 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023


This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
Neural Transducer Training: Reduced Memory Consumption with Sample-wise Computation
Nov 29, 2022The neural transducer is an end-to-end model for automatic speech recognition (ASR). While the model is well-suited for streaming ASR, the training process remains challenging. During training, the memory requirements may quickly exceed the capacity of state-of-the-art GPUs, limiting batch size and sequence lengths. In this work, we analyze the time and space complexity of a typical transducer training setup. We propose a memory-efficient training method that computes the transducer loss and gradients sample by sample. We present optimizations to increase the efficiency and parallelism of the sample-wise method. In a set of thorough benchmarks, we show that our sample-wise method significantly reduces memory usage, and performs at competitive speed when compared to the default batched computation. As a highlight, we manage to compute the transducer loss and gradients for a batch size of 1024, and audio length of 40 seconds, using only 6 GB of memory.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Declarative Guideline Conformance Checking of Clinical Treatments: A Case Study
Sep 20, 2022
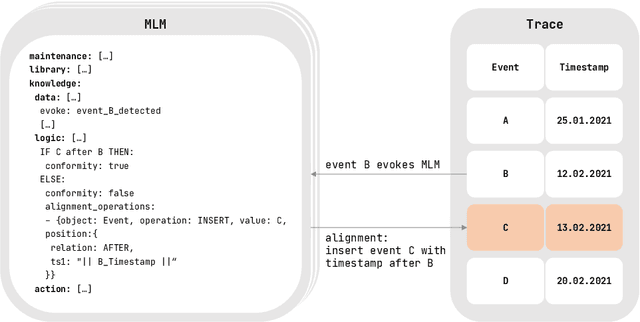
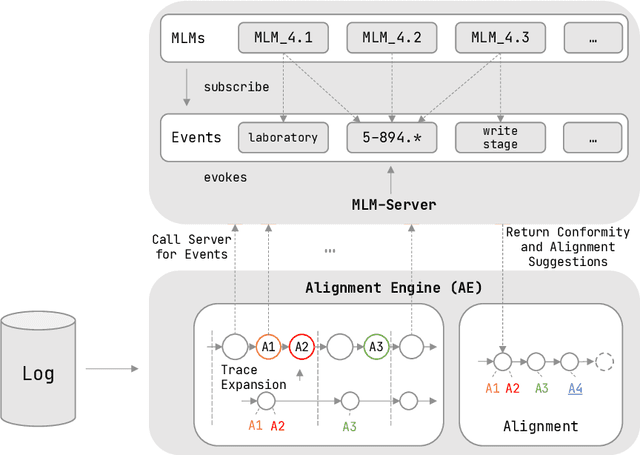
Conformance checking is a process mining technique that allows verifying the conformance of process instances to a given model. Thus, this technique is predestined to be used in the medical context for the comparison of treatment cases with clinical guidelines. However, medical processes are highly variable, highly dynamic, and complex. This makes the use of imperative conformance checking approaches in the medical domain difficult. Studies show that declarative approaches can better address these characteristics. However, none of the approaches has yet gained practical acceptance. Another challenge are alignments, which usually do not add any value from a medical point of view. For this reason, we investigate in a case study the usability of the HL7 standard Arden Syntax for declarative, rule-based conformance checking and the use of manually modeled alignments. Using the approach, it was possible to check the conformance of treatment cases and create medically meaningful alignments for large parts of a medical guideline.
