 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8 Formats for Deep Learning
Sep 12, 2022
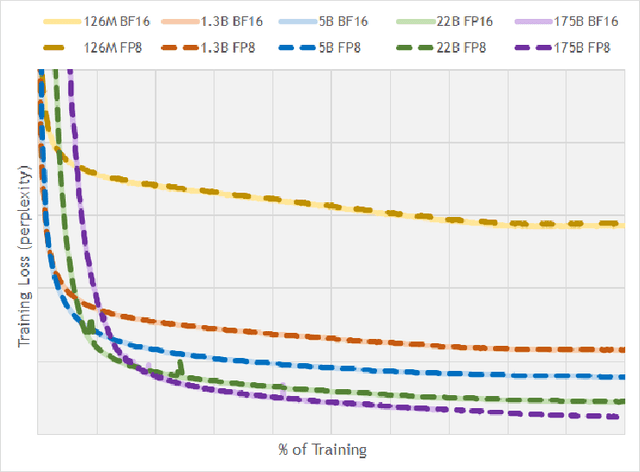
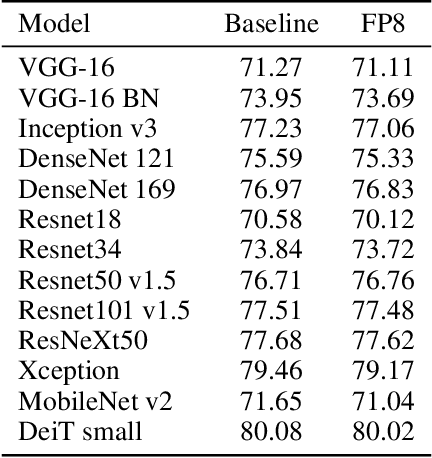
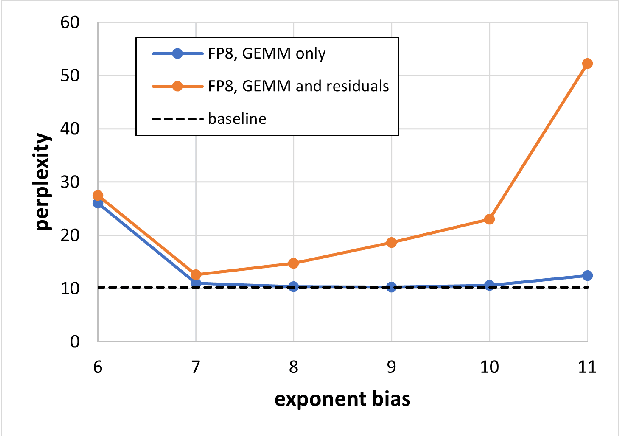
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
An Underexplored Dilemma between Confidence and Calibration in Quantized Neural Networks
Dec 02, 2021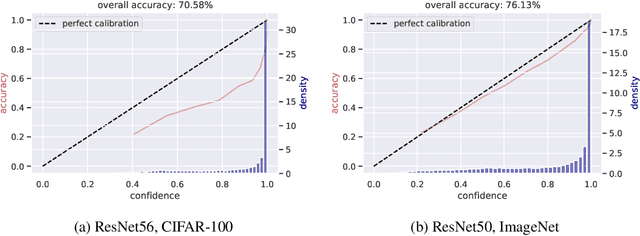
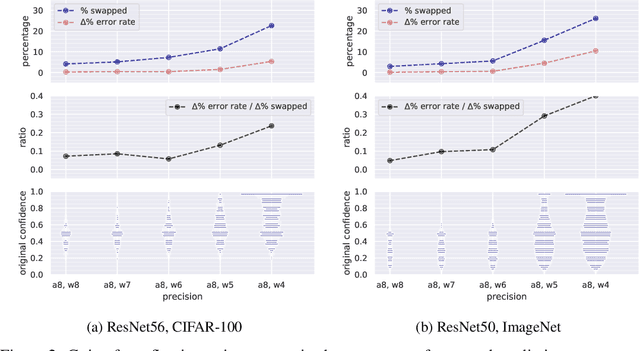
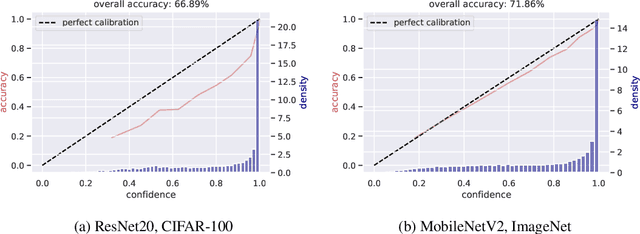
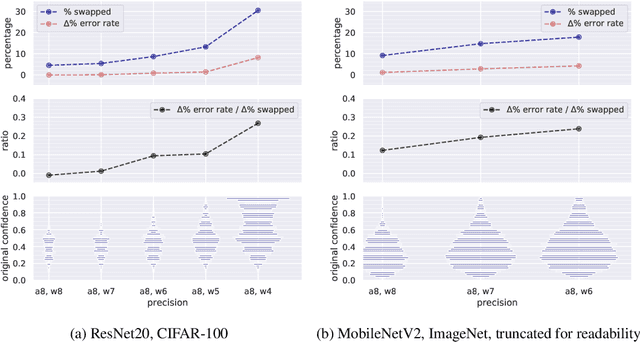
Modern convolutional neural networks (CNNs) are known to be overconfident in terms of their calibration on unseen input data. That is to say, they are more confident than they are accurate. This is undesirable if the probabilities predicted are to be used for downstream decision making. When considering accuracy, CNNs are also surprisingly robust to compression techniques, such as quantization, which aim to reduce computational and memory costs. We show that this robustness can be partially explained by the calibration behavior of modern CNNs, and may be improved with overconfidence. This is due to an intuitive result: low confidence predictions are more likely to change post-quantization, whilst being less accurate. High confidence predictions will be more accurate, but more difficult to change. Thus, a minimal drop in post-quantization accuracy is incurred. This presents a potential conflict in neural network design: worse calibration from overconfidence may lead to better robustness to quantization. We perform experiments applying post-training quantization to a variety of CNNs, on the CIFAR-100 and ImageNet datasets.
