 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDD20 End-to-End Event Camera Driving Dataset: Fusing Frames and Events with Deep Learning for Improved Steering Prediction
May 18, 2020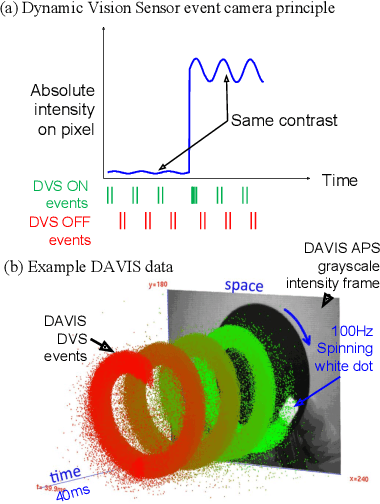



Neuromorphic event cameras are useful for dynamic vision problems under difficult lighting conditions. To enable studies of using event cameras in automobile driving applications, this paper reports a new end-to-end driving dataset called DDD20. The dataset was captured with a DAVIS camera that concurrently streams both dynamic vision sensor (DVS) brightness change events and active pixel sensor (APS) intensity frames. DDD20 is the longest event camera end-to-end driving dataset to date with 51h of DAVIS event+frame camera and vehicle human control data collected from 4000km of highway and urban driving under a variety of lighting conditions. Using DDD20, we report the first study of fusing brightness change events and intensity frame data using a deep learning approach to predict the instantaneous human steering wheel angle. Over all day and night conditions, the explained variance for human steering prediction from a Resnet-32 is significantly better from the fused DVS+APS frames (0.88) than using either DVS (0.67) or APS (0.77) data alone.
Interpretable Graph Convolutional Neural Networks for Inference on Noisy Knowledge Graphs
Dec 01, 2018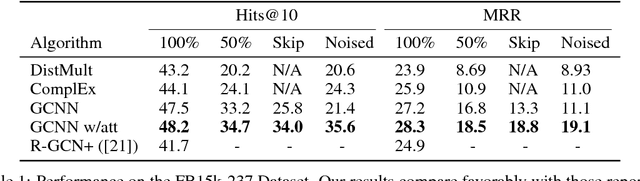
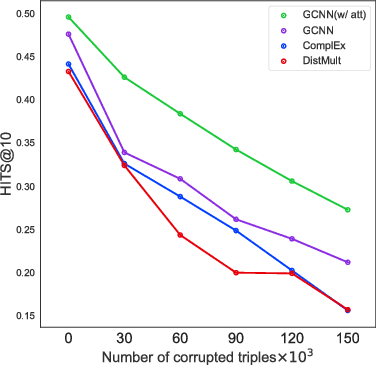
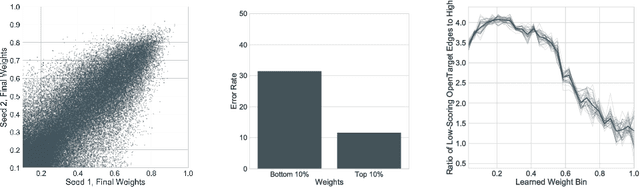
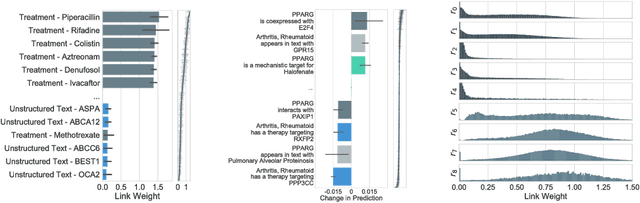
In this work, we provide a new formulation for Graph Convolutional Neural Networks (GCNNs) for link prediction on graph data that addresses common challenges for biomedical knowledge graphs (KGs). We introduce a regularized attention mechanism to GCNNs that not only improves performance on clean datasets, but also favorably accommodates noise in KGs, a pervasive issue in real-world applications. Further, we explore new visualization methods for interpretable modelling and to illustrate how the learned representation can be exploited to automate dataset denoising. The results are demonstrated on a synthetic dataset, the common benchmark dataset FB15k-237, and a large biomedical knowledge graph derived from a combination of noisy and clean data sources. Using these improvements, we visualize a learned model's representation of the disease cystic fibrosis and demonstrate how to interrogate a neural network to show the potential of PPARG as a candidate therapeutic target for rheumatoid arthritis.
