 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term stable Electromyography classification using Canonical Correlation Analysis
Jan 23, 2023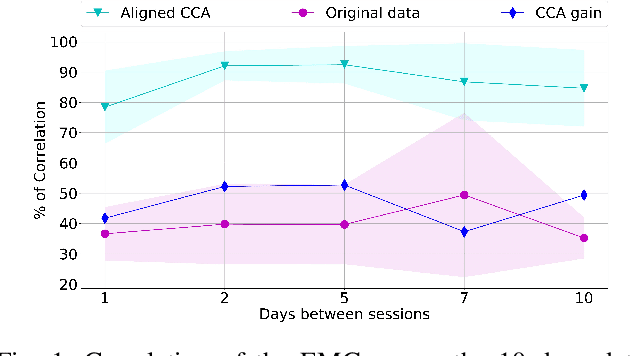
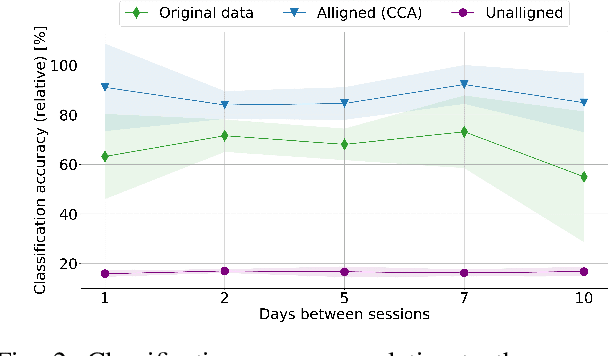
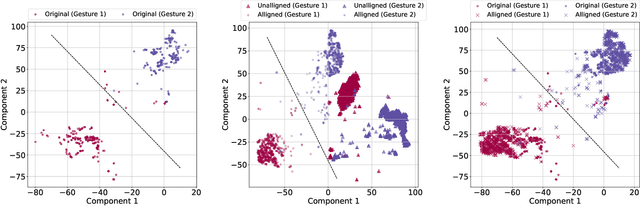
Discrimination of hand gestures based on the decoding of surface electromyography (sEMG) signals is a well-establish approach for controlling prosthetic devices and for Human-Machine Interfaces (HMI). However, despite the promising results achieved by this approach in well-controlled experimental conditions, its deployment in long-term real-world application scenarios is still hindered by several challenges. One of the most critical challenges is maintaining high EMG data classification performance across multiple days without retraining the decoding system. The drop in performance is mostly due to the high EMG variability caused by electrodes shift, muscle artifacts, fatigue, user adaptation, or skin-electrode interfacing issues. Here we propose a novel statistical method based on canonical correlation analysis (CCA) that stabilizes EMG classification performance across multiple days for long-term control of prosthetic devices. We show how CCA can dramatically decrease the performance drop of standard classifiers observed across days, by maximizing the correlation among multiple-day acquisition data sets. Our results show how the performance of a classifier trained on EMG data acquired only of the first day of the experiment maintains 90% relative accuracy across multiple days, compensating for the EMG