synthesizer in One Day
Oct 04, 2023

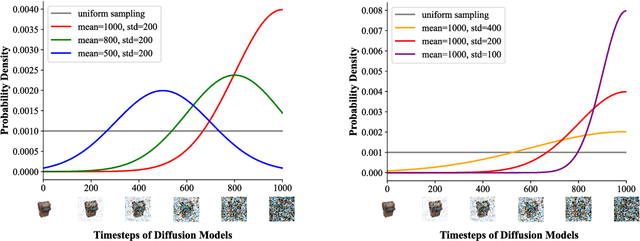
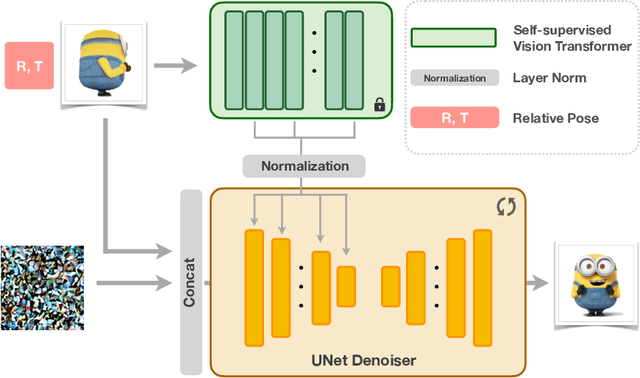
The task of novel view synthesis aims to generate unseen perspectives of an object or scene from a limited set of input images. Nevertheless, synthesizing novel views from a single image still remains a significant challenge in the realm of computer vision. Previous approaches tackle this problem by adopting mesh prediction, multi-plain image construction, or more advanced techniques such as neural radiance fields. Recently, a pre-trained diffusion model that is specifically designed for 2D image synthesis has demonstrated its capability in producing photorealistic novel views, if sufficiently optimized on a 3D finetuning task. Although the fidelity and generalizability are greatly improved, training such a powerful diffusion model requires a vast volume of training data and model parameters, resulting in a notoriously long time and high computational costs. To tackle this issue, we propose Efficient-3DiM, a simple but effective framework to learn a single-image novel-view synthesizer. Motivated by our in-depth analysis of the inference process of diffusion models, we propose several pragmatic strategies to reduce the training overhead to a manageable scale, including a crafted timestep sampling strategy, a superior 3D feature extractor, and an enhanced training scheme. When combined, our framework is able to reduce the total training time from 10 days to less than 1 day, significantly accelerating the training process under the same computational platform (one instance with 8 Nvidia A100 GPUs). Comprehensive experiments are conducted to demonstrate the efficiency and generalizability of our proposed method.
NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions
Sep 27, 2023
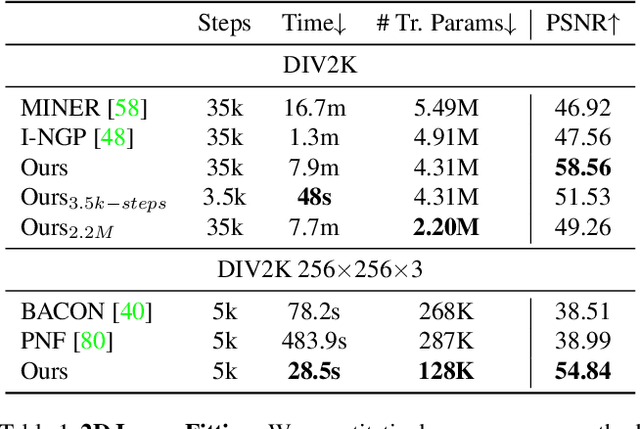
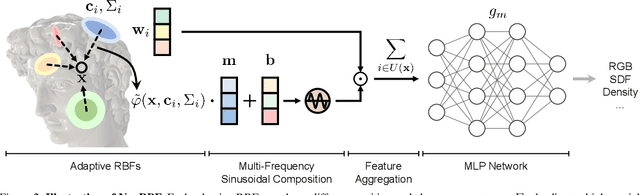
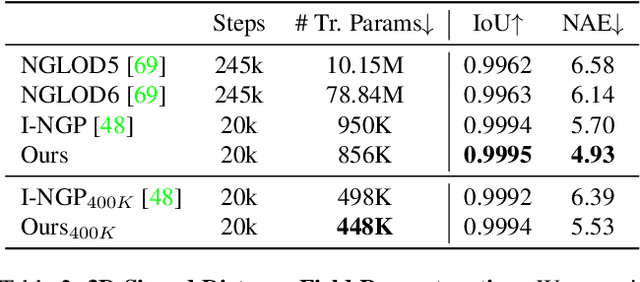
We present a novel type of neural fields that uses general radial bases for signal representation. State-of-the-art neural fields typically rely on grid-based representations for storing local neural features and N-dimensional linear kernels for interpolating features at continuous query points. The spatial positions of their neural features are fixed on grid nodes and cannot well adapt to target signals. Our method instead builds upon general radial bases with flexible kernel position and shape, which have higher spatial adaptivity and can more closely fit target signals. To further improve the channel-wise capacity of radial basis functions, we propose to compose them with multi-frequency sinusoid functions. This technique extends a radial basis to multiple Fourier radial bases of different frequency bands without requiring extra parameters, facilitating the representation of details. Moreover, by marrying adaptive radial bases with grid-based ones, our hybrid combination inherits both adaptivity and interpolation smoothness. We carefully designed weighting schemes to let radial bases adapt to different types of signals effectively. Our experiments on 2D image and 3D signed distance field representation demonstrate the higher accuracy and compactness of our method than prior arts. When applied to neural radiance field reconstruction, our method achieves state-of-the-art rendering quality, with small model size and comparable training speed.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023



The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.
Harnessing Low-Frequency Neural Fields for Few-Shot View Synthesis
Mar 15, 2023



Neural Radiance Fields (NeRF) have led to breakthroughs in the novel view synthesis problem. Positional Encoding (P.E.) is a critical factor that brings the impressive performance of NeRF, where low-dimensional coordinates are mapped to high-dimensional space to better recover scene details. However, blindly increasing the frequency of P.E. leads to overfitting when the reconstruction problem is highly underconstrained, \eg, few-shot images for training. We harness low-frequency neural fields to regularize high-frequency neural fields from overfitting to better address the problem of few-shot view synthesis. We propose reconstructing with a low-frequency only field and then finishing details with a high-frequency equipped field. Unlike most existing solutions that regularize the output space (\ie, rendered images), our regularization is conducted in the input space (\ie, signal frequency). We further propose a simple-yet-effective strategy for tuning the frequency to avoid overfitting few-shot inputs: enforcing consistency among the frequency domain of rendered 2D images. Thanks to the input space regularizing scheme, our method readily applies to inputs beyond spatial locations, such as the time dimension in dynamic scenes. Comparisons with state-of-the-art on both synthetic and natural datasets validate the effectiveness of our proposed solution for few-shot view synthesis. Code is available at \href{https://github.com/lsongx/halo}{https://github.com/lsongx/halo}.