SapAugment: Learning A Sample Adaptive Policy for Data Augmentation
Nov 02, 2020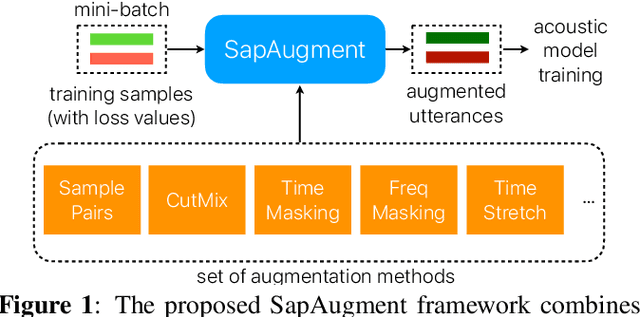
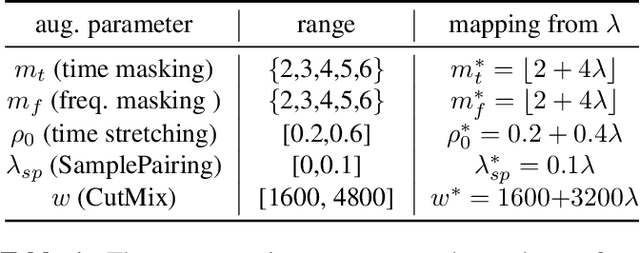
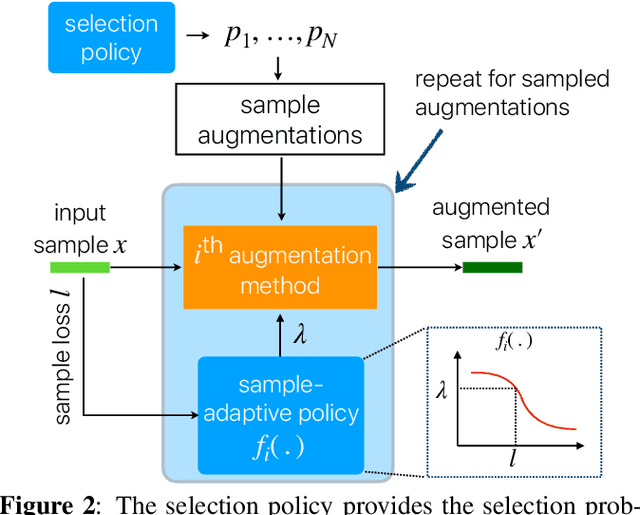
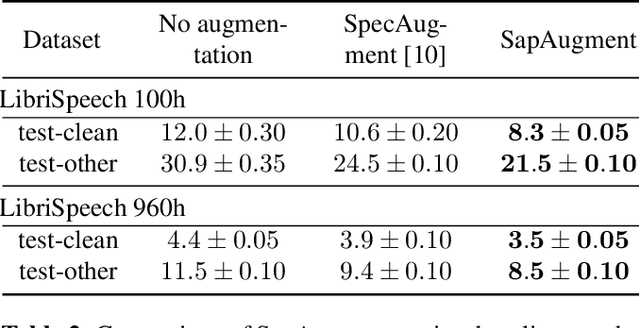
Data augmentation methods usually apply the same augmentation (or a mix of them) to all the training samples. For example, to perturb data with noise, the noise is sampled from a Normal distribution with a fixed standard deviation, for all samples. We hypothesize that a hard sample with high training loss already provides strong training signal to update the model parameters and should be perturbed with mild or no augmentation. Perturbing a hard sample with a strong augmentation may also make it too hard to learn from. Furthermore, a sample with low training loss should be perturbed by a stronger augmentation to provide more robustness to a variety of conditions. To formalize these intuitions, we propose a novel method to learn a Sample-Adaptive Policy for Augmentation -- SapAugment. Our policy adapts the augmentation parameters based on the training loss of the data samples. In the example of Gaussian noise, a hard sample will be perturbed with a low variance noise and an easy sample with a high variance noise. Furthermore, the proposed method combines multiple augmentation methods into a methodical policy learning framework and obviates hand-crafting augmentation parameters by trial-and-error. We apply our method on an automatic speech recognition (ASR) task, and combine existing and novel augmentations using the proposed framework. We show substantial improvement, up to 21% relative reduction in word error rate on LibriSpeech dataset, over the state-of-the-art speech augmentation method.