PRED18: Dataset and Further Experiments with DAVIS Event Camera in Predator-Prey Robot Chasing
Jul 02, 2018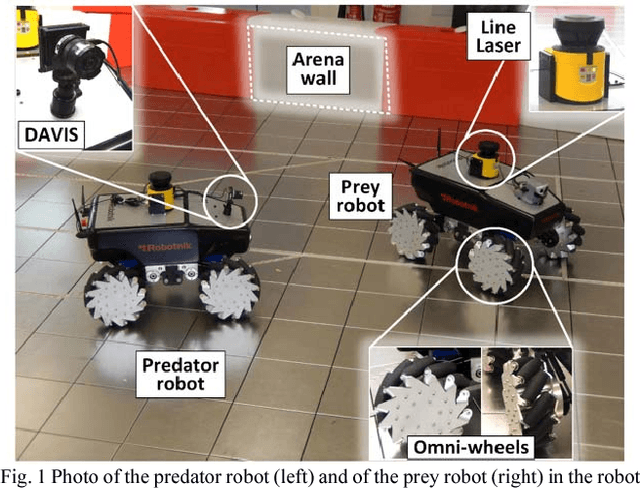
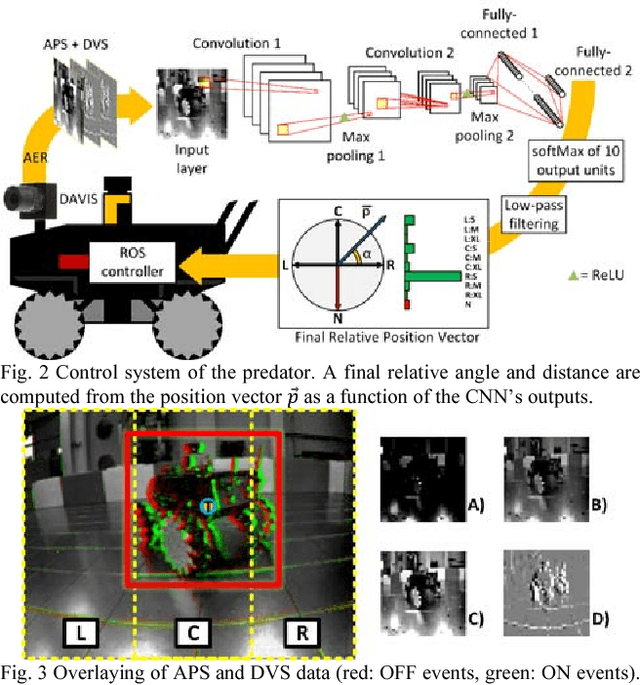

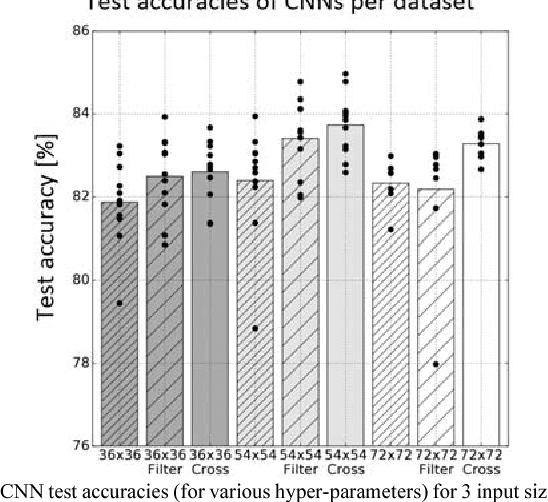
Machine vision systems using convolutional neural networks (CNNs) for robotic applications are increasingly being developed. Conventional vision CNNs are driven by camera frames at constant sample rate, thus achieving a fixed latency and power consumption tradeoff. This paper describes further work on the first experiments of a closed-loop robotic system integrating a CNN together with a Dynamic and Active Pixel Vision Sensor (DAVIS) in a predator/prey scenario. The DAVIS, mounted on the predator Summit XL robot, produces frames at a fixed 15 Hz frame-rate and Dynamic Vision Sensor (DVS) histograms containing 5k ON and OFF events at a variable frame-rate ranging from 15-500 Hz depending on the robot speeds. In contrast to conventional frame-based systems, the latency and processing cost depends on the rate of change of the image. The CNN is trained offline on the 1.25h labeled dataset to recognize the position and size of the prey robot, in the field of view of the predator. During inference, combining the ten output classes of the CNN allows extracting the analog position vector of the prey relative to the predator with a mean 8.7% error in angular estimation. The system is compatible with conventional deep learning technology, but achieves a variable latency-power tradeoff that adapts automatically to the dynamics. Finally, investigations on the robustness of the algorithm, a human performance comparison and a deconvolution analysis are also explored.