data variability that occurs over long-term periods, using the CCA transformation on data obtained from a small number of gestures. This approach eliminates the need for large data sets and multiple or periodic training sessions, which currently hamper the usability of conventional pattern recognition based approaches
Sensor fusion using EMG and vision for hand gesture classification in mobile applications
Oct 19, 2019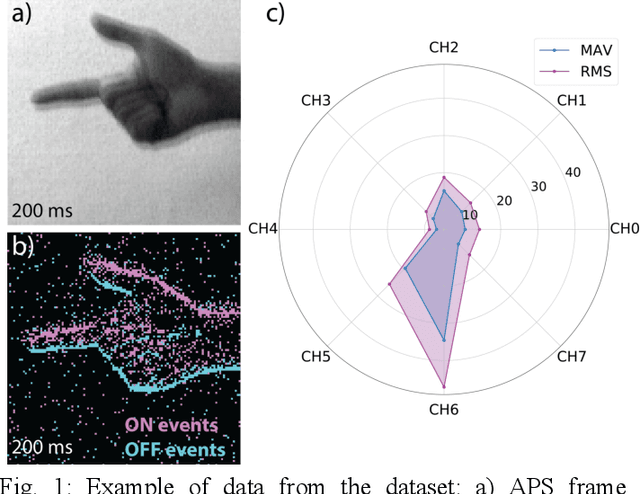
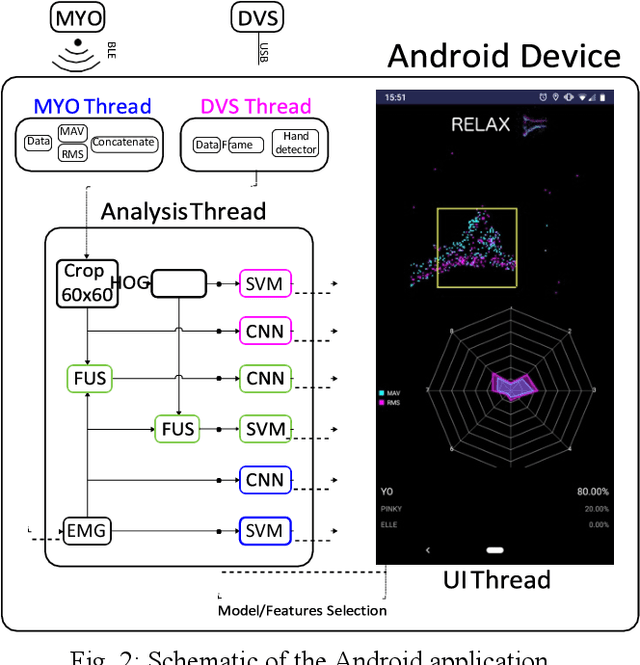
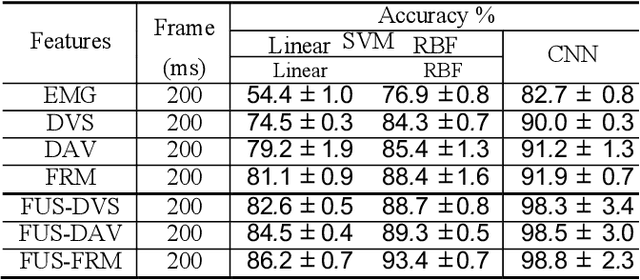
The discrimination of human gestures using wearable solutions is extremely important as a supporting technique for assisted living, healthcare of the elderly and neurorehabilitation. This paper presents a mobile electromyography (EMG) analysis framework to be an auxiliary component in physiotherapy sessions or as a feedback for neuroprosthesis calibration. We implemented a framework that allows the integration of multisensors, EMG and visual information, to perform sensor fusion and to improve the accuracy of hand gesture recognition tasks. In particular, we used an event-based camera adapted to run on the limited computational resources of mobile phones. We introduced a new publicly available dataset of sensor fusion for hand gesture recognition recorded from 10 subjects and used it to train the recognition models offline. We compare the online results of the hand gesture recognition using the fusion approach with the individual sensors with an improvement in the accuracy of 13% and 11%, for EMG and vision respectively, reaching 85%.