Stochastic-Shield: A Probabilistic Approach Towards Training-Free Adversarial Defense in Quantized CNNs
May 13, 2021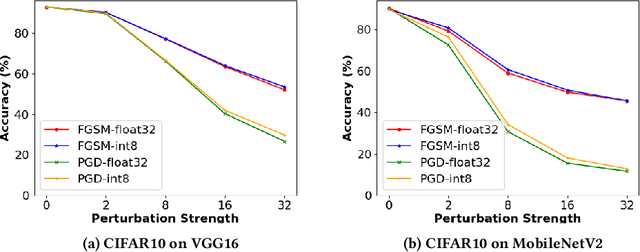
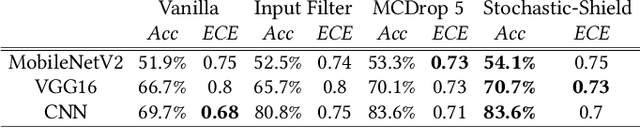
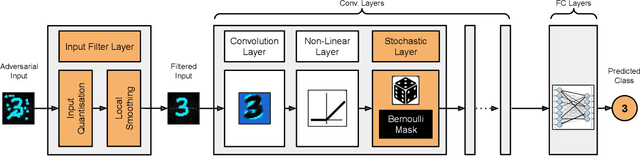
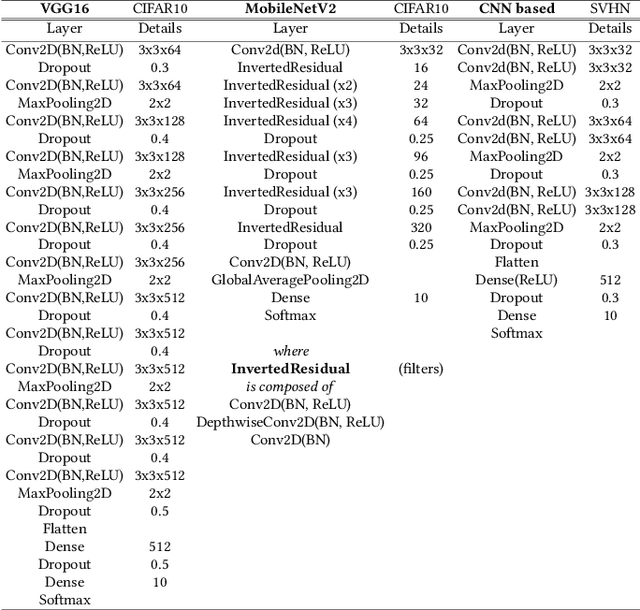
Quantized neural networks (NN) are the common standard to efficiently deploy deep learning models on tiny hardware platforms. However, we notice that quantized NNs are as vulnerable to adversarial attacks as the full-precision models. With the proliferation of neural networks on small devices that we carry or surround us, there is a need for efficient models without sacrificing trust in the prediction in presence of malign perturbations. Current mitigation approaches often need adversarial training or are bypassed when the strength of adversarial examples is increased. In this work, we investigate how a probabilistic framework would assist in overcoming the aforementioned limitations for quantized deep learning models. We explore Stochastic-Shield: a flexible defense mechanism that leverages input filtering and a probabilistic deep learning approach materialized via Monte Carlo Dropout. We show that it is possible to jointly achieve efficiency and robustness by accurately enabling each module without the burden of re-retraining or ad hoc fine-tuning.
