 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelox: Learning Representations of 4D Geometry and Appearance
May 06, 2026We introduce a framework for learning latent representations of 4D objects which are descriptive, faithfully capturing object geometry and appearance; compressive, aiding in downstream efficiency; and accessible, requiring minimal input, i.e., an unstructured dynamic point cloud, to construct. Specifically, Velox trains an encoder to compress spatiotemporal color point clouds into a set of dynamic shape tokens. These tokens are supervised using two complementary decoders: a 4D surface decoder, which models the time-varying surface distribution capturing the geometry; and a Gaussian decoder, which maps the tokens to 3D Gaussians, helping learn appearance. To demonstrate the utility of our representation, we evaluate it across three downstream tasks -- video-to-4D generation, 3D tracking, and cloth simulation via image-to-4D generation -- and observe strong performances in all settings.
LiTo: Surface Light Field Tokenization
Mar 11, 2026We propose a 3D latent representation that jointly models object geometry and view-dependent appearance. Most prior works focus on either reconstructing 3D geometry or predicting view-independent diffuse appearance, and thus struggle to capture realistic view-dependent effects. Our approach leverages that RGB-depth images provide samples of a surface light field. By encoding random subsamples of this surface light field into a compact set of latent vectors, our model learns to represent both geometry and appearance within a unified 3D latent space. This representation reproduces view-dependent effects such as specular highlights and Fresnel reflections under complex lighting. We further train a latent flow matching model on this representation to learn its distribution conditioned on a single input image, enabling the generation of 3D objects with appearances consistent with the lighting and materials in the input. Experiments show that our approach achieves higher visual quality and better input fidelity than existing methods.
RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Jan 21, 2026We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
3D Shape Tokenization
Dec 24, 2024



We introduce Shape Tokens, a 3D representation that is continuous, compact, and easy to incorporate into machine learning models. Shape Tokens act as conditioning vectors that represent shape information in a 3D flow-matching model. The flow-matching model is trained to approximate probability density functions corresponding to delta functions concentrated on the surfaces of shapes in 3D. By attaching Shape Tokens to various machine learning models, we can generate new shapes, convert images to 3D, align 3D shapes with text and images, and render shapes directly at variable, user specified, resolution. Moreover, Shape Tokens enable a systematic analysis of geometric properties such as normal, density, and deformation field. Across all tasks and experiments, utilizing Shape Tokens demonstrate strong performance compared to existing baselines.
Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum
May 21, 2024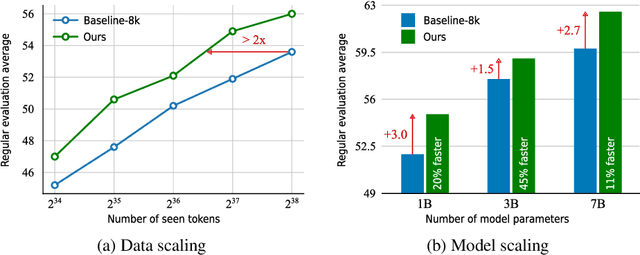
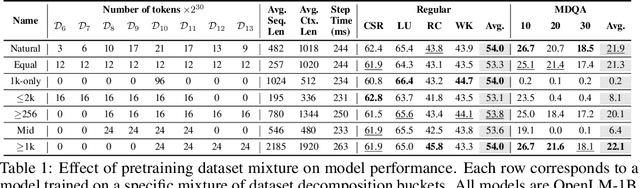
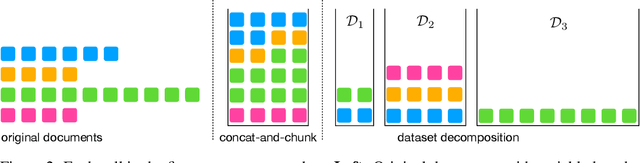
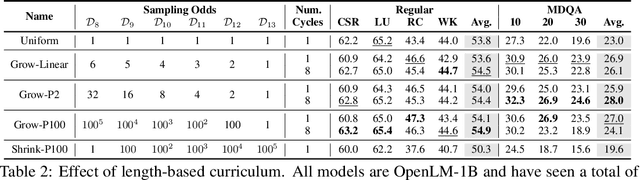
Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length. However, this method of concatenation can lead to cross-document attention within a sequence, which is neither a desirable learning signal nor computationally efficient. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a penalty proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy 3x faster compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.