FaSNet: Low-latency Adaptive Beamforming for Multi-microphone Audio Processing
Oct 01, 2019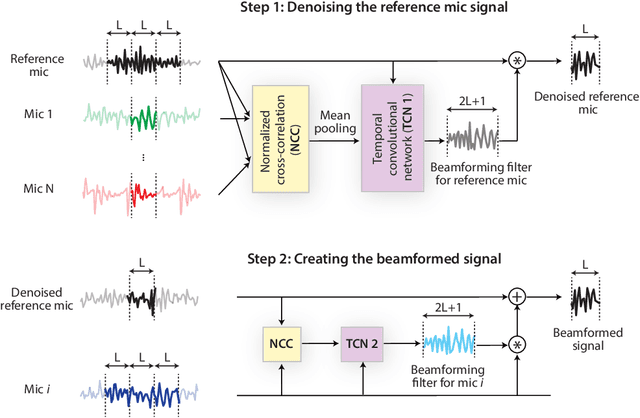
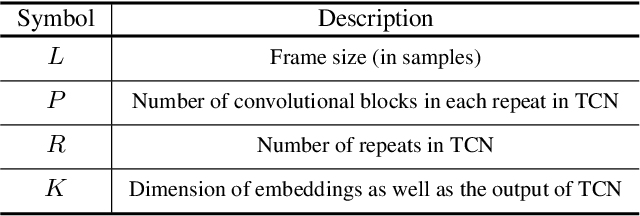
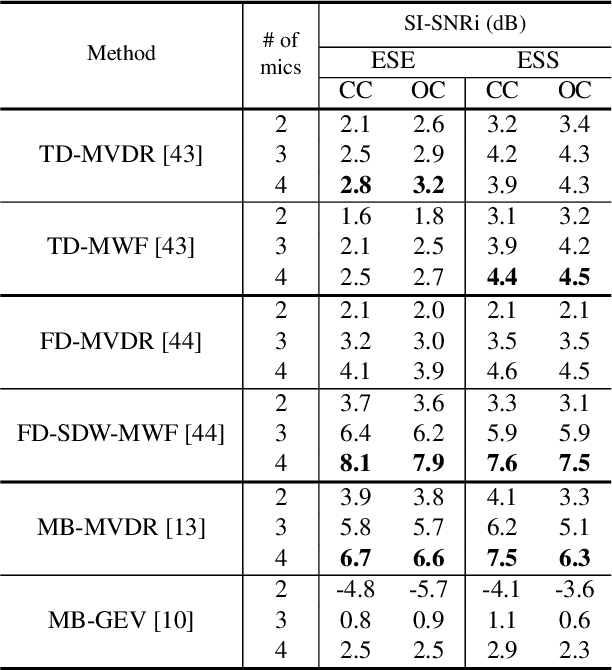
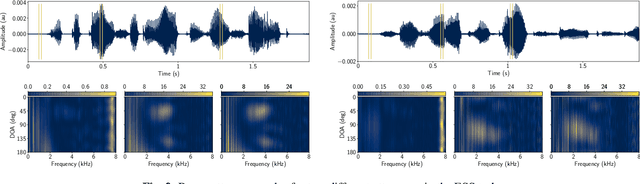
Beamforming has been extensively investigated for multi-channel audio processing tasks. Recently, learning-based beamforming methods, sometimes called \textit{neural beamformers}, have achieved significant improvements in both signal quality (e.g. signal-to-noise ratio (SNR)) and speech recognition (e.g. word error rate (WER)). Such systems are generally non-causal and require a large context for robust estimation of inter-channel features, which is impractical in applications requiring low-latency responses. In this paper, we propose filter-and-sum network (FaSNet), a time-domain, filter-based beamforming approach suitable for low-latency scenarios. FaSNet has a two-stage system design that first learns frame-level time-domain adaptive beamforming filters for a selected reference channel, and then calculate the filters for all remaining channels. The filtered outputs at all channels are summed to generate the final output. Experiments show that despite its small model size, FaSNet is able to outperform several traditional oracle beamformers with respect to scale-invariant signal-to-noise ratio (SI-SNR) in reverberant speech enhancement and separation tasks. Moreover, when trained with a frequency-domain objective function on the CHiME-3 dataset, FaSNet achieves 14.3\% relative word error rate reduction (RWERR) compared with the baseline model. These results show the efficacy of FaSNet particularly in reverberant and noisy signal conditions.
