 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernetworks for Personalizing ASR to Atypical Speech
Jun 07, 2024Parameter-efficient fine-tuning (PEFT) for personalizing automatic speech recognition (ASR) has recently shown promise for adapting general population models to atypical speech. However, these approaches assume a priori knowledge of the atypical speech disorder being adapted for -- the diagnosis of which requires expert knowledge that is not always available. Even given this knowledge, data scarcity and high inter/intra-speaker variability further limit the effectiveness of traditional fine-tuning. To circumvent these challenges, we first identify the minimal set of model parameters required for ASR adaptation. Our analysis of each individual parameter's effect on adaptation performance allows us to reduce Word Error Rate (WER) by half while adapting 0.03% of all weights. Alleviating the need for cohort-specific models, we next propose the novel use of a meta-learned hypernetwork to generate highly individualized, utterance-level adaptations on-the-fly for a diverse set of atypical speech characteristics. Evaluating adaptation at the global, cohort and individual-level, we show that hypernetworks generalize better to out-of-distribution speakers, while maintaining an overall relative WER reduction of 75.2% using 0.1% of the full parameter budget.
Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models
Sep 18, 2023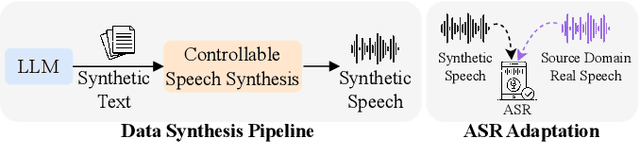

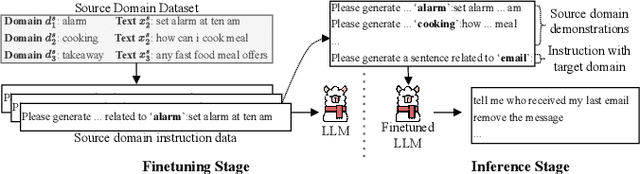
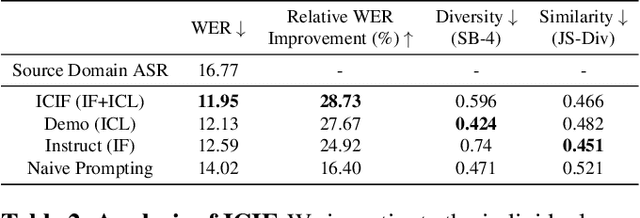
While Automatic Speech Recognition (ASR) systems are widely used in many real-world applications, they often do not generalize well to new domains and need to be finetuned on data from these domains. However, target-domain data usually are not readily available in many scenarios. In this paper, we propose a new strategy for adapting ASR models to new target domains without any text or speech from those domains. To accomplish this, we propose a novel data synthesis pipeline that uses a Large Language Model (LLM) to generate a target domain text corpus, and a state-of-the-art controllable speech synthesis model to generate the corresponding speech. We propose a simple yet effective in-context instruction finetuning strategy to increase the effectiveness of LLM in generating text corpora for new domains. Experiments on the SLURP dataset show that the proposed method achieves an average relative word error rate improvement of $28\%$ on unseen target domains without any performance drop in source domains.