LSTM Benchmarks for Deep Learning Frameworks
Jun 05, 2018
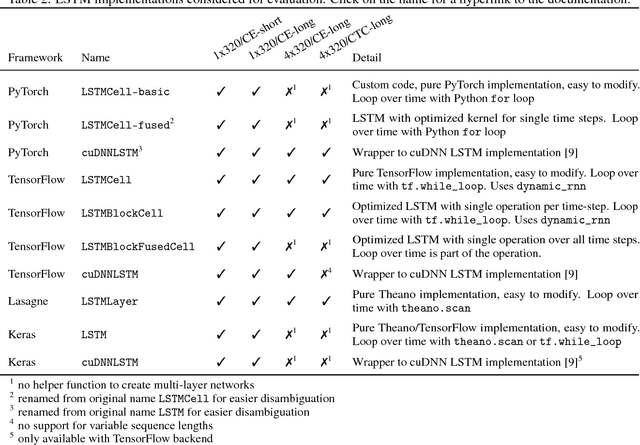

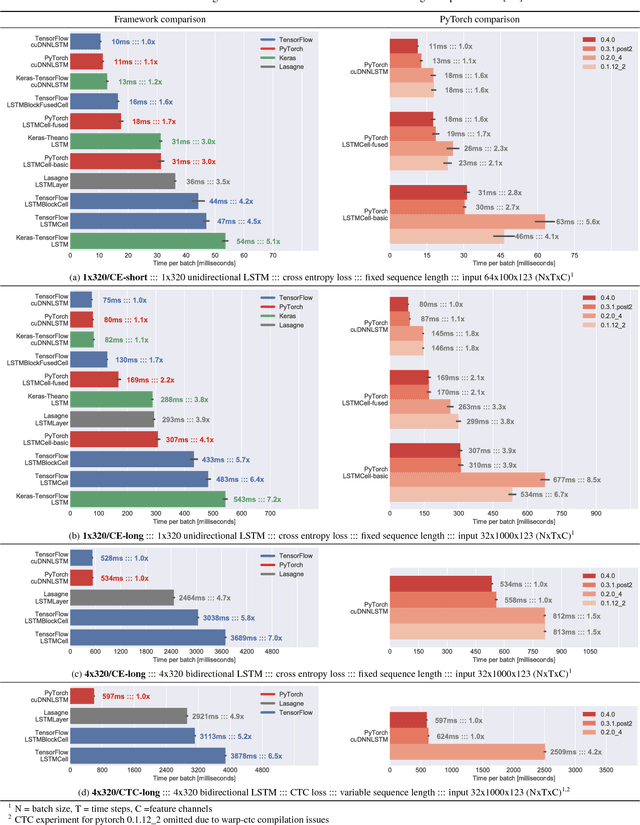
This study provides benchmarks for different implementations of LSTM units between the deep learning frameworks PyTorch, TensorFlow, Lasagne and Keras. The comparison includes cuDNN LSTMs, fused LSTM variants and less optimized, but more flexible LSTM implementations. The benchmarks reflect two typical scenarios for automatic speech recognition, notably continuous speech recognition and isolated digit recognition. These scenarios cover input sequences of fixed and variable length as well as the loss functions CTC and cross entropy. Additionally, a comparison between four different PyTorch versions is included. The code is available online https://github.com/stefbraun/rnn_benchmarks.
Sensor Transformation Attention Networks
Aug 03, 2017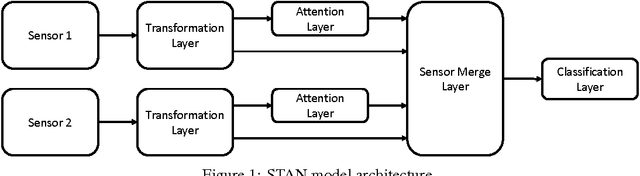

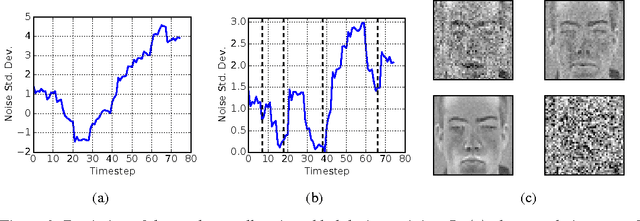
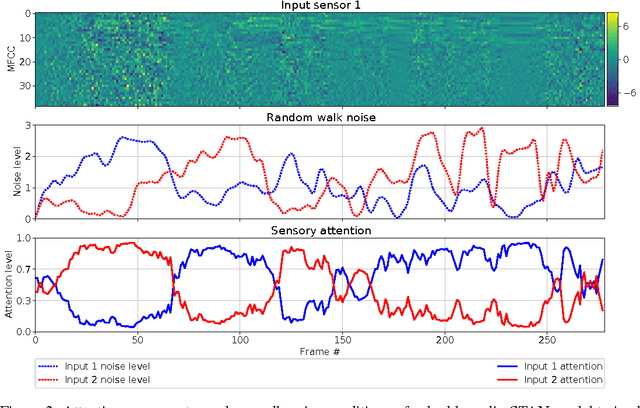
Recent work on encoder-decoder models for sequence-to-sequence mapping has shown that integrating both temporal and spatial attention mechanisms into neural networks increases the performance of the system substantially. In this work, we report on the application of an attentional signal not on temporal and spatial regions of the input, but instead as a method of switching among inputs themselves. We evaluate the particular role of attentional switching in the presence of dynamic noise in the sensors, and demonstrate how the attentional signal responds dynamically to changing noise levels in the environment to achieve increased performance on both audio and visual tasks in three commonly-used datasets: TIDIGITS, Wall Street Journal, and GRID. Moreover, the proposed sensor transformation network architecture naturally introduces a number of