Towards better understanding of gradient-based attribution methods for Deep Neural Networks
Mar 07, 2018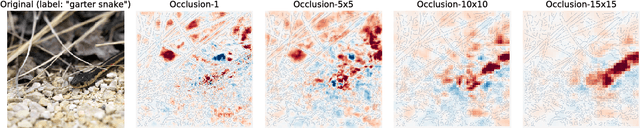
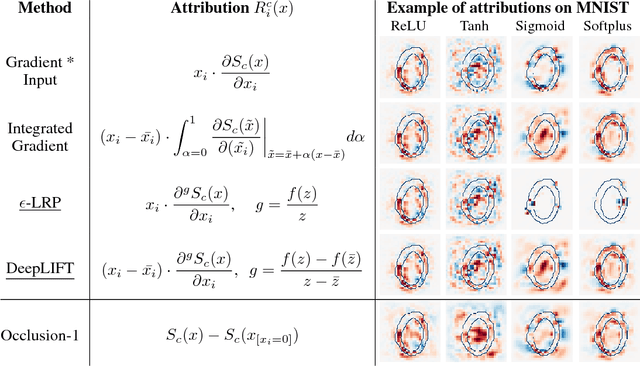


Understanding the flow of information in Deep Neural Networks (DNNs) is a challenging problem that has gain increasing attention over the last few years. While several methods have been proposed to explain network predictions, there have been only a few attempts to compare them from a theoretical perspective. What is more, no exhaustive empirical comparison has been performed in the past. In this work, we analyze four gradient-based attribution methods and formally prove conditions of equivalence and approximation between them. By reformulating two of these methods, we construct a unified framework which enables a direct comparison, as well as an easier implementation. Finally, we propose a novel evaluation metric, called Sensitivity-n and test the gradient-based attribution methods alongside with a simple perturbation-based attribution method on several datasets in the domains of image and text classification, using various network architectures.
Sensor Transformation Attention Networks
Aug 03, 2017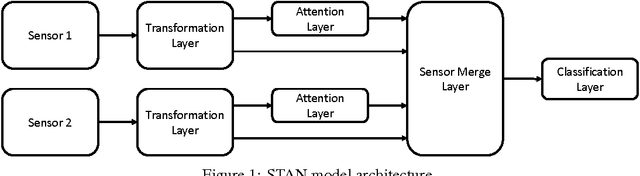

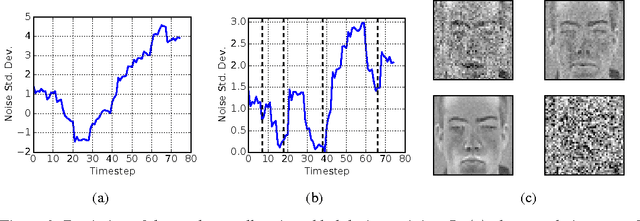
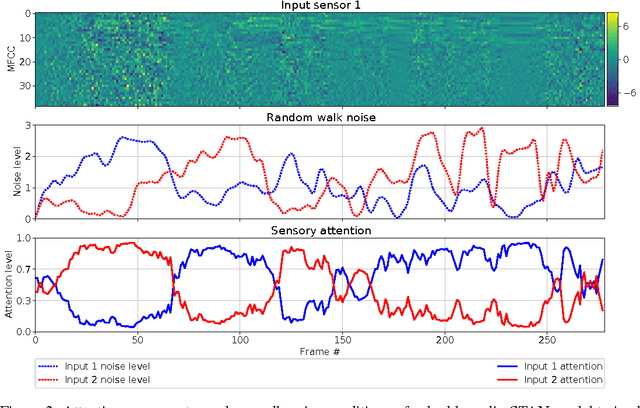
Recent work on encoder-decoder models for sequence-to-sequence mapping has shown that integrating both temporal and spatial attention mechanisms into neural networks increases the performance of the system substantially. In this work, we report on the application of an attentional signal not on temporal and spatial regions of the input, but instead as a method of switching among inputs themselves. We evaluate the particular role of attentional switching in the presence of dynamic noise in the sensors, and demonstrate how the attentional signal responds dynamically to changing noise levels in the environment to achieve increased performance on both audio and visual tasks in three commonly-used datasets: TIDIGITS, Wall Street Journal, and GRID. Moreover, the proposed sensor transformation network architecture naturally introduces a number of advantages that merit exploration, including ease of adding new sensors to existing architectures, attentional interpretability, and increased robustness in a variety of noisy environments not seen during training. Finally, we demonstrate that the sensor selection attention mechanism of a model trained only on the small TIDIGITS dataset can be transferred directly to a pre-existing larger network trained on the Wall Street Journal dataset, maintaining functionality of switching between sensors to yield a dramatic reduction of error in the presence of noise.