* 8 pages
ADaPTION: Toolbox and Benchmark for Training Convolutional Neural Networks with Reduced Numerical Precision Weights and Activation
Nov 13, 2017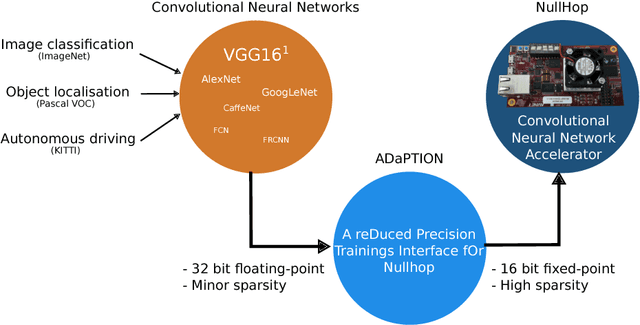
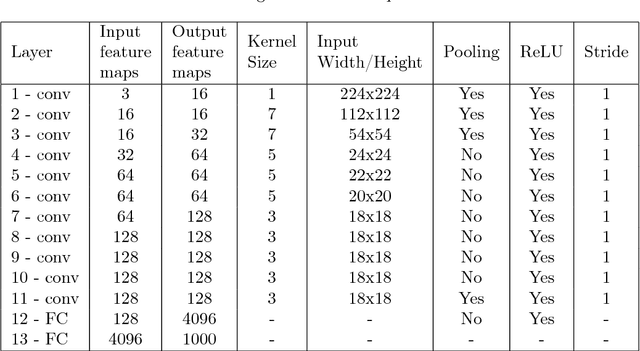
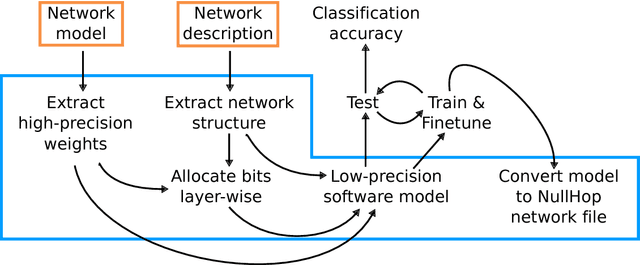
Deep Neural Networks (DNNs) and Convolutional Neural Networks (CNNs) are useful for many practical tasks in machine learning. Synaptic weights, as well as neuron activation functions within the deep network are typically stored with high-precision formats, e.g. 32 bit floating point. However, since storage capacity is limited and each memory access consumes power, both storage capacity and memory access are two crucial factors in these networks. Here we present a method and present the ADaPTION toolbox to extend the popular deep learning library Caffe to support training of deep CNNs with reduced numerical precision of weights and activations using fixed point notation. ADaPTION includes tools to measure the dynamic range of weights and activations. Using the ADaPTION tools, we quantized several CNNs including VGG16 down to 16-bit weights and activations with only 0.8% drop in Top-1 accuracy. The quantization, especially of the activations, leads to increase of up to 50% of sparsity especially in early and intermediate layers, which we exploit to skip multiplications with zero, thus performing faster and computationally cheaper inference.
