 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization for Rapid Deployment of Deep Neural Networks
Oct 12, 2018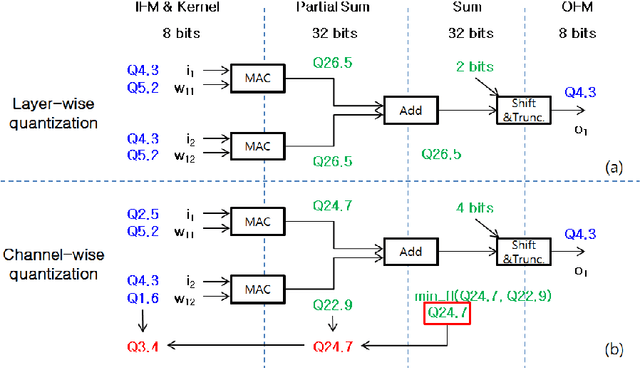
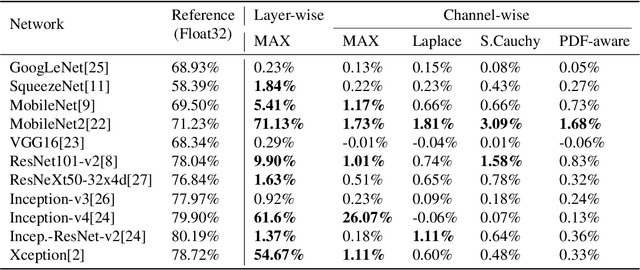
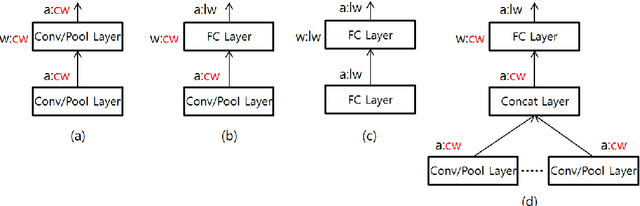

This paper aims at rapid deployment of the state-of-the-art deep neural networks (DNNs) to energy efficient accelerators without time-consuming fine tuning or the availability of the full datasets. Converting DNNs in full precision to limited precision is essential in taking advantage of the accelerators with reduced memory footprint and computation power. However, such a task is not trivial since it often requires the full training and validation datasets for profiling the network statistics and fine tuning the networks to recover the accuracy lost after quantization. To address these issues, we propose a simple method recognizing channel-level distribution to reduce the quantization-induced accuracy loss and minimize the required image samples for profiling. We evaluated our method on eleven networks trained on the ImageNet classification benchmark and a network trained on the Pascal VOC object detection benchmark. The results prove that the networks can be quantized into 8-bit integer precision without fine tuning.
Training Deep Neural Network in Limited Precision
Oct 12, 2018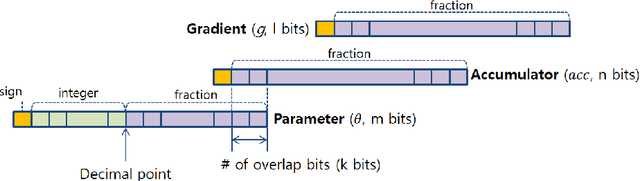
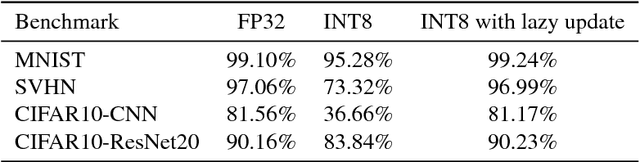
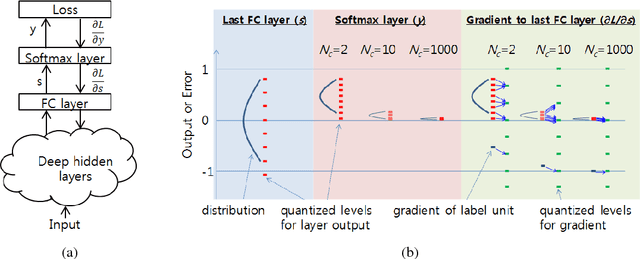
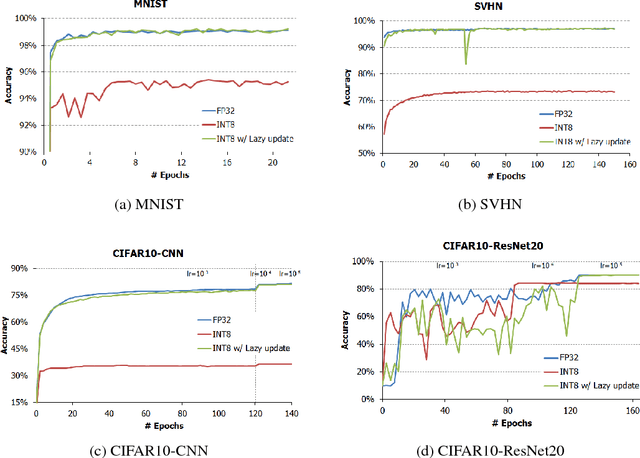
Energy and resource efficient training of DNNs will greatly extend the applications of deep learning. However, there are three major obstacles which mandate accurate calculation in high precision. In this paper, we tackle two of them related to the loss of gradients during parameter update and backpropagation through a softmax nonlinearity layer in low precision training. We implemented SGD with Kahan summation by employing an additional parameter