 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPASS: A Multi-Turn Benchmark for Tool-Mediated Planning & Preference Optimization
Oct 08, 2025
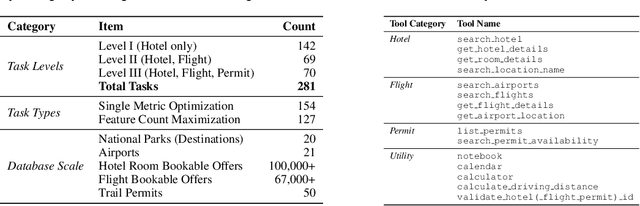
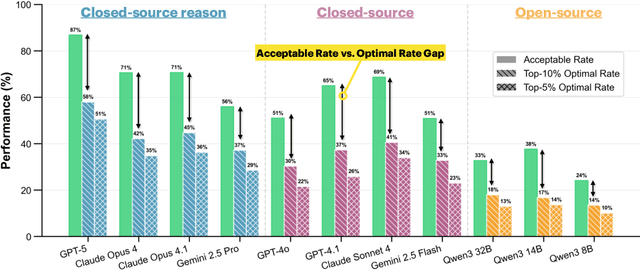

Real-world large language model (LLM) agents must master strategic tool use and user preference optimization through multi-turn interactions to assist users with complex planning tasks. We introduce COMPASS (Constrained Optimization through Multi-turn Planning and Strategic Solutions), a benchmark that evaluates agents on realistic travel-planning scenarios. We cast travel planning as a constrained preference optimization problem, where agents must satisfy hard constraints while simultaneously optimizing soft user preferences. To support this, we build a realistic travel database covering transportation, accommodation, and ticketing for 20 U.S. National Parks, along with a comprehensive tool ecosystem that mirrors commercial booking platforms. Evaluating state-of-the-art models, we uncover two critical gaps: (i) an acceptable-optimal gap, where agents reliably meet constraints but fail to optimize preferences, and (ii) a plan-coordination gap, where performance collapses on multi-service (flight and hotel) coordination tasks, especially for open-source models. By grounding reasoning and planning in a practical, user-facing domain, COMPASS provides a benchmark that directly measures an agent's ability to optimize user preferences in realistic tasks, bridging theoretical advances with real-world impact.
Learning to Reason for Hallucination Span Detection
Oct 02, 2025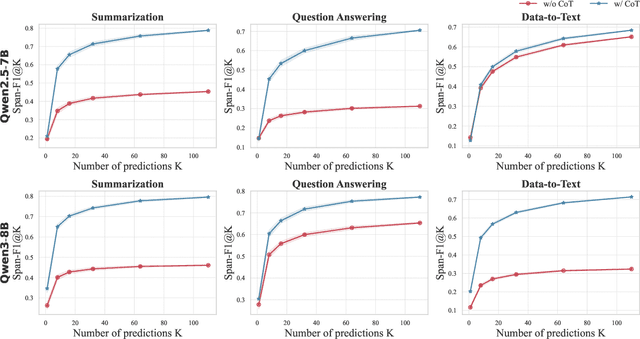
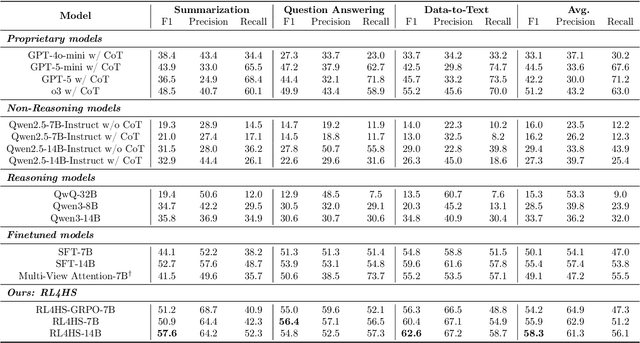
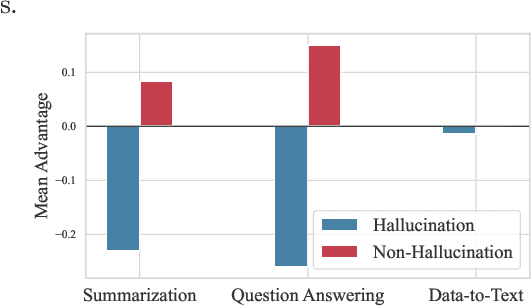
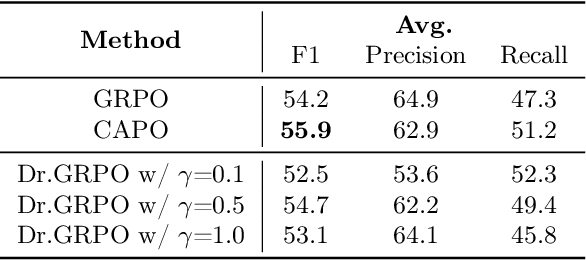
Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
MUSCLE: A Model Update Strategy for Compatible LLM Evolution
Jul 12, 2024



Large Language Models (LLMs) are frequently updated due to data or architecture changes to improve their performance. When updating models, developers often focus on increasing overall performance metrics with less emphasis on being compatible with previous model versions. However, users often build a mental model of the functionality and capabilities of a particular machine learning model they are interacting with. They