DDD17: End-To-End DAVIS Driving Dataset
Nov 04, 2017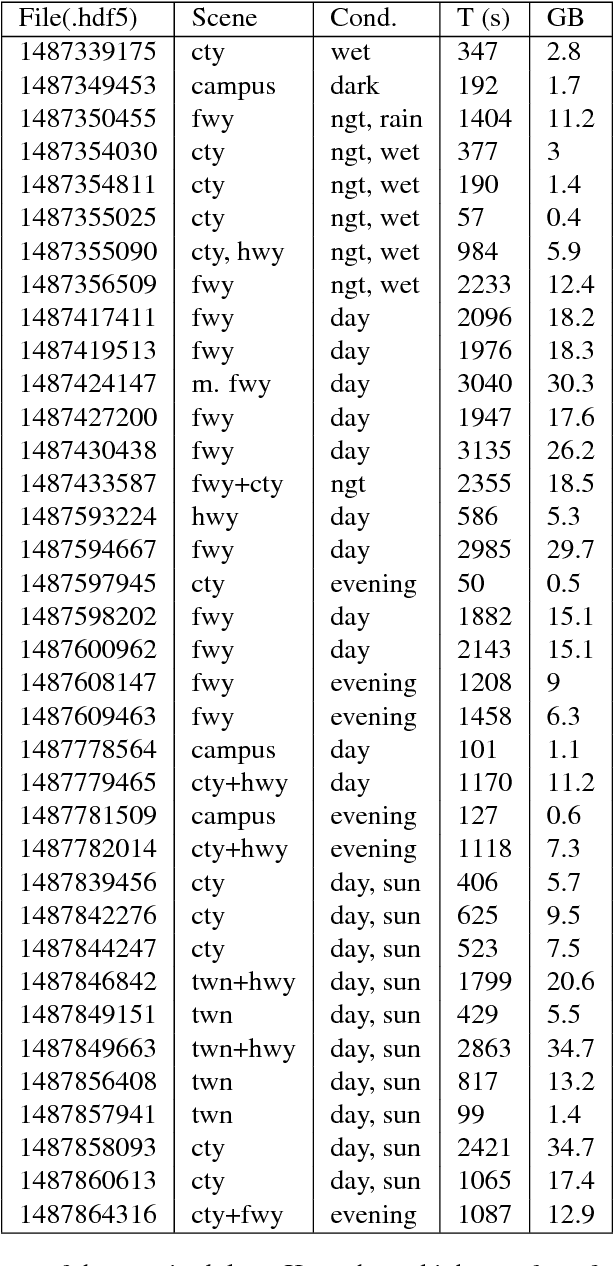

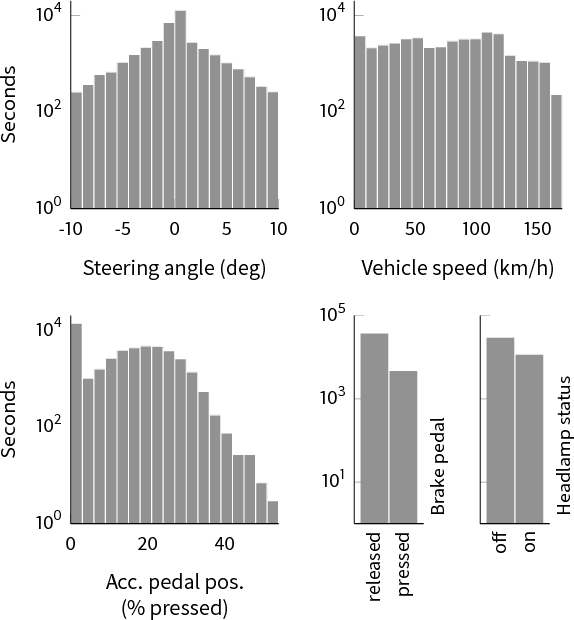
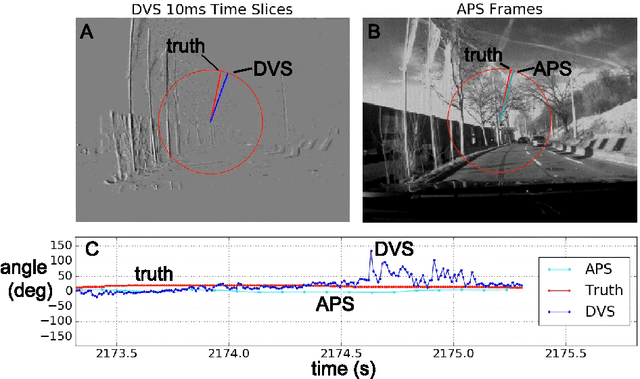
Event cameras, such as dynamic vision sensors (DVS), and dynamic and active-pixel vision sensors (DAVIS) can supplement other autonomous driving sensors by providing a concurrent stream of standard active pixel sensor (APS) images and DVS temporal contrast events. The APS stream is a sequence of standard grayscale global-shutter image sensor frames. The DVS events represent brightness changes occurring at a particular moment, with a jitter of about a millisecond under most lighting conditions. They have a dynamic range of >120 dB and effective frame rates >1 kHz at data rates comparable to 30 fps (frames/second) image sensors. To overcome some of the limitations of current image acquisition technology, we investigate in this work the use of the combined DVS and APS streams in end-to-end driving applications. The dataset DDD17 accompanying this paper is the first open dataset of annotated DAVIS driving recordings. DDD17 has over 12 h of a 346x260 pixel DAVIS sensor recording highway and city driving in daytime, evening, night, dry and wet weather conditions, along with vehicle speed, GPS position, driver steering, throttle, and brake captured from the car's on-board diagnostics interface. As an example application, we performed a preliminary end-to-end learning study of using a convolutional neural network that is trained to predict the instantaneous steering angle from DVS and APS visual data.
