 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing state updates via Gaussian-gated LSTMs
Jan 22, 2019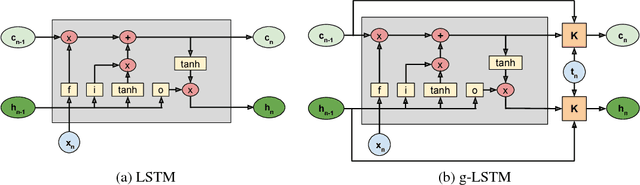

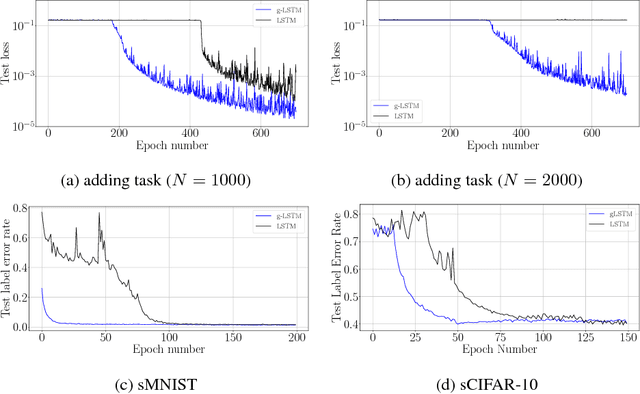
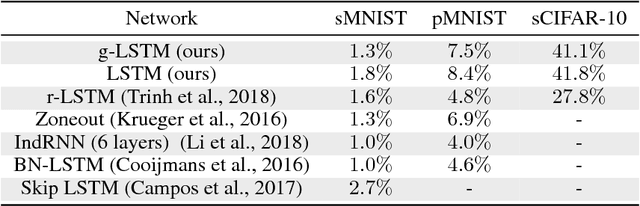
Recurrent neural networks can be difficult to train on long sequence data due to the well-known vanishing gradient problem. Some architectures incorporate methods to reduce RNN state updates, therefore allowing the network to preserve memory over long temporal intervals. To address these problems of convergence, this paper proposes a timing-gated LSTM RNN model, called the Gaussian-gated LSTM (g-LSTM). The time gate controls when a neuron can be updated during training, enabling longer memory persistence and better error-gradient flow. This model captures long-temporal dependencies better than an LSTM and the time gate parameters can be learned even from non-optimal initialization values. Because the time gate limits the updates of the neuron state, the number of computes needed for the network update is also reduced. By adding a computational budget term to the training loss, we can obtain a network which further reduces the number of computes by at least 10x. Finally, by employing a temporal curriculum learning schedule for the g-LSTM, we can reduce the convergence time of the equivalent LSTM network on long sequences.
Overcoming the vanishing gradient problem in plain recurrent networks
May 25, 2018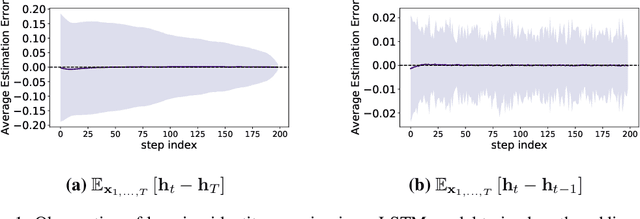
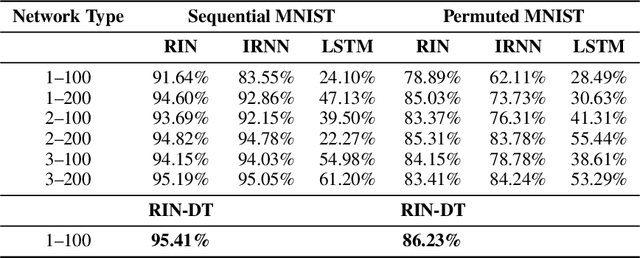
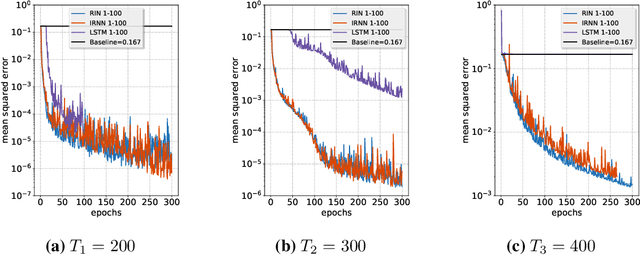