to virtually extend the bit-width of the parameters for a reliable parameter update. We also proposed a simple guideline to help select the appropriate bit-width for the last FC layer followed by a softmax nonlinearity layer. It determines the lower bound of the required bit-width based on the class size of the dataset. Extensive experiments on various network architectures and benchmarks verifies the effectiveness of the proposed technique for low precision training.
Delta Networks for Optimized Recurrent Network Computation
Dec 16, 2016
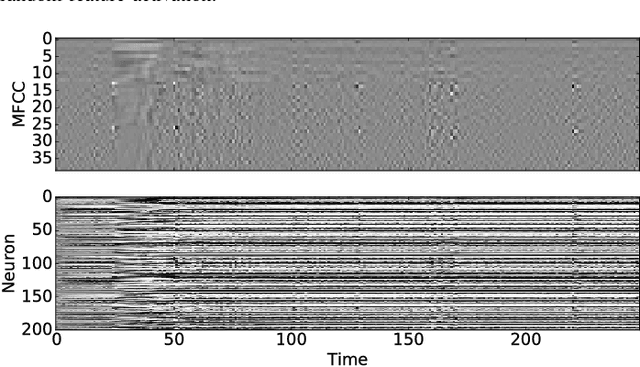
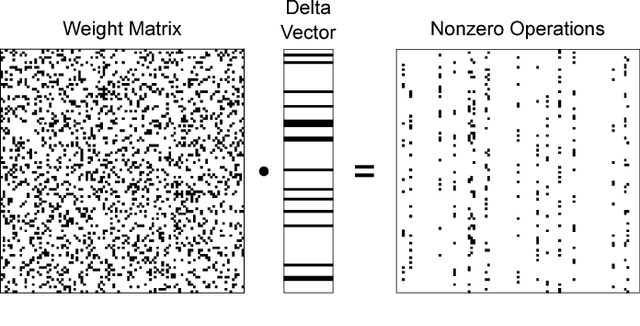
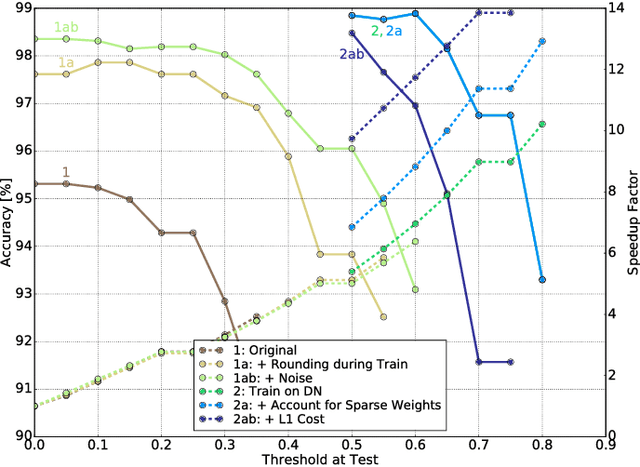
Many neural networks exhibit stability in their activation patterns over time in response to inputs from sensors operating under real-world conditions. By capitalizing on this property of natural signals, we propose a Recurrent Neural Network (RNN) architecture called a delta network in which each neuron transmits its value only when the change in its activation exceeds a threshold. The execution of RNNs as delta networks is attractive because their states must be stored and fetched at every timestep, unlike in convolutional neural networks (CNNs). We show that a naive run-time delta network implementation offers modest improvements on the number of memory accesses and computes, but optimized training techniques confer higher accuracy at higher speedup. With these optimizations, we demonstrate a 9X reduction in cost with negligible loss of accuracy for the TIDIGITS audio digit recognition benchmark. Similarly, on the large Wall Street Journal speech recognition benchmark even existing networks can be greatly accelerated as delta networks, and a 5.7x improvement with negligible loss of accuracy can be obtained through training. Finally, on an end-to-end CNN trained for steering angle prediction in a driving dataset, the RNN cost can be reduced by a substantial 100X.