Sensor Transformation Attention Networks
Aug 03, 2017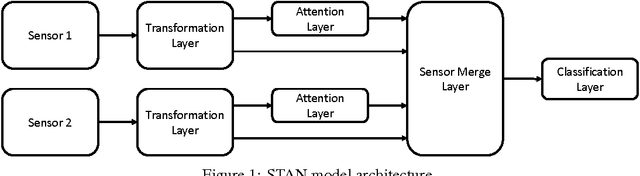

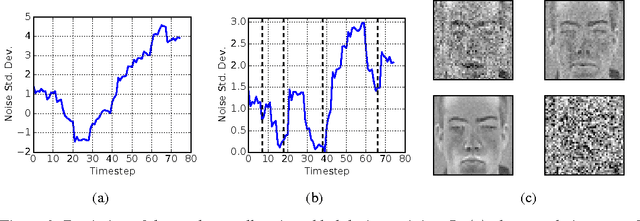
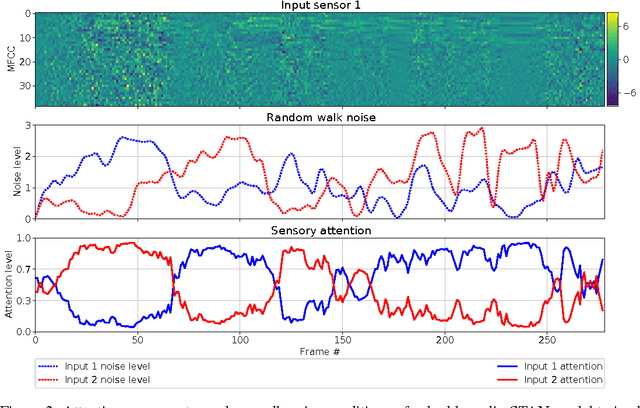
Recent work on encoder-decoder models for sequence-to-sequence mapping has shown that integrating both temporal and spatial attention mechanisms into neural networks increases the performance of the system substantially. In this work, we report on the application of an attentional signal not on temporal and spatial regions of the input, but instead as a method of switching among inputs themselves. We evaluate the particular role of attentional switching in the presence of dynamic noise in the sensors, and demonstrate how the attentional signal responds dynamically to changing noise levels in the environment to achieve increased performance on both audio and visual tasks in three commonly-used datasets: TIDIGITS, Wall Street Journal, and GRID. Moreover, the proposed sensor transformation network architecture naturally introduces a number of advantages that merit exploration, including ease of adding new sensors to existing architectures, attentional interpretability, and increased robustness in a variety of noisy environments not seen during training. Finally, we demonstrate that the sensor selection attention mechanism of a model trained only on the small TIDIGITS dataset can be transferred directly to a pre-existing larger network trained on the Wall Street Journal dataset, maintaining functionality of switching between sensors to yield a dramatic reduction of error in the presence of noise.
