 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Filling Curves is All You Need: Communication-Avoiding Matrix Multiplication Made Simple
Jan 22, 2026General Matrix Multiplication (GEMM) is the cornerstone of Deep Learning and HPC workloads; accordingly, academia and industry have heavily optimized this kernel. Modern platforms with matrix multiplication accelerators exhibit high FLOP/Byte machine balance, which makes implementing optimal matrix multiplication challenging. On modern CPU platforms with matrix engines, state-of-the-art vendor libraries tune input tensor layouts, parallelization schemes, and cache blocking to minimize data movement across the memory hierarchy and maximize throughput. However, the best settings for these parameters depend strongly on the target platform (number of cores, memory hierarchy, cache sizes) and on the shapes of the matrices, making exhaustive tuning infeasible; in practice this leads to performance "glass jaws". In this work we revisit space filling curves (SFC) to alleviate the problem of this cumbersome tuning. SFC convert multi-dimensional coordinates (e.g. 2D) into a single dimension (1D), keeping nearby points in the high-dimensional space close in the 1D order. We partition the Matrix Multiplication computation space using recent advancements in generalized SFC (Generalized Hilbert Curves), and we obtain platform-oblivious and shape-oblivious matrix-multiplication schemes that exhibit inherently high degree of data locality. Furthermore, we extend the SFC-based work partitioning to implement Communication-Avoiding (CA) algorithms that replicate the input tensors and provably minimize communication/data-movement on the critical path. The integration of CA-algorithms is seamless and yields compact code (~30 LOC), yet it achieves state-of-the-art results on multiple CPU platforms, outperforming vendor libraries by up to 2x(geometric-mean speedup) for a range of GEMM shapes.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
AUTOSPARSE: Towards Automated Sparse Training of Deep Neural Networks
Apr 14, 2023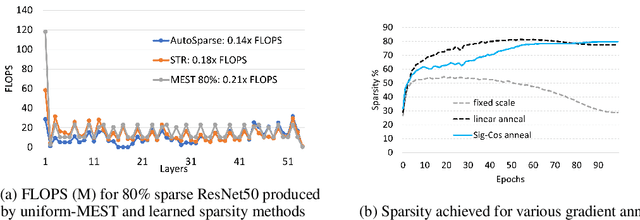
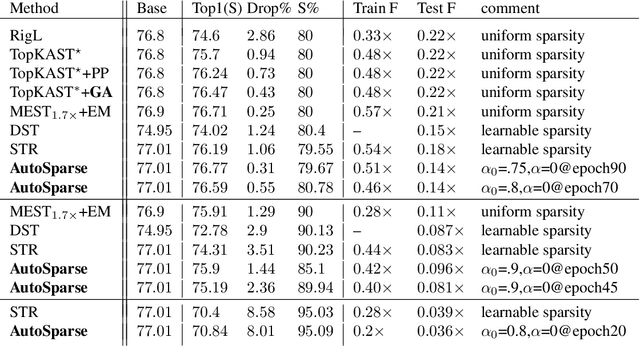

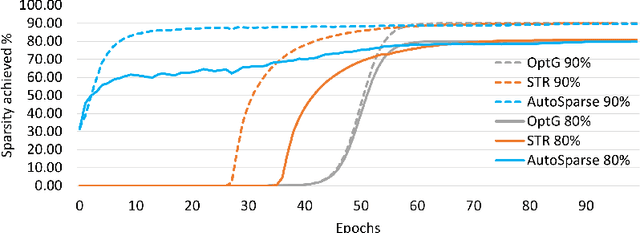
Sparse training is emerging as a promising avenue for reducing the computational cost of training neural networks. Several recent studies have proposed pruning methods using learnable thresholds to efficiently explore the non-uniform distribution of sparsity inherent within the models. In this paper, we propose Gradient Annealing (GA), where gradients of masked weights are scaled down in a non-linear manner. GA provides an elegant trade-off between sparsity and accuracy without the need for additional sparsity-inducing regularization. We integrated GA with the latest learnable pruning methods to create an automated sparse training algorithm called AutoSparse, which achieves better accuracy and/or training/inference FLOPS reduction than existing learnable pruning methods for sparse ResNet50 and MobileNetV1 on ImageNet-1K: AutoSparse achieves (2x, 7x) reduction in (training,inference) FLOPS for ResNet50 on ImageNet at 80% sparsity. Finally, AutoSparse outperforms sparse-to-sparse SotA method MEST (uniform sparsity) for 80% sparse ResNet50 with similar accuracy, where MEST uses 12% more training FLOPS and 50% more inference FLOPS.