Probabilistic Speech-Driven 3D Facial Motion Synthesis: New Benchmarks, Methods, and Applications
Nov 30, 2023



We consider the task of animating 3D facial geometry from speech signal. Existing works are primarily deterministic, focusing on learning a one-to-one mapping from speech signal to 3D face meshes on small datasets with limited speakers. While these models can achieve high-quality lip articulation for speakers in the training set, they are unable to capture the full and diverse distribution of 3D facial motions that accompany speech in the real world. Importantly, the relationship between speech and facial motion is one-to-many, containing both inter-speaker and intra-speaker variations and necessitating a probabilistic approach. In this paper, we identify and address key challenges that have so far limited the development of probabilistic models: lack of datasets and metrics that are suitable for training and evaluating them, as well as the difficulty of designing a model that generates diverse results while remaining faithful to a strong conditioning signal as speech. We first propose large-scale benchmark datasets and metrics suitable for probabilistic modeling. Then, we demonstrate a probabilistic model that achieves both diversity and fidelity to speech, outperforming other methods across the proposed benchmarks. Finally, we showcase useful applications of probabilistic models trained on these large-scale datasets: we can generate diverse speech-driven 3D facial motion that matches unseen speaker styles extracted from reference clips; and our synthetic meshes can be used to improve the performance of downstream audio-visual models.
HUGS: Human Gaussian Splats
Nov 29, 2023Recent advances in neural rendering have improved both training and rendering times by orders of magnitude. While these methods demonstrate state-of-the-art quality and speed, they are designed for photogrammetry of static scenes and do not generalize well to freely moving humans in the environment. In this work, we introduce Human Gaussian Splats (HUGS) that represents an animatable human together with the scene using 3D Gaussian Splatting (3DGS). Our method takes only a monocular video with a small number of (50-100) frames, and it automatically learns to disentangle the static scene and a fully animatable human avatar within 30 minutes. We utilize the SMPL body model to initialize the human Gaussians. To capture details that are not modeled by SMPL (e.g. cloth, hairs), we allow the 3D Gaussians to deviate from the human body model. Utilizing 3D Gaussians for animated