Delta Networks for Optimized Recurrent Network Computation
Dec 16, 2016
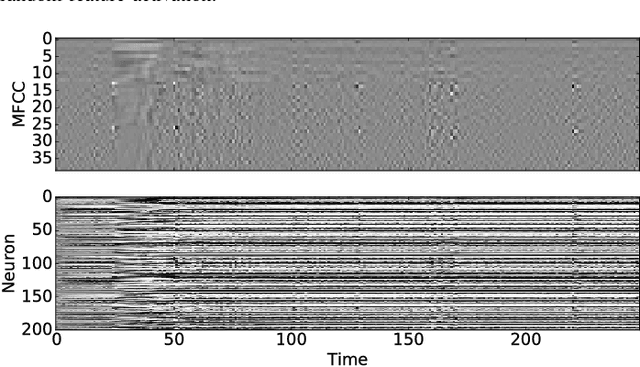
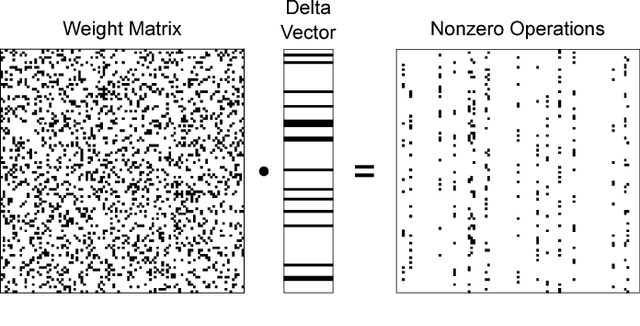
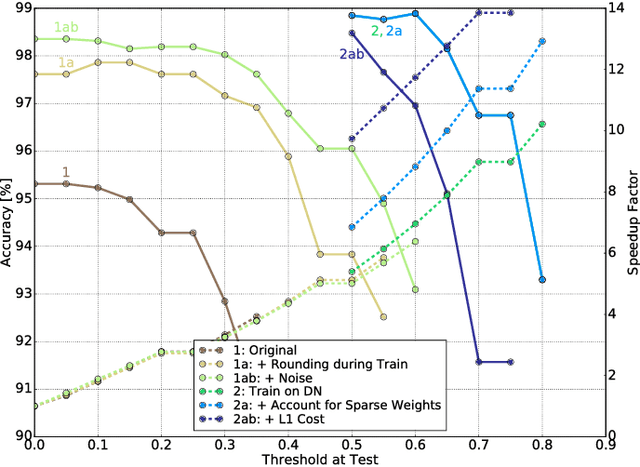
Many neural networks exhibit stability in their activation patterns over time in response to inputs from sensors operating under real-world conditions. By capitalizing on this property of natural signals, we propose a Recurrent Neural Network (RNN) architecture called a delta network in which each neuron transmits its value only when the change in its activation exceeds a threshold. The execution of RNNs as delta networks is attractive because their states must be stored and fetched at every timestep, unlike in convolutional neural networks (CNNs). We show that a naive run-time delta network implementation offers modest improvements on the number of memory accesses and computes, but optimized training techniques confer higher accuracy at higher speedup. With these optimizations, we demonstrate a 9X reduction in cost with negligible loss of accuracy for the TIDIGITS audio digit recognition benchmark. Similarly, on the large Wall Street Journal speech recognition benchmark even existing networks can be greatly accelerated as delta networks, and a 5.7x improvement with negligible loss of accuracy can be obtained through training. Finally, on an end-to-end CNN trained for steering angle prediction in a driving dataset, the RNN cost can be reduced by a substantial 100X.