FP8 Formats for Deep Learning
Sep 12, 2022
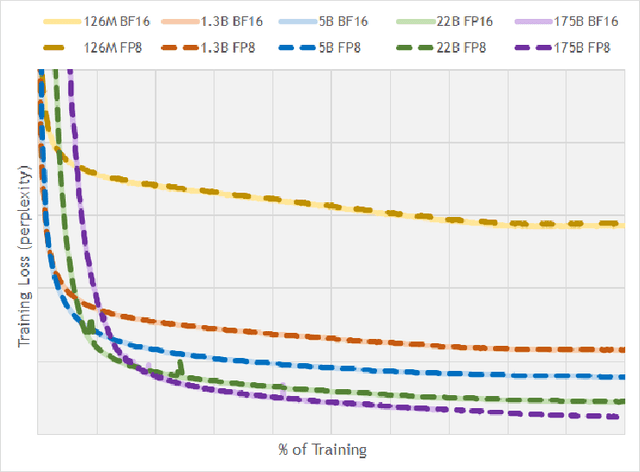
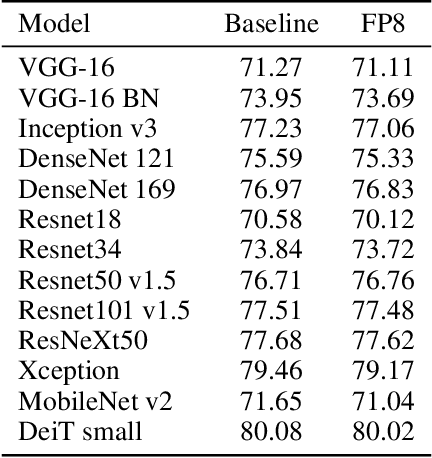
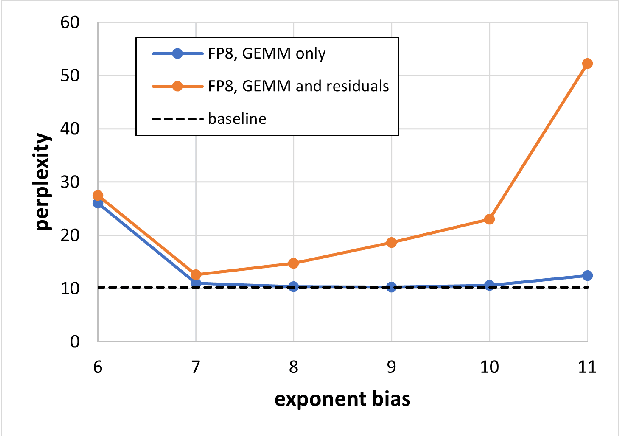
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
Systolic Computing on GPUs for Productive Performance
Oct 29, 2020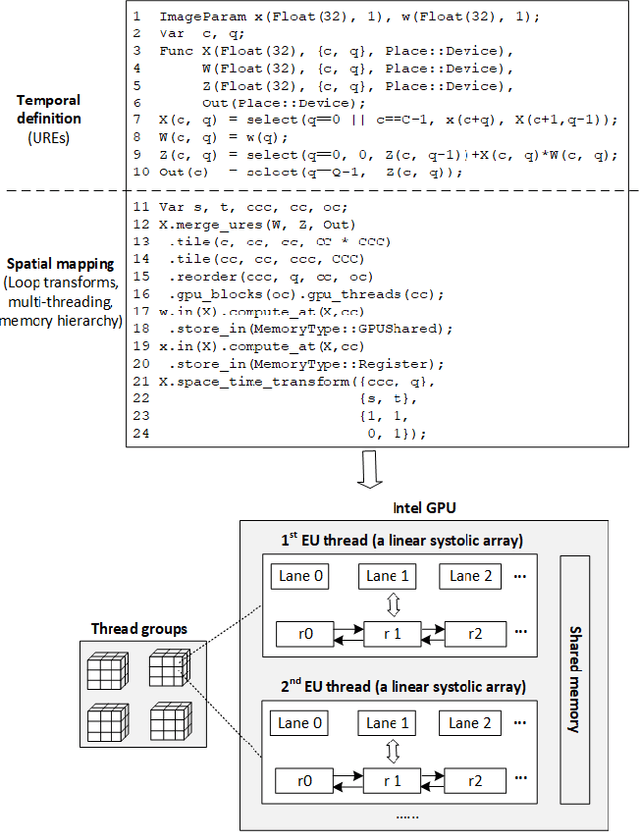
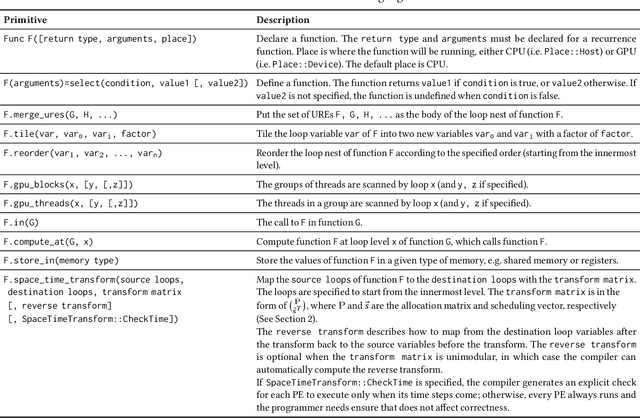
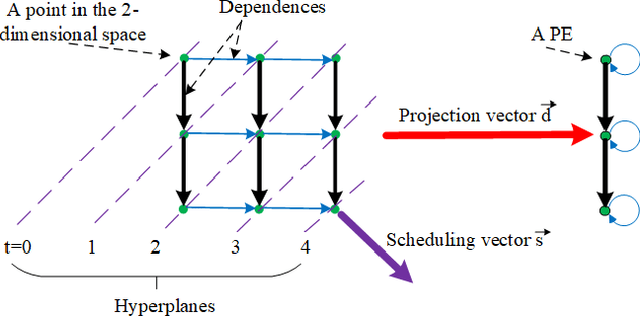
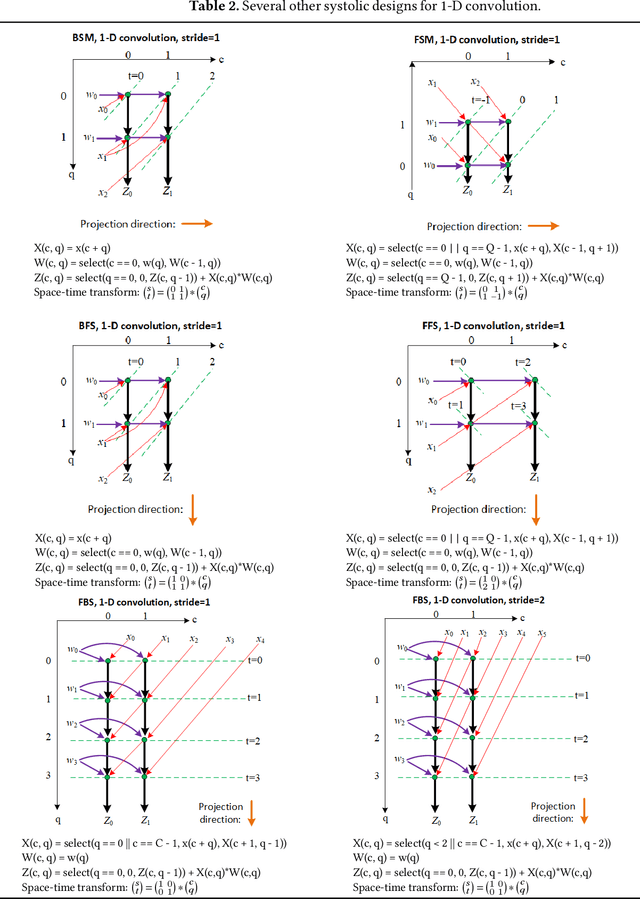
We propose a language and compiler to productively build high-performance {\it software systolic arrays} that run on GPUs. Based on a rigorous mathematical foundation (uniform recurrence equations and space-time transform), our language has a high abstraction level and covers a wide range of applications. A programmer {\it specifies} a projection of a dataflow compute onto a linear systolic array, while leaving the detailed implementation of the projection to a compiler; the compiler implements the specified projection and maps the linear systolic array to the SIMD execution units and vector registers of GPUs. In this way, both productivity and performance are achieved in the same time. This approach neatly combines loop transformations, data shuffling, and vector register allocation into a single framework. Meanwhile, many other optimizations can be applied as well; the compiler composes the optimizations together to generate efficient code. We implemented the approach on Intel GPUs. This is the first system that allows productive construction of systolic arrays on GPUs. We allow multiple projections, arbitrary projection directions and linear schedules, which can express most, if not all, systolic arrays in practice. Experiments with 1- and 2-D convolution on an Intel GEN9.5 GPU have demonstrated the generality of the approach, and its productivity in expressing various systolic designs for finding the best candidate. Although our systolic arrays are purely software running on generic SIMD hardware, compared with the GPU's specialized, hardware samplers that perform the same convolutions, some of our best designs are up to 59\% faster. Overall, this approach holds promise for productive high-performance computing on GPUs.
MISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020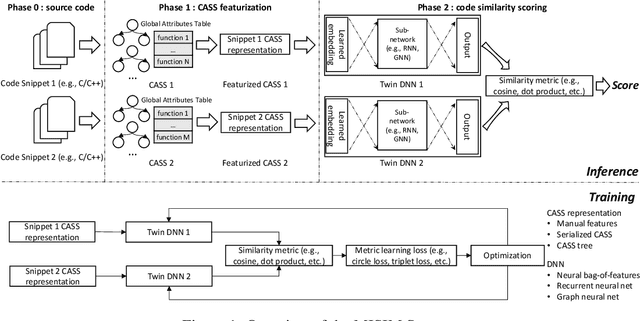
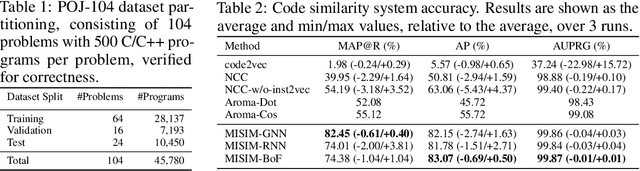
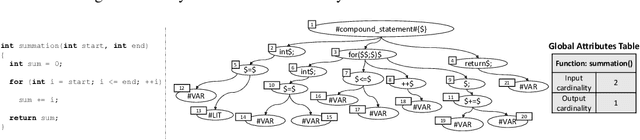
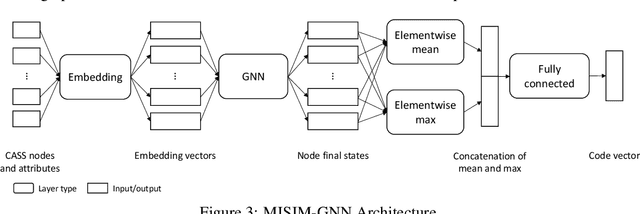
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
Context-Aware Parse Trees
Mar 24, 2020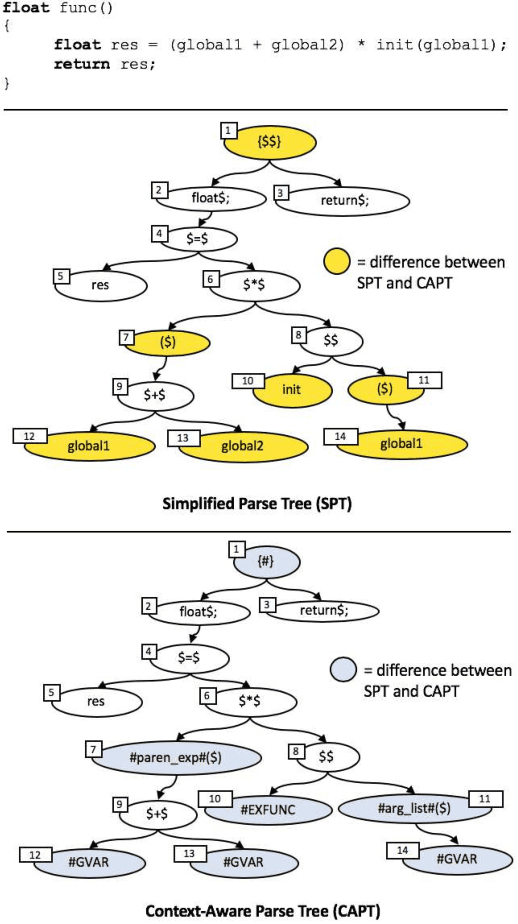
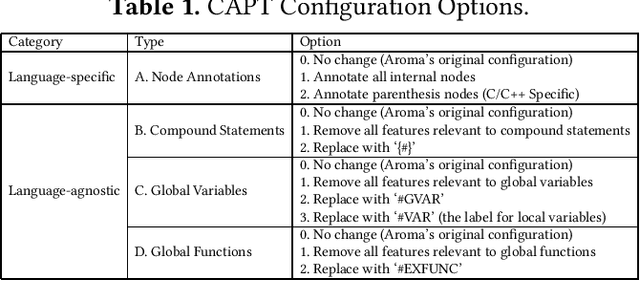
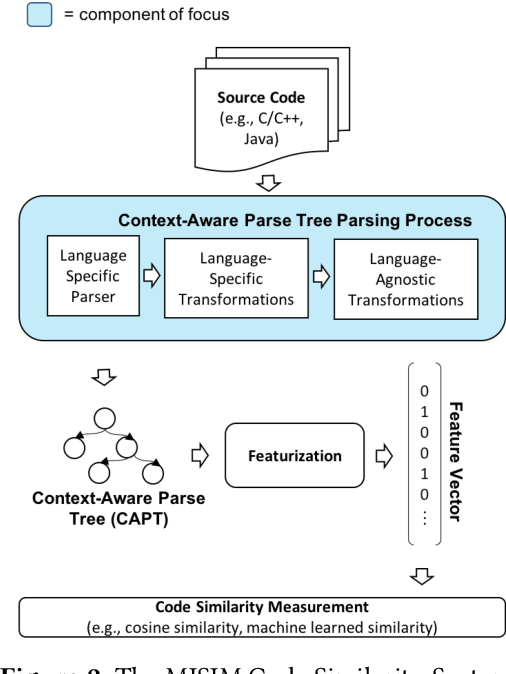
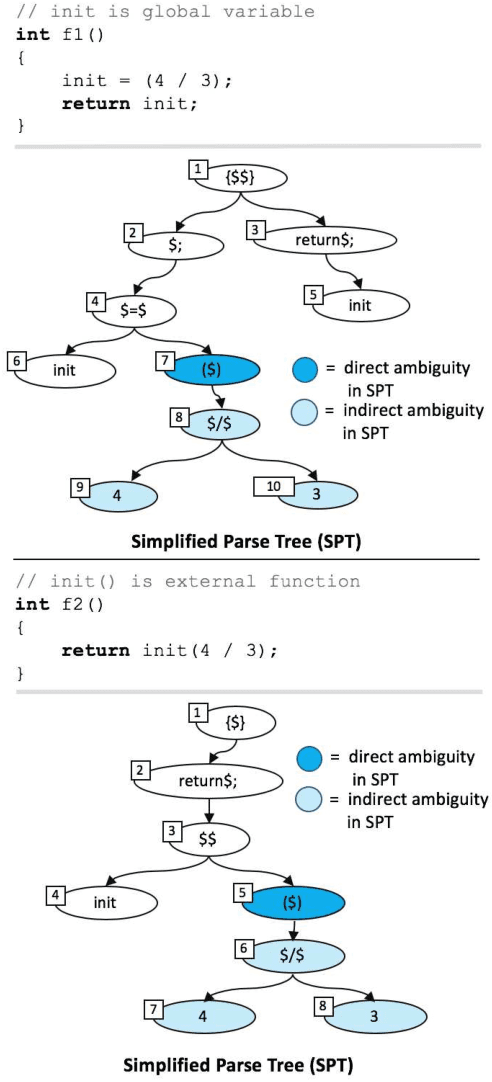
The simplified parse tree (SPT) presented in Aroma, a state-of-the-art code recommendation system, is a tree-structured representation used to infer code semantics by capturing program \emph{structure} rather than program \emph{syntax}. This is a departure from the classical abstract syntax tree, which is principally driven by programming language syntax. While we believe a semantics-driven representation is desirable, the specifics of an SPT's construction can impact its performance. We analyze these nuances and present a new tree structure, heavily influenced by Aroma's SPT, called a \emph{context-aware parse tree} (CAPT). CAPT enhances SPT by providing a richer level of semantic representation. Specifically, CAPT provides additional binding support for language-specific techniques for adding semantically-salient features, and language-agnostic techniques for removing syntactically-present but semantically-irrelevant features. Our research quantitatively demonstrates the value of our proposed semantically-salient features, enabling a specific CAPT configuration to be 39\% more accurate than SPT across the 48,610 programs we analyzed.