have to adapt their mental model with every update -- a draining task that can lead to user dissatisfaction. In practice, fine-tuned downstream task adapters rely on pretrained LLM base models. When these base models are updated, these user-facing downstream task models experience instance regression or negative flips -- previously correct instances are now predicted incorrectly. This happens even when the downstream task training procedures remain identical. Our work aims to provide seamless model updates to a user in two ways. First, we provide evaluation metrics for a notion of compatibility to prior model versions, specifically for generative tasks but also applicable for discriminative tasks. We observe regression and inconsistencies between different model versions on a diverse set of tasks and model updates. Second, we propose a training strategy to minimize the number of inconsistencies in model updates, involving training of a compatibility model that can enhance task fine-tuned language models. We reduce negative flips -- instances where a prior model version was correct, but a new model incorrect -- by up to 40% from Llama 1 to Llama 2.
Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models
Sep 18, 2023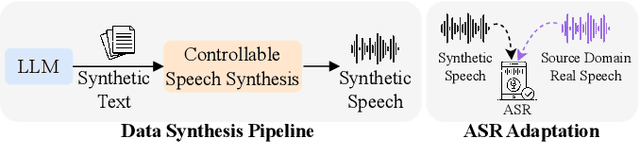

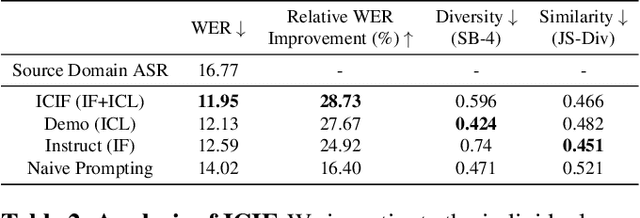
While Automatic Speech Recognition (ASR) systems are widely used in many real-world applications, they often do not generalize well to new domains and need to be finetuned on data from these domains. However, target-domain data usually are not readily available in many scenarios. In this paper, we propose a new strategy for adapting ASR models to new target domains without any text or speech from those domains. To accomplish this, we propose a novel data synthesis pipeline that uses a Large Language Model (LLM) to generate a target domain text corpus, and a state-of-the-art controllable speech synthesis model to generate the corresponding speech. We propose a simple yet effective in-context instruction finetuning strategy to increase the effectiveness of LLM in generating text corpora for new domains. Experiments on the SLURP dataset show that the proposed method achieves an average relative word error rate improvement of $28\%$ on unseen target domains without any performance drop in source domains.