Phased LSTM: Accelerating Recurrent Network Training for Long or Event-based Sequences
Oct 29, 2016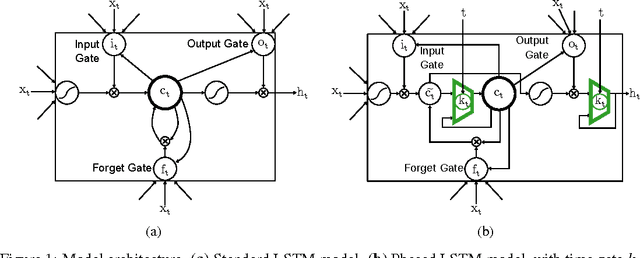
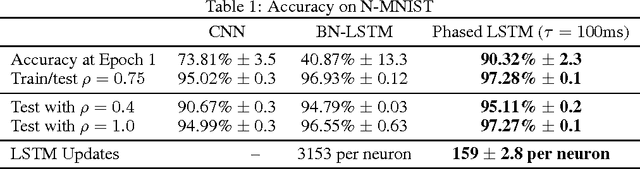
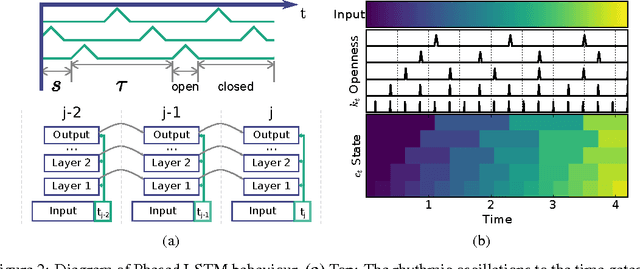
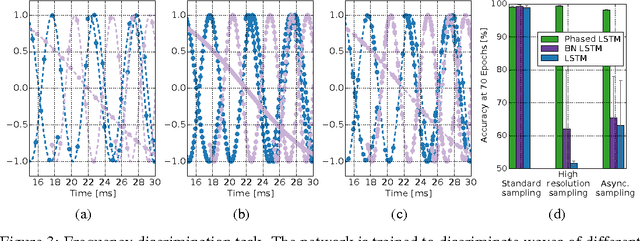
Recurrent Neural Networks (RNNs) have become the state-of-the-art choice for extracting patterns from temporal sequences. However, current RNN models are ill-suited to process irregularly sampled data triggered by events generated in continuous time by sensors or other neurons. Such data can occur, for example, when the input comes from novel event-driven artificial sensors that generate sparse, asynchronous streams of events or from multiple conventional sensors with different update intervals. In this work, we introduce the Phased LSTM model, which extends the LSTM unit by adding a new time gate. This gate is controlled by a parametrized oscillation with a frequency range that produces updates of the memory cell only during a small percentage of the cycle. Even with the sparse updates imposed by the oscillation, the Phased LSTM network achieves faster convergence than regular LSTMs on tasks which require learning of long sequences. The model naturally integrates inputs from sensors of arbitrary sampling rates, thereby opening new areas of investigation for processing asynchronous sensory events that carry timing information. It also greatly improves the performance of LSTMs in standard RNN applications, and does so with an order-of-magnitude fewer computes at runtime.
A Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
Sep 16, 2016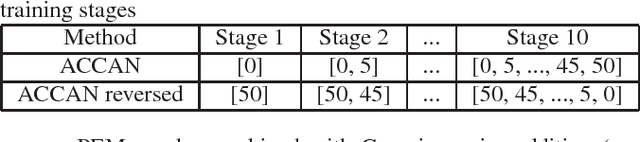
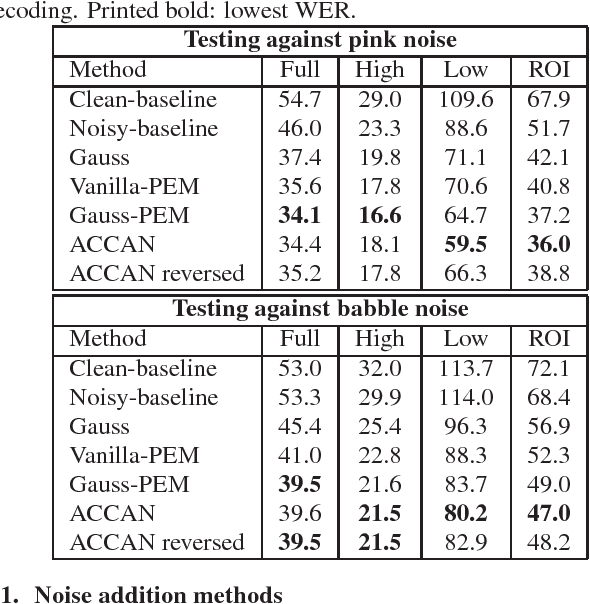
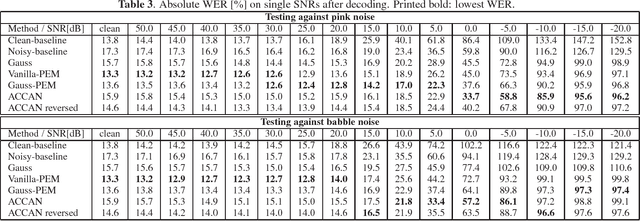
The performance of automatic speech recognition systems under noisy environments still leaves room for improvement. Speech enhancement or feature enhancement techniques for increasing noise robustness of these systems usually add components to the recognition system that need careful optimization. In this work, we propose the use of a relatively simple curriculum training