advantages that merit exploration, including ease of adding new sensors to existing architectures, attentional interpretability, and increased robustness in a variety of noisy environments not seen during training. Finally, we demonstrate that the sensor selection attention mechanism of a model trained only on the small TIDIGITS dataset can be transferred directly to a pre-existing larger network trained on the Wall Street Journal dataset, maintaining functionality of switching between sensors to yield a dramatic reduction of error in the presence of noise.
A Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
Sep 16, 2016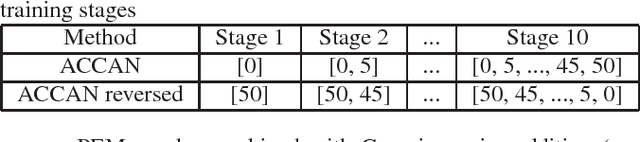
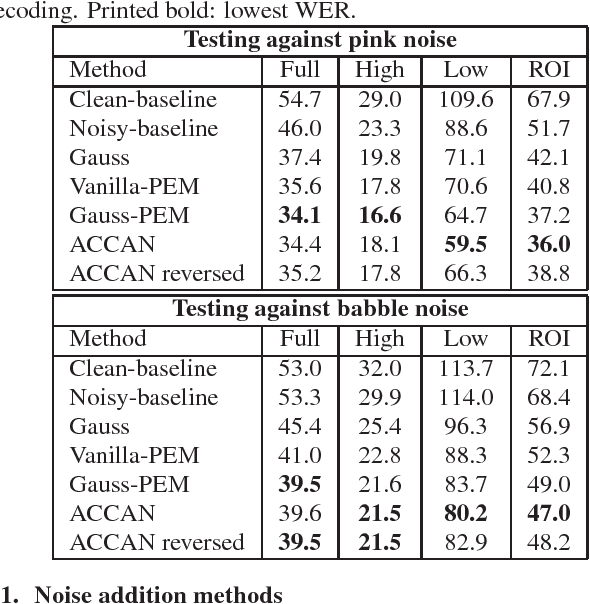
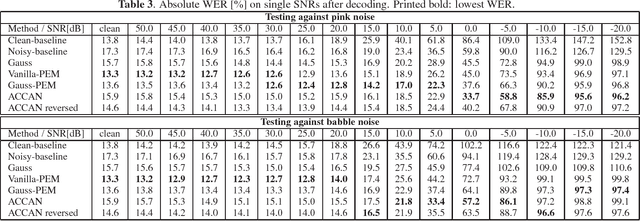
The performance of automatic speech recognition systems under noisy environments still leaves room for improvement. Speech enhancement or feature enhancement techniques for increasing noise robustness of these systems usually add components to the recognition system that need careful optimization. In this work, we propose the use of a relatively simple curriculum training strategy called accordion annealing (ACCAN). It uses a multi-stage training schedule where samples at signal-to-noise ratio (SNR) values as low as 0dB are first added and samples at increasing higher SNR values are gradually added up to an SNR value of 50dB. We also use a method called per-epoch noise mixing (PEM) that generates noisy training samples online during training and thus enables dynamically changing the SNR of our training data. Both the ACCAN and the PEM methods are evaluated on a end-to-end speech recognition pipeline on the Wall Street Journal corpus. ACCAN decreases the average word error rate (WER) on the 20dB to -10dB SNR range by up to 31.4% when compared to a conventional multi-condition training method.