Plain recurrent networks greatly suffer from the vanishing gradient problem while Gated Neural Networks (GNNs) such as Long-short Term Memory (LSTM) and Gated Recurrent Unit (GRU) deliver promising results in many sequence learning tasks through sophisticated network designs. This paper shows how we can address this problem in a plain recurrent network by analyzing the gating mechanisms in GNNs. We propose a novel network called the Recurrent Identity Network (RIN) which allows a plain recurrent network to overcome the vanishing gradient problem while training very deep models without the use of gates. We compare this model with IRNNs and LSTMs on multiple sequence modeling benchmarks. The RINs demonstrate competitive performance and converge faster in all tasks. Notably, small RIN models produce 12%--67% higher accuracy on the Sequential and Permuted MNIST datasets and reach state-of-the-art performance on the bAbI question answering dataset.
Sensor Transformation Attention Networks
Aug 03, 2017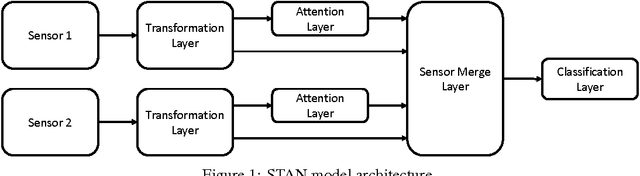

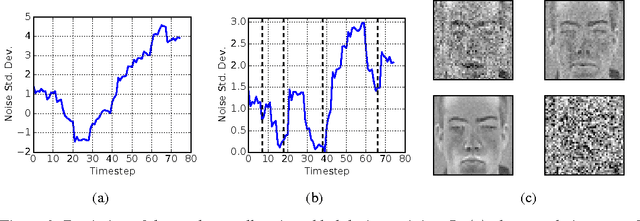
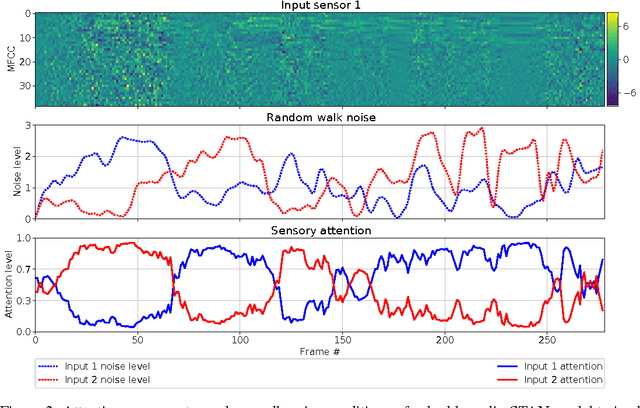
Recent work on encoder-decoder models for sequence-to-sequence mapping has shown that integrating both temporal and spatial attention mechanisms into neural networks increases the performance of the system substantially. In this work, we report on the application of an attentional signal not on temporal and spatial regions of the input, but instead as a method of switching among inputs themselves. We evaluate the particular role of attentional switching in the presence of dynamic noise in the sensors, and demonstrate how the attentional signal responds dynamically to changing noise levels in the environment to achieve increased performance on both audio and visual tasks in three commonly-used datasets: TIDIGITS, Wall Street Journal, and GRID. Moreover, the proposed sensor transformation network architecture naturally introduces a number of advantages that merit exploration, including ease of adding new sensors to existing architectures, attentional interpretability, and increased robustness in a variety of noisy environments not seen during training. Finally, we demonstrate that the sensor selection attention mechanism of a model trained only on the small TIDIGITS dataset can be transferred directly to a pre-existing larger network trained on the Wall Street Journal dataset, maintaining functionality of switching between sensors to yield a dramatic reduction of error in the presence of noise.