strategy called accordion annealing (ACCAN). It uses a multi-stage training schedule where samples at signal-to-noise ratio (SNR) values as low as 0dB are first added and samples at increasing higher SNR values are gradually added up to an SNR value of 50dB. We also use a method called per-epoch noise mixing (PEM) that generates noisy training samples online during training and thus enables dynamically changing the SNR of our training data. Both the ACCAN and the PEM methods are evaluated on a end-to-end speech recognition pipeline on the Wall Street Journal corpus. ACCAN decreases the average word error rate (WER) on the 20dB to -10dB SNR range by up to 31.4% when compared to a conventional multi-condition training method.
Steering a Predator Robot using a Mixed Frame/Event-Driven Convolutional Neural Network
Jun 30, 2016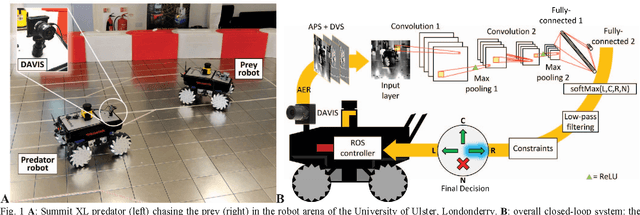


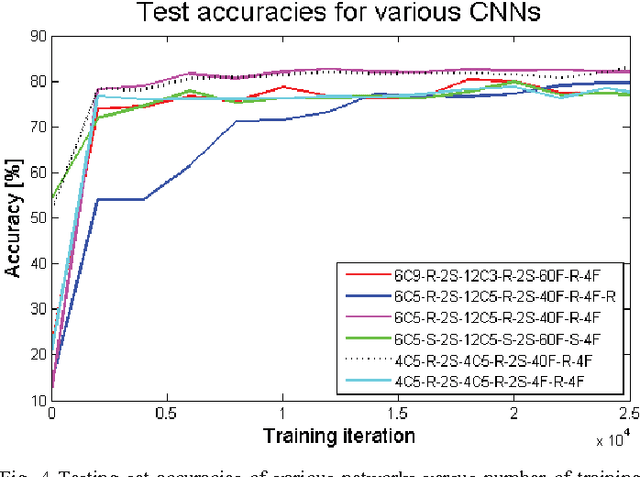
This paper describes the application of a Convolutional Neural Network (CNN) in the context of a predator/prey scenario. The CNN is trained and run on data from a Dynamic and Active Pixel Sensor (DAVIS) mounted on a Summit XL robot (the predator), which follows another one (the prey). The CNN is driven by both conventional image frames and dynamic vision sensor "frames" that consist of a constant number of DAVIS ON and OFF events. The network is thus "data driven" at a sample rate proportional to the scene activity, so the effective sample rate varies from 15 Hz to 240 Hz depending on the robot speeds. The network generates four outputs: steer right, left, center and non-visible. After off-line training on labeled data, the network is imported on the on-board Summit XL robot which runs jAER and receives steering directions in real time. Successful results on closed-loop trials, with accuracies up to 87% or 92% (depending on evaluation criteria) are reported. Although the proposed approach discards the precise DAVIS event timing, it offers the significant advantage of compatibility with conventional deep learning technology without giving up the advantage of data-driven computing.