Text is All You Need: Personalizing ASR Models using Controllable Speech Synthesis
Mar 27, 2023



Adapting generic speech recognition models to specific individuals is a challenging problem due to the scarcity of personalized data. Recent works have proposed boosting the amount of training data using personalized text-to-speech synthesis. Here, we ask two fundamental questions about this strategy: when is synthetic data effective for personalization, and why is it effective in those cases? To address the first question, we adapt a state-of-the-art automatic speech recognition (ASR) model to target speakers from four benchmark datasets representative of different speaker types. We show that ASR personalization with synthetic data is effective in all cases, but particularly when (i) the target speaker is underrepresented in the global data, and (ii) the capacity of the global model is limited. To address the second question of why personalized synthetic data is effective, we use controllable speech synthesis to generate speech with varied styles and content. Surprisingly, we find that the text content of the synthetic data, rather than style, is important for speaker adaptation. These results lead us to propose a data selection strategy for ASR personalization based on speech content.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
Synt++: Utilizing Imperfect Synthetic Data to Improve Speech Recognition
Oct 21, 2021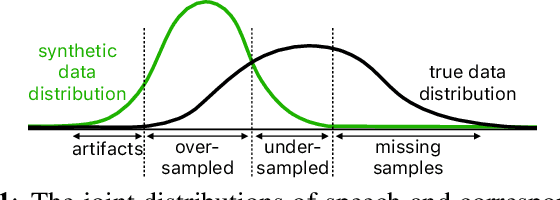
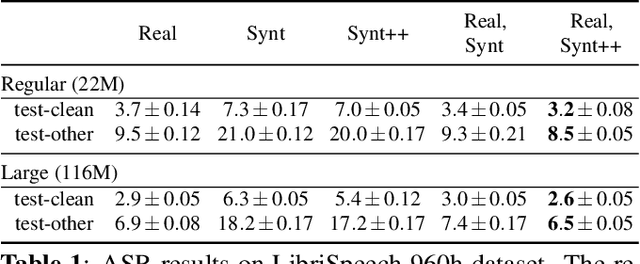
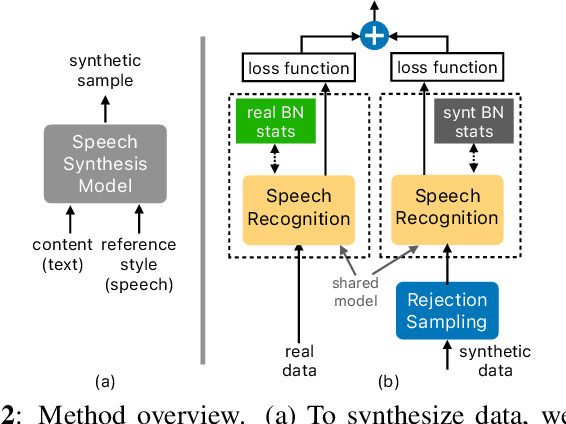
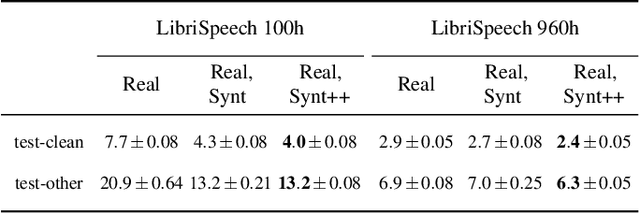
With recent advances in speech synthesis, synthetic data is becoming a viable alternative to real data for training speech recognition models. However, machine learning with synthetic data is not trivial due to the gap between the synthetic and the real data distributions. Synthetic datasets may contain artifacts that do not exist in real data such as structured noise, content errors, or unrealistic speaking styles. Moreover, the synthesis process may introduce a bias due to uneven