K-TanH: Hardware Efficient Activations For Deep Learning
Oct 21, 2019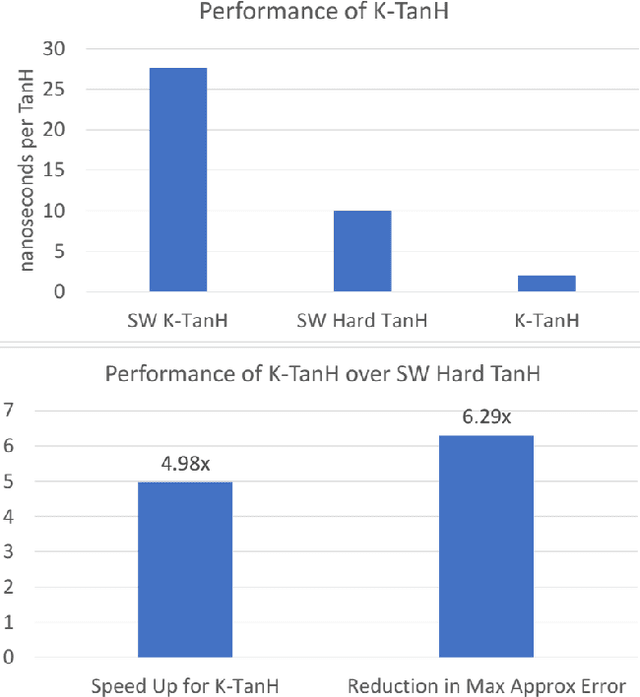
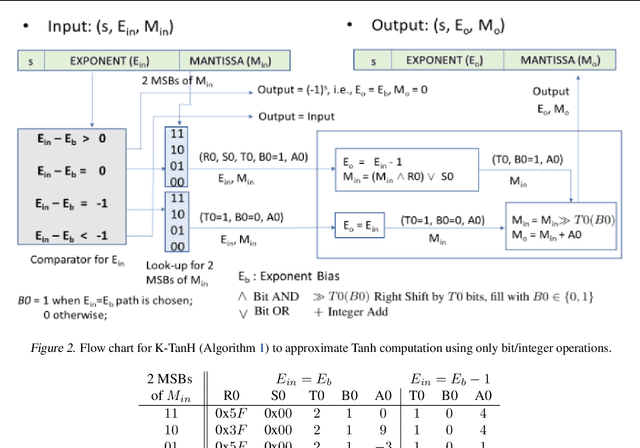

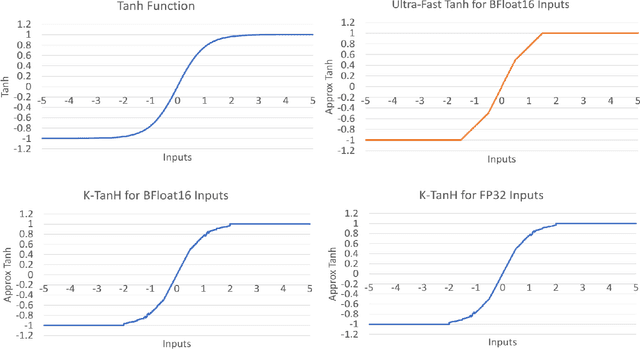
We propose K-TanH, a novel, highly accurate, hardware efficient approximation of popular activation function Tanh for Deep Learning. K-TanH consists of a sequence of parameterized bit/integer operations, such as, masking, shift and add/subtract (no floating point operation needed) where parameters are stored in a very small look-up table (bit-masking step can be eliminated). The design of K-TanH is flexible enough to deal with multiple numerical formats, such as, FP32 and BFloat16. High quality approximations to other activation functions, e.g., Swish and GELU, can be derived from K-TanH. We provide RTL design for K-TanH to demonstrate its area/power/performance efficacy. It is more accurate than existing piecewise approximations for Tanh. For example, K-TanH achieves $\sim 5\times$ speed up and $> 6\times$ reduction in maximum approximation error over software implementation of Hard TanH. Experimental results for low-precision BFloat16 training of language translation model GNMT on WMT16 data sets with approximate Tanh and Sigmoid obtained via K-TanH achieve similar accuracy and convergence as training with exact Tanh and Sigmoid.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019

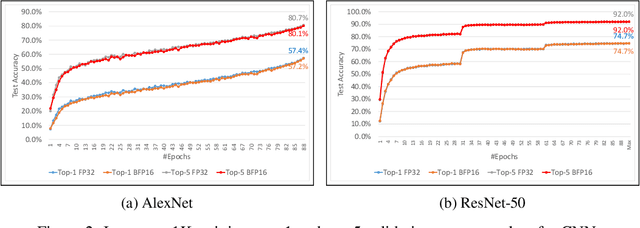

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.