Training Deep Spiking Neural Networks using Backpropagation
Aug 31, 2016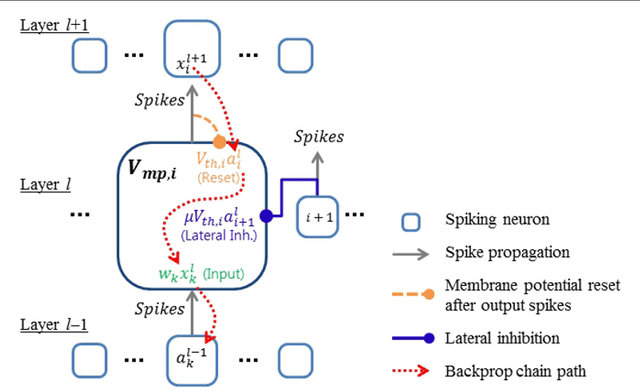
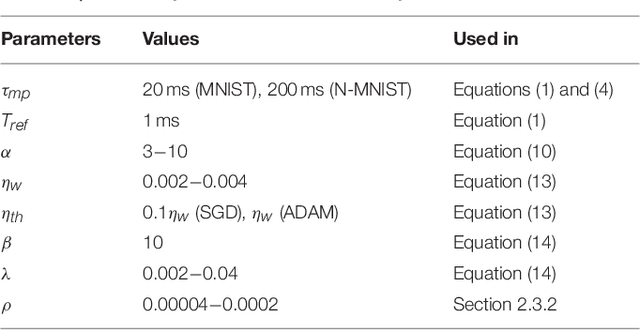

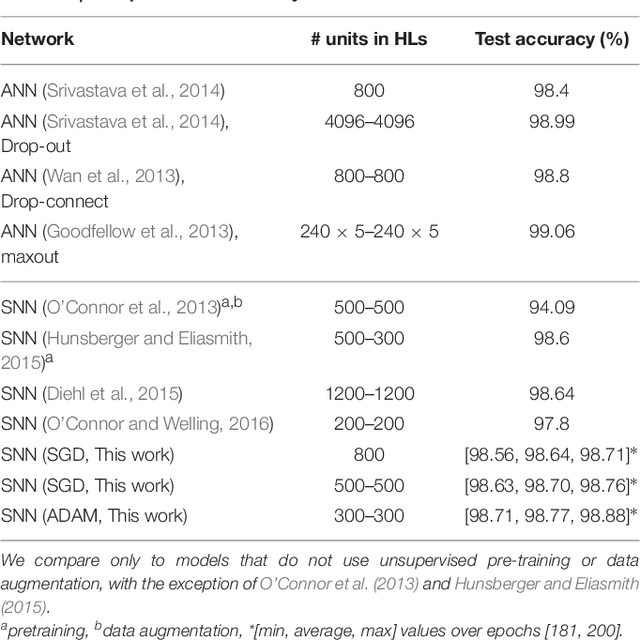
Deep spiking neural networks (SNNs) hold great potential for improving the latency and energy efficiency of deep neural networks through event-based computation. However, training such networks is difficult due to the non-differentiable nature of asynchronous spike events. In this paper, we introduce a novel technique, which treats the membrane potentials of spiking neurons as differentiable signals, where discontinuities at spike times are only considered as noise. This enables an error backpropagation mechanism for deep SNNs, which works directly on spike signals and membrane potentials. Thus, compared with previous methods relying on indirect training and conversion, our technique has the potential to capture the statics of spikes more precisely. Our novel framework outperforms all previously reported results for SNNs on the permutation invariant MNIST benchmark, as well as the N-MNIST benchmark recorded with event-based vision sensors.