humans brings new challenges, including the artifacts created when articulating the Gaussians. We propose to jointly optimize the linear blend skinning weights to coordinate the movements of individual Gaussians during animation. Our approach enables novel-pose synthesis of human and novel view synthesis of both the human and the scene. We achieve state-of-the-art rendering quality with a rendering speed of 60 FPS while being ~100x faster to train over previous work. Our code will be announced here: https://github.com/apple/ml-hugs
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Oct 23, 2023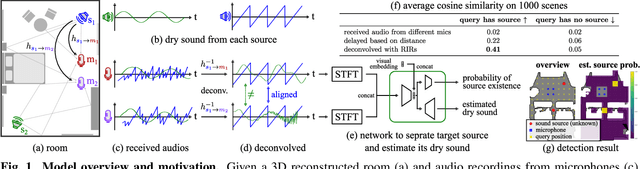
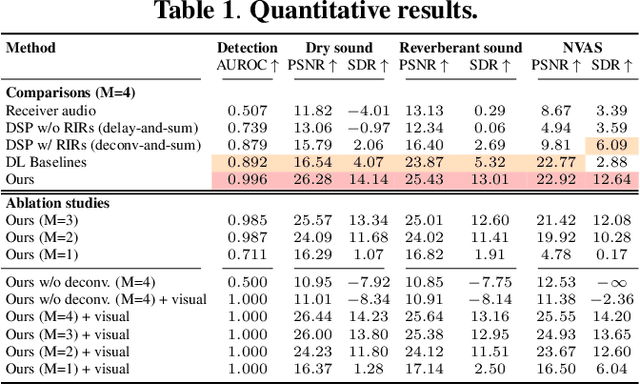
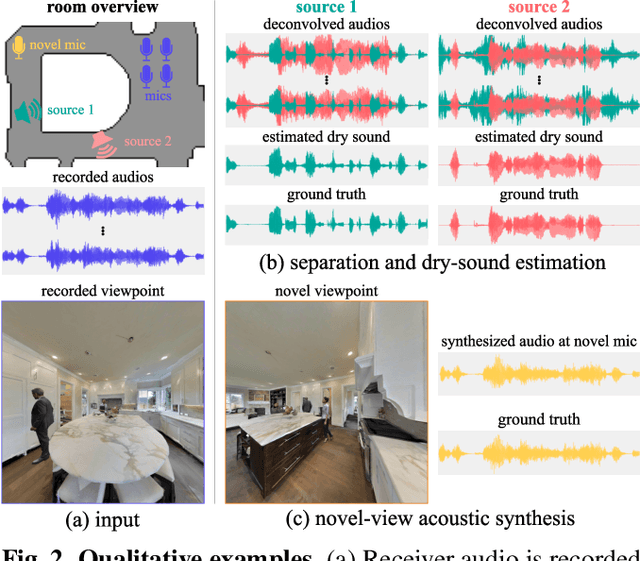
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
Efficient-3DiM: Learning a Generalizable Single-image Novel-view Synthesizer in One Day
Oct 04, 2023

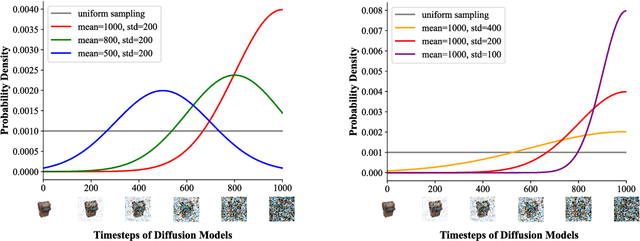
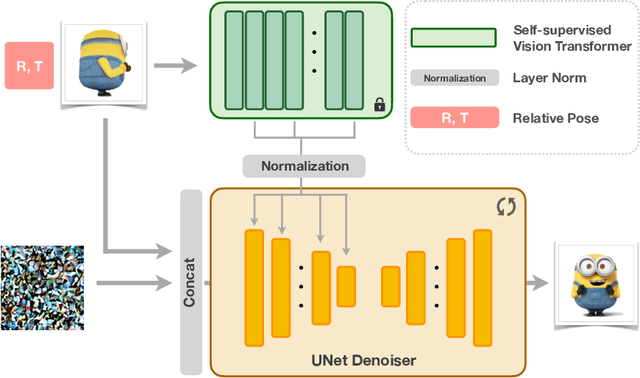
The task of novel view synthesis aims to generate unseen perspectives of an object or scene from a limited set of input images. Nevertheless, synthesizing novel views from a single image still remains a significant challenge in the realm of computer vision. Previous approaches tackle this problem by adopting mesh prediction, multi-plain image construction, or more advanced techniques such as neural radiance fields. Recently, a pre-trained diffusion model that is specifically designed for 2D image synthesis has demonstrated its capability in producing photorealistic novel views, if sufficiently optimized on a 3D finetuning task. Although the fidelity and generalizability are greatly improved, training such a powerful diffusion model requires a vast volume of training data and model parameters, resulting in a notoriously long time and high computational costs. To tackle this issue, we propose Efficient-3DiM, a simple but effective framework to learn a single-image novel-view synthesizer. Motivated by our in-depth analysis of the inference process of diffusion models, we propose several pragmatic strategies to reduce the training overhead to a manageable scale, including a crafted timestep sampling strategy, a superior 3D feature extractor, and an enhanced training scheme. When combined, our framework is able to reduce the total training time from 10 days to less than 1 day, significantly accelerating the training process under the same computational platform (one instance with 8 Nvidia A100 GPUs). Comprehensive experiments are conducted to demonstrate the efficiency and generalizability of our proposed method.