Quantization for Rapid Deployment of Deep Neural Networks
Oct 12, 2018
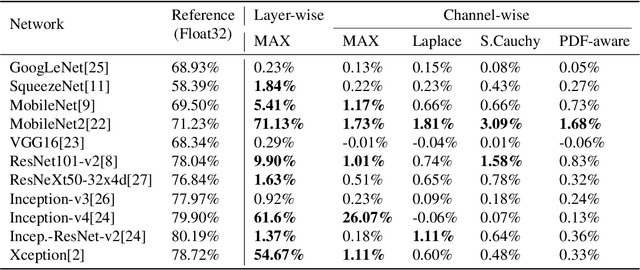
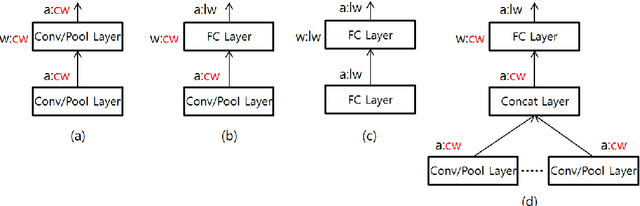

This paper aims at rapid deployment of the state-of-the-art deep neural networks (DNNs) to energy efficient accelerators without time-consuming fine tuning or the availability of the full datasets. Converting DNNs in full precision to limited precision is essential in taking advantage of the accelerators with reduced memory footprint and computation power. However, such a task is not trivial since it often requires the full training and validation datasets for profiling the network statistics and fine tuning the networks to recover the accuracy lost after quantization. To address these issues, we propose a simple method recognizing channel-level distribution to reduce the quantization-induced accuracy loss and minimize the required image samples for profiling. We evaluated our method on eleven networks trained on the ImageNet classification benchmark and a network trained on the Pascal VOC object detection benchmark. The results prove that the networks can be quantized into 8-bit integer precision without fine tuning.
Training Deep Neural Network in Limited Precision
Oct 12, 2018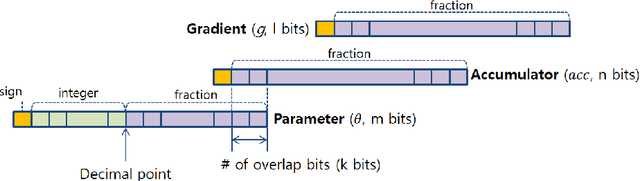
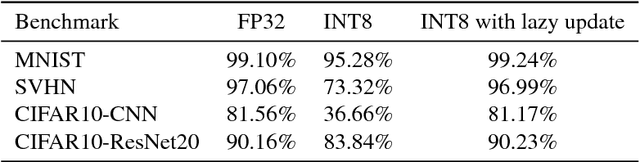
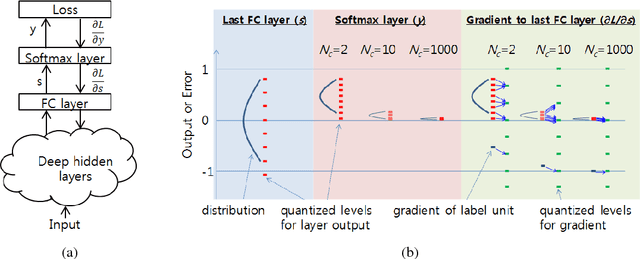
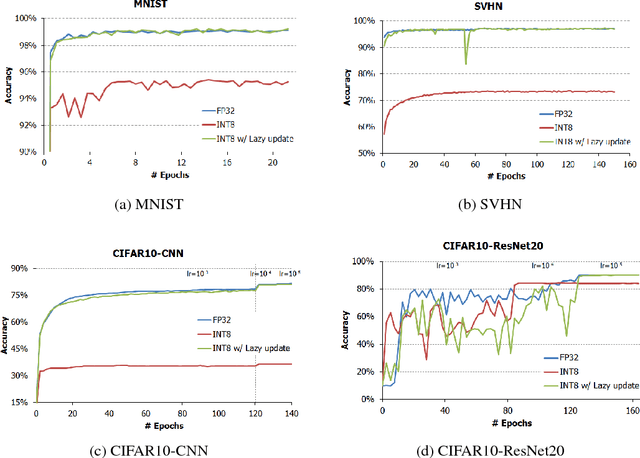
Energy and resource efficient training of DNNs will greatly extend the applications of deep learning. However, there are three major obstacles which mandate accurate calculation in high precision. In this paper, we tackle two of them related to the loss of gradients during parameter update and backpropagation through a softmax nonlinearity layer in low precision training. We implemented SGD with Kahan summation by employing an additional parameter to virtually extend the bit-width of the parameters for a reliable parameter update. We also proposed a simple guideline to help select the appropriate bit-width for the last FC layer followed by a softmax nonlinearity layer. It determines the lower bound of the required bit-width based on the class size of the dataset. Extensive experiments on various network architectures and benchmarks verifies the effectiveness of the proposed technique for low precision training.