sampling of the data manifold. We propose two novel techniques during training to mitigate the problems due to the distribution gap: (i) a rejection sampling algorithm and (ii) using separate batch normalization statistics for the real and the synthetic samples. We show that these methods significantly improve the training of speech recognition models using synthetic data. We evaluate the proposed approach on keyword detection and Automatic Speech Recognition (ASR) tasks, and observe up to 18% and 13% relative error reduction, respectively, compared to naively using the synthetic data.
Subspace Representation Learning for Few-shot Image Classification
May 05, 2021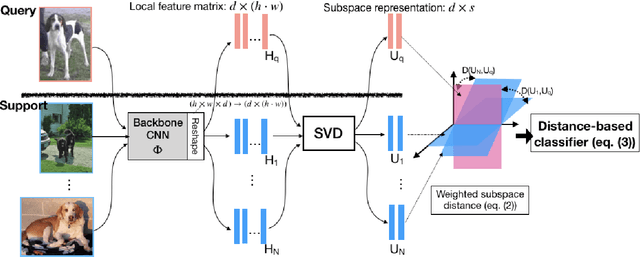
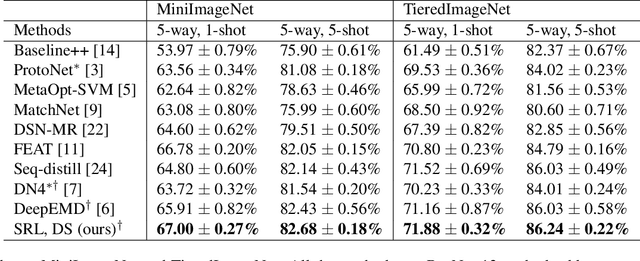
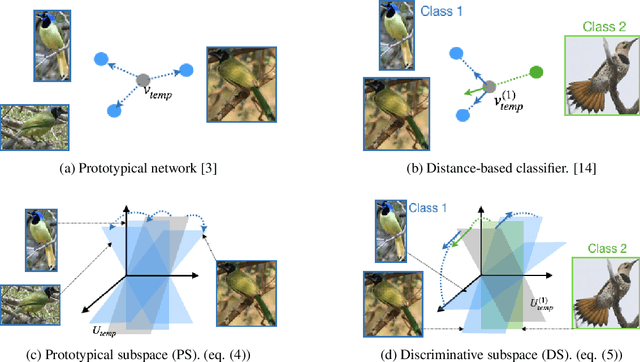
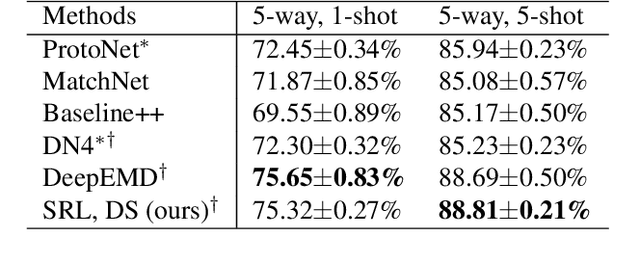
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
Pose Guided Person Image Generation with Hidden p-Norm Regression
Feb 19, 2021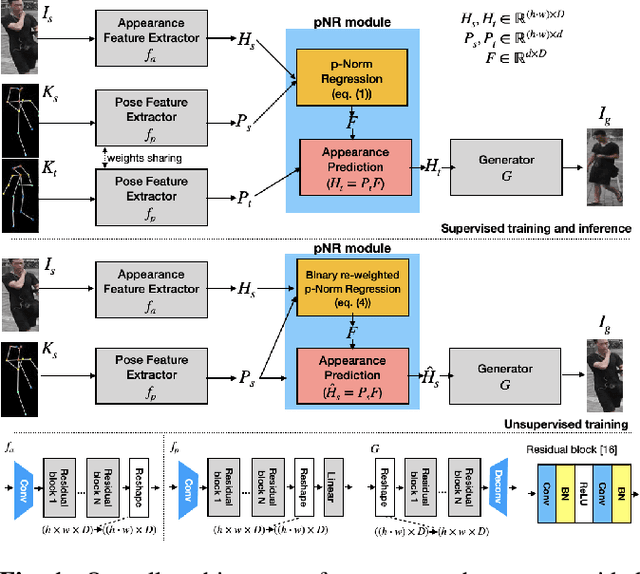
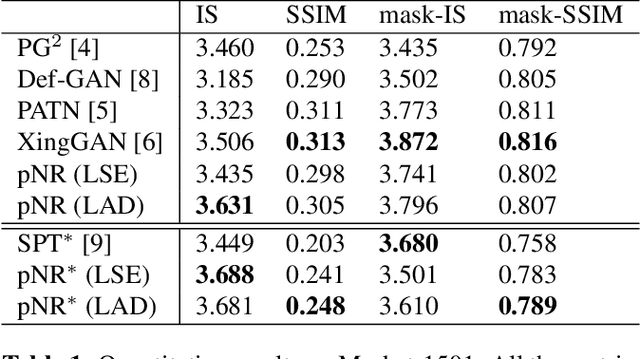

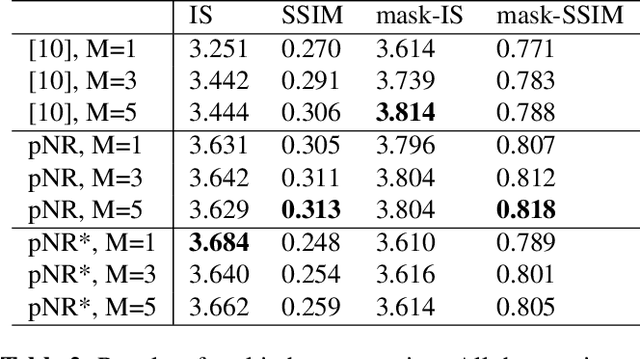
In this paper, we propose a novel approach to solve the pose guided person image generation task. We assume that the relation between pose and appearance information can be described by a simple matrix operation in hidden space. Based on this assumption, our method estimates a pose-invariant feature matrix for each identity, and uses it to predict the target appearance conditioned on the target pose. The estimation process is formulated as a p-norm regression problem in hidden space. By utilizing the differentiation of the solution of this regression problem, the parameters of the whole framework can be trained in an end-to-end manner. While most previous works are only applicable to the supervised training and single-shot generation scenario, our method can be easily adapted to unsupervised training and multi-shot generation. Extensive experiments on the challenging Market-1501 dataset show that our method yields competitive performance in all the aforementioned variant scenarios.